# 动态规划
# 初识动态规划
下面 👇 先通过两个非常经典的动态规划问题模型,向你展示我们为什么需要动态规划,以及动态规划解题方法是如何演化出来的。
# 0-1 背包问题
对于一组不同重量、不可分割的物品,我们需要选择一些装入背包,在不超过背包最大重量限制的前提下,背包中物品「 总重量 」的最大值是多少呢?
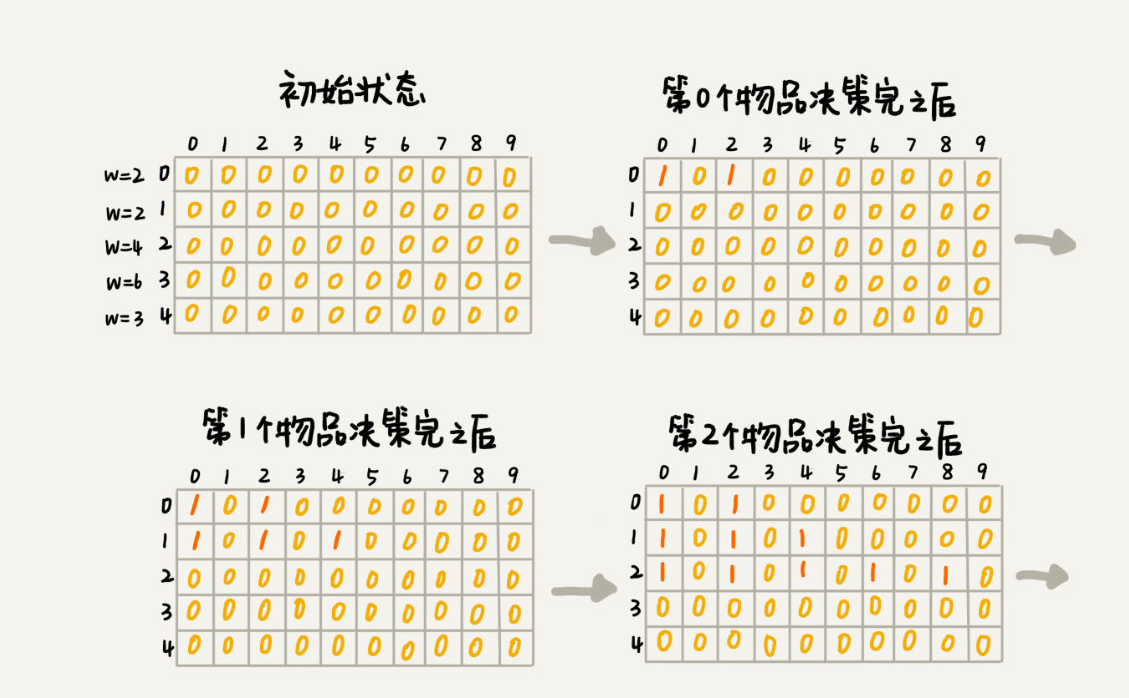
我们假设背包的最大承载重量是 9。我们有 5 个不同的物品,每个物品的重量分别是 2,2,4,6,3。
我们把整个求解过程分为 n 个阶段,每个阶段会决策一个物品是否放到背包中。每个物品决策(放入或者不放入背包)完之后,背包中的物品的重量会有多种情况,也就是说,会达到多种不同的状态。
每一层不同状态的个数都不会超过 w 个 ( w 表示背包的承载重量 )
我们用一个二维数组 states[n][w+1],来记录每层可以达到的不同状态。
第 0 个( 下标从 0 开始编号 )物品的重量是 2 要么装入背包,要么不装入背包,决策完之后,会对应背包的两种状态,背包中物品的总重量是 0 或者 2。我们用 states[0][0]=true 和 states[0][2]=true 来表示这两种状态。
第 1 个物品的重量也是 2,基于之前的背包状态,在这个物品决策完之后,不同的状态有 3 个,背包中物品总重量分别是 0 ( 0 + 0 ),2 ( 0 + 2 or 2 + 0 ),4 ( 2 + 2 )。我们用 states[1][0]=true,states[1][2]=true,states[1][4]=true 来表示这三种状态。
以此类推,直到考察完所有的物品后,整个 states 状态数组就都计算好了。

// weight:物品重量,n:物品个数,w:背包可承载重量
public int knapsack(int[] weight, int n, int w) {
boolean[][] states = new boolean[n][w+1]; // 默认值 false
// 第一行的数据要特殊处理
states[0][0] = true;
if (weight[0] <= w) {
states[0][weight[0]] = true;
}
// 动态规划状态转移
for (int i = 1; i < n; ++i) {
// 不把第 i 个物品放入背包
for (int j = 0; j <= w; ++j) {
if (states[i - 1][j] == true) states[i][j] = states[i - 1][j];
}
//把第i个物品放入背包
for (int j = 0; j <= w-weight[i]; ++j) {
if (states[i - 1][j] == true) states[i][j + weight[i]] = true;
}
}
// 输出结果
for (int i = w; i >= 0; --i) {
if (states[n - 1][i] == true) return i;
}
return 0;
}
这就是一种用动态规划解决问题的思路。我们把问题分解为多个阶段,每个阶段对应一个决策。我们记录每一个阶段可达的状态集合。然后通过当前阶段的状态集合,来推导下一个阶段的状态集合,动态地往前推进。
代码的时间复杂度非常好分析,耗时最多的部分就是代码中的两层 for 循环,所以时间复杂度是 。n 表示物品个数,w 表示背包可以承载的总重量。
# 0-1 背包问题 ( 升级版 )
我们刚刚讲的背包问题,只涉及背包重量和物品重量。我们现在引入物品价值这一变量。对于一组不同重量、不同价值、不可分割的物品,我们选择将某些物品装入背包,在满足背包最大重量限制的前提下,背包中可装入物品的「 总价值 」最大是多少呢?
