# 描述性统计
# 基础概念
『 统计学 』是对研究对象的数据进行收集、整理、分析和研究,以显示其总体的特征和规律性的科学。
# 变量 & 数据
『 试验单位 experimental unit 』作为数据来源的研究对象。
- 🌰 想要研究学校中的男女生比例,"试验单位" 是每个学生。
『 变量 variable 』是试验单位身上的特性 characteristic,每个试验单位的变量值可能是不同的。
- 🌰 研究一家店的经营情况,每年的 "销售额","开支","净利润" 都可以作为变量。每一年这家店的这些变量的值都是变化的。
- 在做研究时,从试验单位身上具体记录下来的变量值,称为『 测量值 measurement 』,也就是所要分析的『 数据 data 』。
- 获得一个测量值的过程, 称为『 试验 experiment 』
对试验单位进行测量时:
- 只测量一个变量,获得的数据称为『 一元变量数据 Univariate Data 』
- 测量两个变量,获得的数据称为『 二元变量数据 Bivariate Data 』
- 测量多个变量,获得的数据称为『 多元变量数据 Multivariate Data 』
🌰 例子:
下表中记录 5 个学生的相关信息:
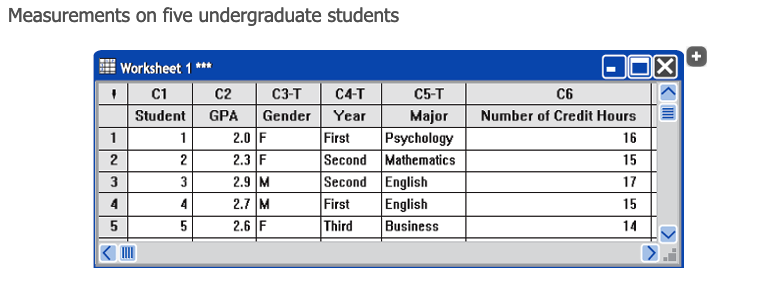
- 『 试验单位 』是每一个学生;
- 『 变量 』分别是 "GPA","Gender","Year","Major","Number of Credit Hours";
- 从每个学生身上测量了 5 个变量的值,所以获得的是『 Multivariate Data 』
# 总体 & 样本
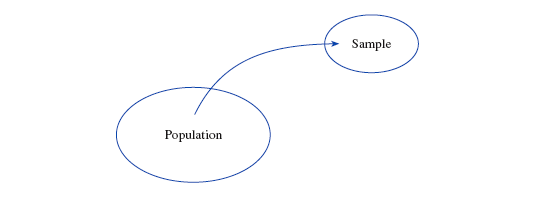
『 总体 population 』是我们感兴趣的研究对象全体。
- 它是由客观存在的、具有某种共同性质的许多个体所构成的整体。
- 构成总体的个体称为『 总体单位 Unit of Population 』。
因为调查收集一个总体的数据往往很难,所以通常只会随机地选出总体中一部分的个体进行调查。
🌰 例子:
调查一个学校中所有学生的每月花费:
- ❌ 基本上不可能调查完所有的学生。因为学生数量非常多,而且有的学生请假回家了,有的学生去实习了,有的学生去国外交换了。
『 样本 sample 』是总体中的一个子集。
- 构成样本的个体称为『 样本单位 Unit of Sample 』。
一个好的样本必须具备两种特性:
- 随机性 Randomness: 样本中的每一个个体都是随机从总体中抽出的。
- 代表性 Representativeness: 样本中个体的组成准确地反映出总体中个体的组成结构。
🌰 例子:
对于 "调查一个学校中所有学生的每月花费" 这个问题。可以进行抽样,但是样本必须保证 "随机性" 和 "代表性":
- ❌ "从计算机系随机选出 100 人调查",其他专业的学生没有机会被选上。
- ❌ "从食堂里随机选 100 人调查",很多人根本不去食堂吃饭,还有的人根本就不在学校,他们就没有机会被选上。
- ✅ 从学校数据库中找出 "全体学生名单",随机地选出 100 人。
# 描述性统计 & 推断统计
『 描述性统计 descriptive statistics 』: consists of procedures used to summarize and describe the important characteristics of a set of measurements.
🌰 记录一个工厂过去一年中二氧化碳的每日排放量;
进行 "描述性统计" 的基本步骤:
『 推断统计 inferential statistics 』: consists of procedures used to make inferences about population characteristics from information contained in a sample.
