# 链表
『 链表 Linked List 』也是一种 "线性表" 结构。,但不同于数组,链表中的元素在内存中并不是连续放置的。
链表由一组连续的节点 node 构成,每个节点包含一个元素和一个指向下一个元素的指针
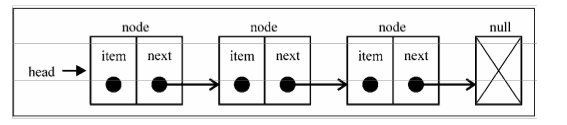
# 单链表
上图就是一个单链表。其中有两个结点是比较特殊的,它们分别是第一个结点和最后一个结点。我们习惯性地把第一个结点叫作『 头结点 Head Node 』,把最后一个结点叫作『 尾结点 Tail Node 』。
- 头结点指向链表中的第一个节点。
- 尾结点上
next指针指向一个空地址 Null,表示这是链表上最后一个结点。
相对于传统的数组,链表的一个好处在于,因为链表的存储空间本身就不是连续的。链表添加或移除元素的时候不需要移动其他元素。
从下图中我们可以看出,针对链表的插入和删除操作,我们只需要考虑相邻结点的指针改变,所以对应的时间复杂度是 。
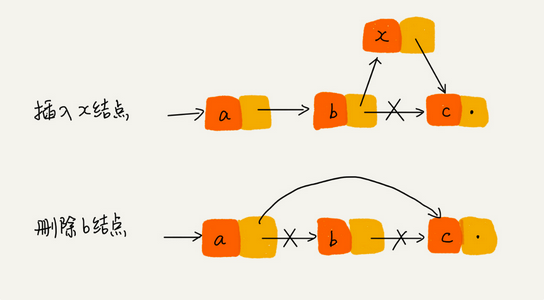
但是要想访问链表中间的一个元素,需要从表头开始迭代列表直到找到所需的元素。
# 循环链表
循环链表的尾结点指针是指向链表的头结点。
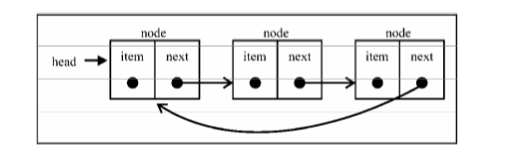
循环链表的优点是从链尾到链头比较方便。
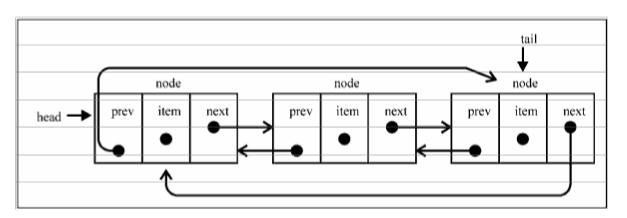
# 双向链表
双向链表它支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。

从结构上来看,双向链表可以支持 时间复杂度的情况下找到前驱结点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
🌰 举例来讲,在删除操作中,一般有如下两种情况:
- 删除结点中“值等于某个给定值”的结点;
- 删除给定指针指向的结点。
对于第一种情况,不管是单链表还是双向链表,为了查找到值等于给定值的结点,都需要从头结点开始依次遍历对比,直到找到值等于给定值的结点。时间复杂度为
对于第二种情况,我们已经找到了要删除的结点,但是删除某个结点 q 需要知道其前驱结点,而单链表并不支持直接获取前驱结点。所以,为了找到前驱结点,我们还是要从头结点开始遍历链表。时间复杂度为 。
但对于双向链表来说,结点已经保存了前驱结点的指针,不需要像单链表那样遍历。所以,针对第二种情况,双向链表的时间复杂度为 。
# 双向循环链表
结合一下双向链表和循环链表就是『 双向循环链表 』
双向循环链表有指向 head 元素的 tail.next 和指向 tail 元素的 head.prev。