把整个求解过程分为 n 个阶段,每个阶段会决策一个物品是否放到背包中。每个阶段决策完之后,背包中的物品的总重量以及总价值,会有多种情况,会达到多种不同的状态。
用一个二维数组 states[n][w+1],来记录每层可以达到的不同状态。不过这里数组存储的值不再是 boolean 类型的了,而是当前状态对应的最大总价值
public static int knapsack3(int[] weight, int[] value, int n, int w) {
int[][] states = new int[n][w+1];
// 初始化states
for (int i = 0; i < n; ++i) {
for (int j = 0; j < w+1; ++j) {
states[i][j] = -1;
}
}
// 第一行的数据要特殊处理
states[0][0] = 0;
if (weight[0] <= w) {
states[0][weight[0]] = value[0];
}
//动态规划,状态转移
for (int i = 1; i < n; ++i) {
// 不选择第i个物品
for (int j = 0; j <= w; ++j) {
if (states[i-1][j] >= 0) states[i][j] = states[i-1][j];
}
// 选择第i个物品
for (int j = 0; j <= w-weight[i]; ++j) {
if (states[i-1][j] >= 0) {
int v = states[i-1][j] + value[i];
if (v > states[i][j+weight[i]]) {
states[i][j+weight[i]] = v;
}
}
}
}
// 找出最大值
int maxvalue = -1;
for (int j = 0; j <= w; ++j) {
if (states[n-1][j] > maxvalue) maxvalue = states[n-1][j];
}
return maxvalue;
}
时间复杂度也是
# 动态规划理论
这一部分,主要讲动态规划的一些理论知识。学完这节内容,可以帮你解决这样几个问题:
- 什么样的问题可以用动态规划解决?、
- 解决动态规划问题的一般思考过程是什么样的?
- 贪心、分治、回溯、动态规划这四种算法思想又有什么区别和联系?
# 一个模型三个特征
「 一个模型 」指的是动态规划适合解决的问题的模型。我把这个模型定义为「 多阶段决策最优解模型 」
- 我们一般是用动态规划来解决「 最优问题 」。而解决问题的过程,需要经历多个「 决策阶段 」。每个决策阶段都对应着一组「 状态 」。然后我们寻找一组「 决策序列 」,经过这组决策序列,能够产生最终期望求解的「 最优值 」。
「 三个特征 」它们分别是:
- 最优子结构,指的是,问题的最优解包含子问题的最优解。反过来说就是,我们可以通过子问题的最优解,推导出问题的最优解。
- 无后效性,有两层含义,第一层含义是,在推导后面阶段的状态的时候,我们只关心前面阶段的状态值,不关心这个状态是怎么一步一步推导出来的。第二层含义是,某阶段状态一旦确定,就不受之后阶段的决策影响。
- 重复子问题,不同的决策序列,到达某个相同的阶段时,可能会产生重复的状态。
🌰 假设我们有一个 n 乘以 n 的矩阵 w[n][n]。矩阵存储的都是正整数。棋子起始位置在左上角,终止位置在右下角。我们将棋子从左上角移动到右下角。每次只能向右或者向下移动一位。从左上角到右下角,会有很多不同的路径可以走。我们把每条路径经过的数字加起来看作路径的长度。那从左上角移动到右下角的最短路径长度是多少呢?