🌰 利用一个湖中不同位置采集的水样本, 去推断出整体湖水的性质;
进行 "推断统计" 的基本步骤:
- 确定想要回答的问题,以及识别出总体:
- 总体需要由与问题最相关的 "试验单元" 身上的 "测量值" 组成。也称为『 Population of Interest 』
- 🌰 假如问题是 "总统大选中谁会在选举日获得最多票"。总体是 "所有选票",而不是 "所有选民"。
- 确定选取样本的方法:
- 这一步也称为『 design of the experiment 』或者『 sampling procedure 』
- 需要关心的点是,选取出的样本是否具有 "随机性" 和 "代表性",样本需要有多大才能回答出 Step 1 设定的问题,以及尽可能花最少的时间和金钱。
- 🌰 例如,魁北克省的选票情况能否代表全加拿大的情况?如何选出可以代表全加拿大选票情况的样本?需要选出多少张?
- 选出样本,并且对样本进行分析:
- 选出样本之后,需要用恰当的分析方法去将样本数据中包含的信息找出来。
- 通过分析结果,对总体进行推断:
- 可以有很多种方法去进行推断。根据问题的不同,数据类型的不同,样本大小的不同,需要选出来最合适的方法。
- 确认推断结果的可靠度:
- 因为搜集来的样本只是总体中的一部分,通过由它计算来的结果去分析总体的特性是会有误差的。
- 需要确定这种误差大概有多少,是否可以相信推断结果,并拿它去回答 Step 1 设定的问题。
# 数据分类
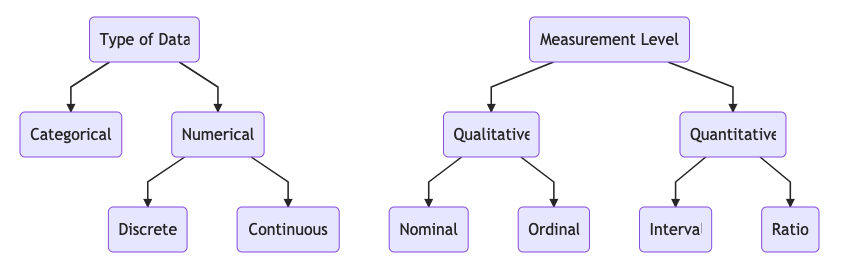
有两种方式对数据进行分类:
- 『 数据类型 Type of Data 』
- 『 度量水平 Meaurement Level 』
# 数据类型
数据类型分为两种:
『 分类数据 Categorical Data 』用类别 categories or groups 进行表示的数据:
- 🌰 性别,民族,品牌,季节,颜色,Yes / No。
- 🌰 调查学校中学生是否有车,根据回答可以将学生分为 Yes 或者 No 两组。
『 数值数据 Numerical Data 』可以用数值进行量化表示的数据。更具体又分为:
- 『 离散数据 Discrete Data 』有限的,可数的数据:
- 🌰 医院里一天出生的婴儿数量,手机每天的销售量,每个国民的收入。
- 『 连续数据 Continuous Data 』无限的,不可数的,每时每刻都在连续地变化的数据。
- 🌰 行驶中的汽车到目的地的距离,人的身高,体重 ( 每时每刻都在变化 )
- 🌰 以秒为单位计算的时间是 "离散数据",但是现实中的时间没有一个最小刻度单位,是连续的,不可数的,所以是 "连续数据"。
分类数据?or 数值数据?
有很多分类数据是用 "数值" 来表示的。
- 🌰 例如,"商品 ID"
当看到一个变量的值是数值时,你可能一下子不能准确判断它到底是 "分类数据" 还是 "数值数据"。
最简单的一个判断方法是,计算出这个变量的 "平均数",然后看它是否有意义。
计算出 "商品 ID" 的平均数,没有任何意义,不代表任何东西,所以它是 "分类数据"。
# 度量水平
根据度量水平,数据可以分为:
『 定性数据 Qualitative Data 』用类别进行表示的数据。又可以分为:
- 『 定类数据 Nominal Data 』类别之间没有顺序关系。
- 🌰 男女,品牌,血型,颜色,地区,民族;
- 『 定序 ( 顺序 ) 数据 Ordinal Data 』类别之间有顺序关系。
- 🌰 学历:小学,初中,高中,大学,研究生。
- 🌰 喜欢的程度:厌恶,不喜欢,没感觉,喜欢,非常喜欢。
『 定量数据 Quantitative Data 』可以用数值进行量化表示的数据,数值之间是有大小顺序的。又可以分为:
- 『 定距 ( 区间 ) 尺度 Interval Data 』数值之间具有一定的间隔,这个间隔是等距的。不具有绝对的 点。数值之间只能进行加减运算,不能进行乘除运算。
- 🌰 00:00 并不代表最小的时间。不可以说 10:00 是 00:00 的十倍,只能说比 00:00 晚 10 个小时。
- 🌰 摄氏温度:-100°C,0°C,100°C。0°C 并不是最小的温度。只能说 100°C 比 0°C 高 100 度。
- 『 定比尺度 Ratio Data 』具有绝对的 点。数值之间既可以进行加减运算,也可以进行乘除运算。
- 🌰 小王工资 2000 元,小红工资 1000 元。小王比小红多挣 1000 元,小王是小红工资的 2 倍。
- 🌰 开尔文温度:0K 称为绝对零度,是最小的温度,等于 -273.15°C。这个温度下物体的分子内能为 0。
# 描述性统计
在收集到了数据集之后, 我们需要一些方法, 去整理和描述这些数据.