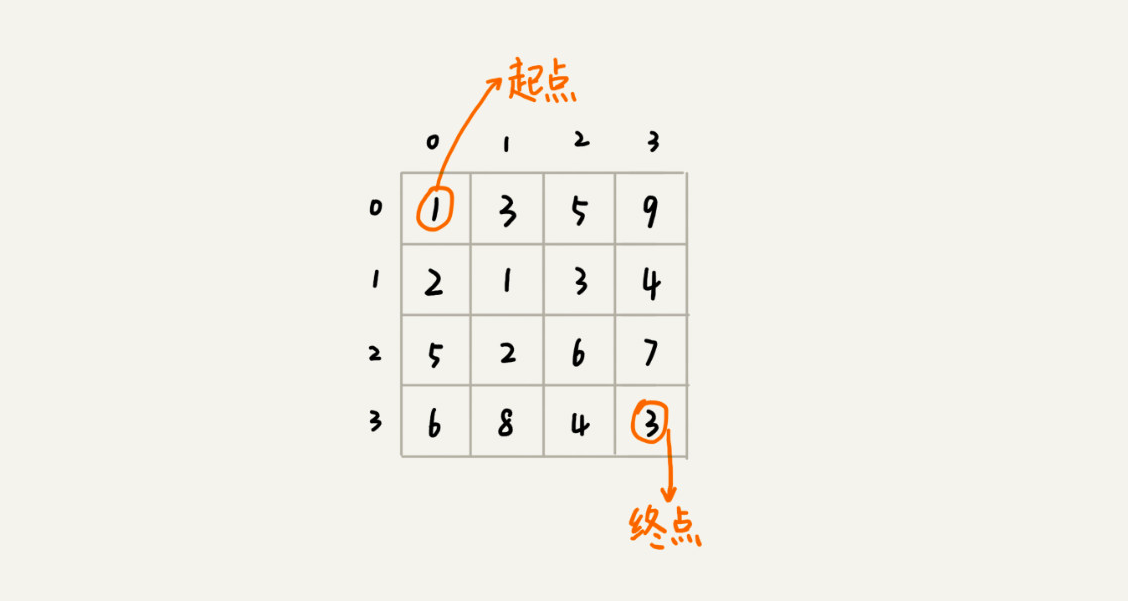
我们先看看,这个问题是否符合「 一个模型 」?
- 从
(0, 0)走到(n-1, n-1),总共要走2*(n-1)步,也就对应着2*(n-1)个阶段。每个阶段都有向右走或者向下走两种决策,并且每个阶段都会对应一个状态集合。 - 我们把状态定义为
min_dist(i, j),其中i表示行,j表示列。min_dist表达式的值表示从(0, 0)到达(i, j)的最短路径长度。 - 所以,这个问题是一个多阶段决策最优解问题,符合动态规划的模型。
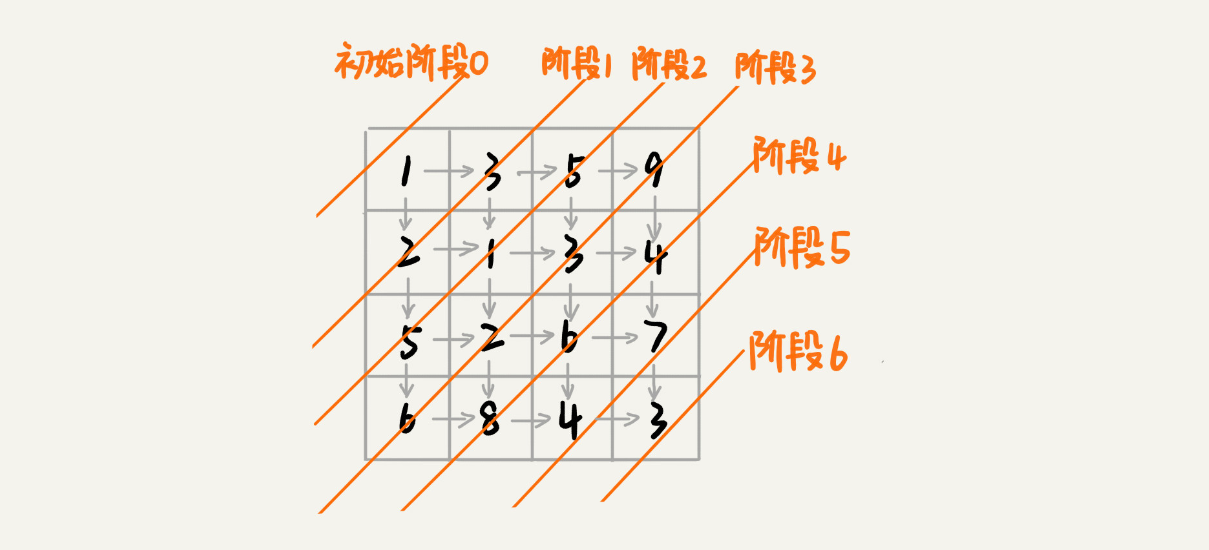
我们再来看,这个问题是否符合「 三个特征 」?
- 我们可以用回溯算法来解决这个问题。如果你自己写一下代码,画一下递归树,就会发现,递归树中有重复的节点。重复的节点表示,从左上角到对应的节点,有多种路线,这也能说明这个问题中存在「 重复子问题 」。
- 如果我们走到
(i, j)这个位置,我们只能通过(i-1, j)或(i, j-1)这两个位置移动过来,也就是说,我们想要计算(i, j)位置对应的状态,只需要关心(i-1, j),(i, j-1)两个位置对应的状态,并不关心棋子是通过什么样的路线到达这两个位置的。而且,我们仅仅允许往下和往右移动,不允许后退,所以,前面阶段的状态确定之后,不会被后面阶段的决策所改变,所以,这个问题符合 「 无后效性 」这一特征。 - 因为只有可能从
(i, j-1)或者(i-1, j)两个位置到达(i, j)。也就是说,到达(i, j)的最短路径要么经过(i, j-1),要么经过(i-1, j),而且到达(i, j)的最短路径肯定包含到达这两个位置的最短路径之一。换句话说就是,min_dist(i, j)可以通过min_dist(i, j-1)和min_dist(i-1, j)两个状态推导出来。这就说明,这个问题符合「 最优子结构 」
# 动态规划解题思路
解决动态规划问题,一般有两种思路。我把它们分别叫作「 状态转移表法 」和「 状态转移方程法 」
# 状态转移表法
一般能用动态规划解决的问题,都可以使用回溯算法的暴力搜索解决。所以:
- 当我们拿到问题的时候,我们可以先用简单的回溯算法解决,然后定义状态,每个状态表示一个节点,然后对应画出递归树。
- 从递归树中,我们很容易可以看出来,是否存在重复子问题,以及重复子问题是如何产生的。以此来寻找规律,看是否能用动态规划解决。
- 找到重复子问题之后,接下来,我们有两种处理思路:
- 第一种是直接用回溯加「 备忘录 」的方法,来避免重复子问题。从执行效率上来讲,这跟动态规划的解决思路没有差别。
- 第二种是使用动态规划的解决方法,状态转移表法。
下面讲解什么是『 状态转移表法 』:
- 我们先画出一个状态表。状态表一般都是二维的,所以你可以把它想象成二维数组。
- 其中,每个状态包含三个变量,行、列、数组值。
- 我们根据决策的先后过程,从前往后,根据递推关系,分阶段填充状态表中的每个状态。
- 最后,我们将这个递推填表的过程,翻译成代码,就是动态规划代码了。
🌰 现在,我们来看一下,如何套用这个状态转移表法,来解决之前那个「 矩阵最短路径 」的问题?
解决这个问题的「 回溯算法 」如下:
private int minDist = Integer.MAX_VALUE; // 全局变量或者成员变量
// 调用方式:minDistBacktracing(0, 0, 0, w, n);
public void minDistBT(int i, int j, int dist, int[][] w, int n) {
// 到达了n-1, n-1这个位置了,这里看着有点奇怪哈,你自己举个例子看下
if (i == n && j == n) {
if (dist < minDist) minDist = dist;
return;
}
if (i < n) { // 往下走,更新i=i+1, j=j
minDistBT(i + 1, j, dist+w[i][j], w, n);
}
if (j < n) { // 往右走,更新i=i, j=j+1
minDistBT(i, j+1, dist+w[i][j], w, n);
}
}
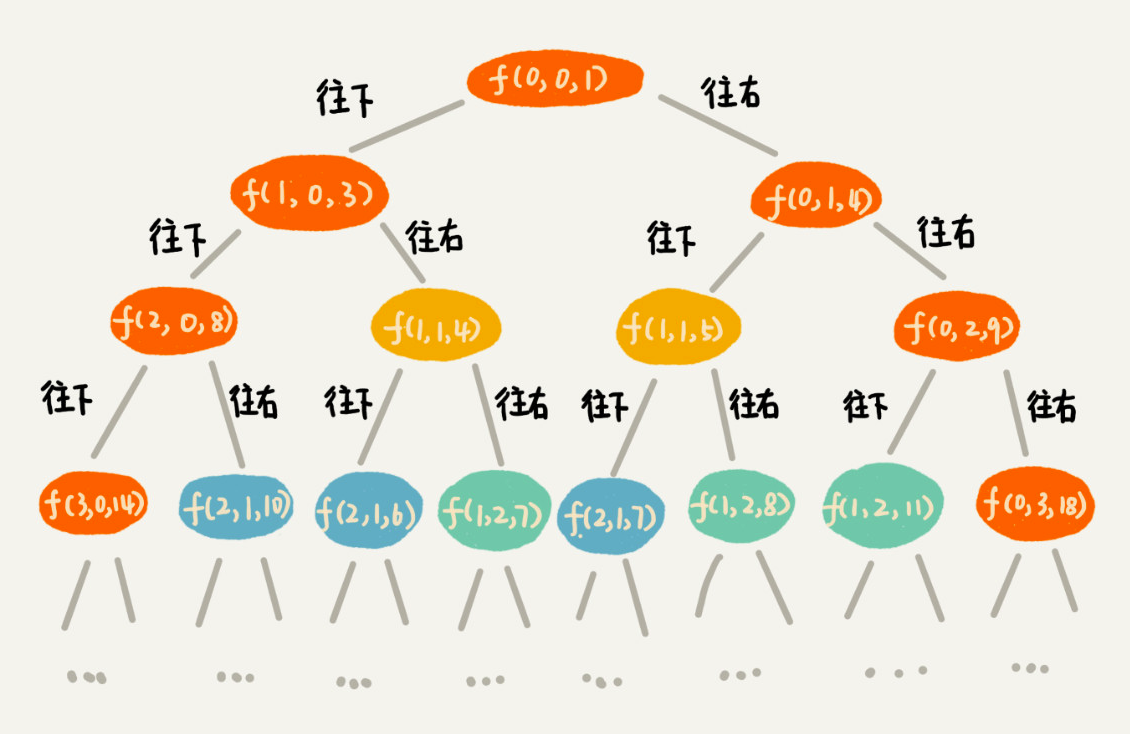
有了回溯代码之后,接下来,我们要画出递归树,以此来寻找重复子问题。
- 一个状态包含三个变量
(i, j, dist),其中i,j分别表示行和列,dist表示从起点到达(i, j)的路径长度。 - 我们看出,尽管
(i, j, dist)不存在重复的,但是(i, j)重复的有很多。对于(i, j)重复的节点,我们只需要选择dist最小的节点,继续递归求解,其他节点就可以舍弃了。
我们画出一个二维状态表,表中的行、列表示棋子所在的位置,表中的数值表示从起点到这个位置的最短路径。
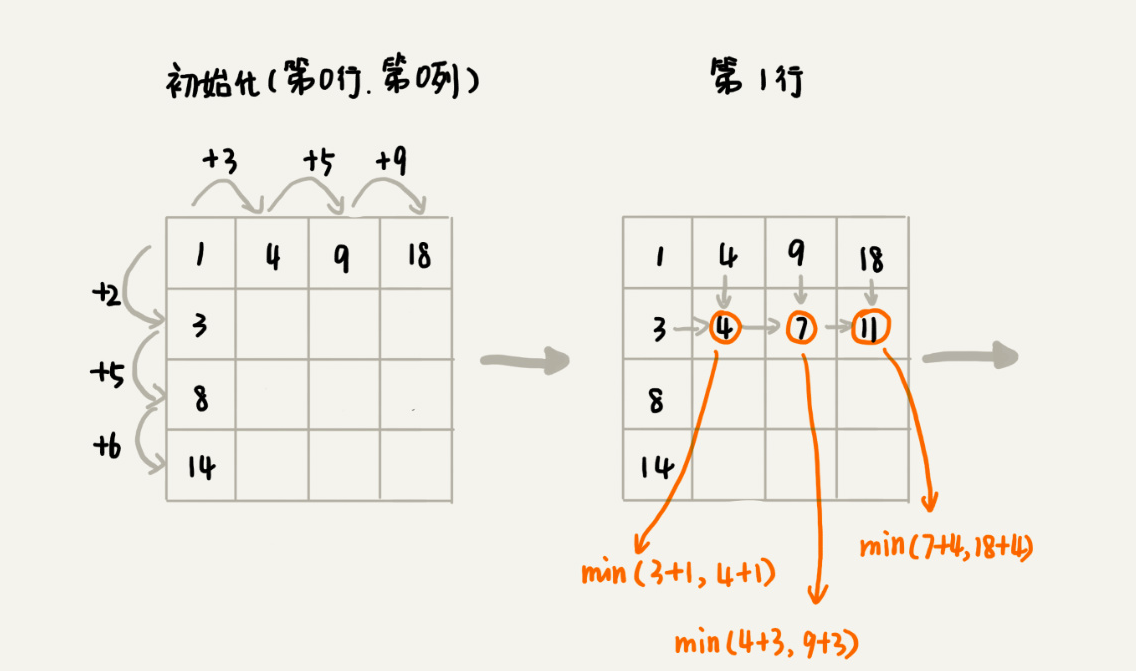
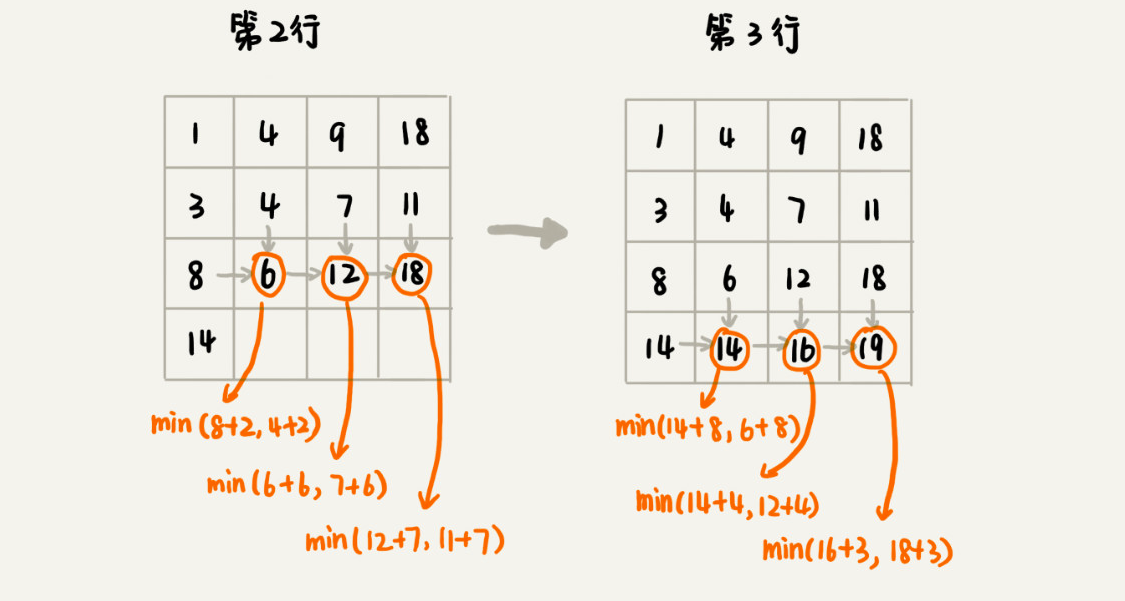
我们将上面的过程,翻译成代码:
public int minDistDP(int[][] matrix, int n) {
int[][] states = new int[n][n];
int sum = 0;
for (int j = 0; j < n; ++j) { // 初始化states的第一行数据
sum += matrix[0][j];
states[0][j] = sum;
}
sum = 0;
for (int i = 0; i < n; ++i) { // 初始化states的第一列数据
sum += matrix[i][0];
states[i][0] = sum;
}
for (int i = 1; i < n; ++i) {
for (int j = 1; j < n; ++j) {
states[i][j] =
matrix[i][j] + Math.min(states[i][j-1], states[i-1][j]);
}
}
return states[n-1][n-1];
}
尽管大部分状态表都是二维的,但是如果问题的状态比较复杂,需要很多变量来表示,那对应的状态表可能就是高维的,比如三维、四维。那这个时候,我们就不适合用状态转移表法来解决了。一方面是因为高维状态转移表不好画图表示,另一方面是因为人脑确实很不擅长思考高维的东西。
# 状态转移方程法
使用『 状态转移方程法 』需要分析,某个问题如何通过子问题来递归求解,也就是所谓的「 最优子结构 」。根据最优子结构,写出递归公式,也就是所谓的「 状态转移方程 」。
🌰 还是拿刚才的例子来举例。根据最优子结构,得到的状态转移方程如下:
min_dist(i, j) = w[i][j] + min(min_dist(i, j-1), min_dist(i-1, j))
状态转移方程是解决动态规划的关键。如果我们能写出状态转移方程,那动态规划问题基本上就解决一大半了,而翻译成代码非常简单。
下面我用递归加「 备忘录 」的方式,将状态转移方程翻译成来代码:
private int[][] matrix = {
{1,3,5,9},
{2,1,3,4},
{5,2,6,7},
{6,8,4,3}
};
private int n = 4;
private int[][] mem = new int[4][4];
public int minDist(int i, int j) {
if (i == 0 && j == 0) return matrix[0][0];
if (mem[i][j] > 0) return mem[i][j];
int minLeft = Integer.MAX_VALUE;
if (j-1 >= 0) {
minLeft = minDist(i, j-1);
}
int minUp = Integer.MAX_VALUE;
if (i-1 >= 0) {
minUp = minDist(i-1, j);
}
int currMinDist = matrix[i][j] + Math.min(minLeft, minUp);
mem[i][j] = currMinDist;
return currMinDist;
}
# 四种算法思想比较
我们将这四种算法思想分一下类,那贪心、回溯、动态规划可以归为一类,而分治单独可以作为一类,为什么这么说呢?
- 前三个算法解决问题的模型,都可以抽象成我们今天讲的那个「 多阶段决策最优解模型 」。
- 而分治算法解决的问题尽管大部分也是「 最优解问题 」,但是,大部分都不能抽象成多阶段决策模型。
回溯算法是个 “万金油”。基本上能用的动态规划、贪心解决的问题,我们都可以用回溯算法解决。回溯算法相当于穷举搜索。穷举所有的情况,然后对比得到最优解。不过,回溯算法的时间复杂度非常高,是指数级别的,只能用来解决小规模数据的问题。对于大规模数据的问题,用回溯算法解决的执行效率就很低了。
尽管动态规划比回溯算法高效,但是,并不是所有问题,都可以用动态规划来解决。能用动态规划解决的问题,需要满足三个特征,最优子结构、无后效性和重复子问题。在重复子问题这一点上,动态规划和分治算法的区分非常明显。分治算法要求分割成的子问题,不能有重复子问题,而动态规划正好相反。动态规划之所以高效,就是因为消除了回溯算法实现中存在大量的重复子问题。
贪心算法实际上是动态规划算法的一种特殊情况。它解决问题起来更加高效,代码实现也更加简洁。不过,它可以解决的问题也更加有限。贪心算法能解决的问题需要满足三个条件,最优子结构、无后效性和贪心选择性。
- 「 贪心选择性 」**的意思是,通过局部最优的选择,能产生全局的最优选择。**每一个阶段,我们都选择当前看起来最优的决策,所有阶段的决策完成之后,最终由这些局部最优解构成全局最优解。