# 用 "图表" 描述 Categorical 数据
# 频数 & 相对频率
在描述 Categorical 数据时, 我们认为每一个测量值都能够落入一个或一组类别:
- 对于给定的类别,落入这个类别的测量值个数,称为『 频数 frequency 』
- 对于给定的类别,频数相对于全部测量值的占比,称为『 相对频率 relative frequency 』
- 对于给定的类别,相对频率 x 100% 等于落入这个类别的观测值,占全部观测值中的『 百分比 percentage 』

- The sum of the "Frequencies" is always ( 所有观测值的数量 )
- The sum of the "Relative Frequencies" is always
- The sum of the "Percentages" is always
# 条形图 Bar Chart & 饼图 Pie Chart
在收集来『 原始数据 raw data 』之后,我们可以把数据整理成一个『 统计表 statistical table 』
再进一步,可以用适当的图形去表示数据。常用的有:
- 条形图 Bar Chart: 表示出每一类别的频数, 或相对频率;
- 饼图 Pie Chart: 表示出类别的频数在整体中的占比;
🌰 例子:
研究人员收集了自 1977 年以来, 全世界的 45 起与能源相关的死亡事故的数据. 从中将 "死亡原因" 作为变量将 45 起事故数据分成了 6 类.
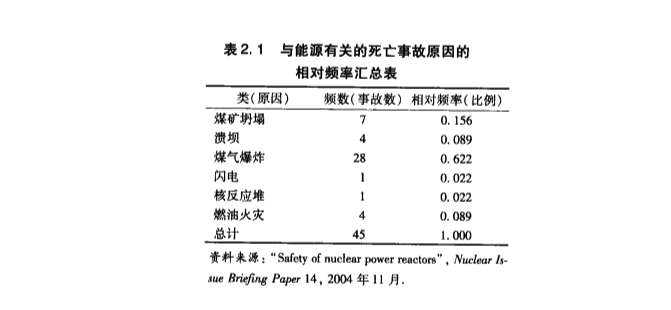
上表 👆 汇总出了每类原因的『 频数 』和『 相对频率 』
下面 👇 分别用『 条形图 』和『 饼图 』来描述了这份数据:

# 用 "图表" 描述 Numerical 数据
# 条形图 Bar Chart & 饼图 Pie Chart
很多的数值数据在收集时,本身就具有类别。
- 🌰 调查中国不同城市的平均收入。收入是 Numberical 数据,但是将 "城市" 作为类别。
🌰 例子:
下表 👇 展示了 2015 年加拿大销量前 10 的汽车型号和具体销售量。
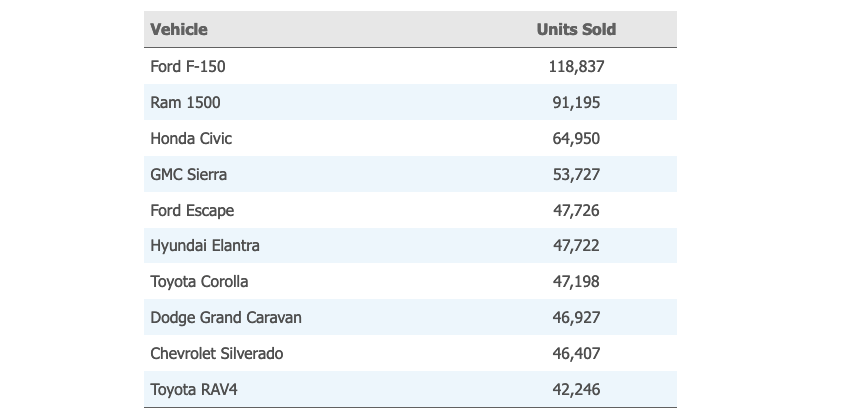
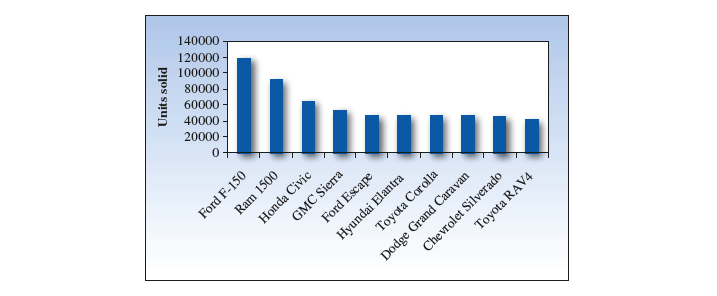
可以用『 条形图 Bar Chart 』和『 饼图 Pie Chart 』来表示:
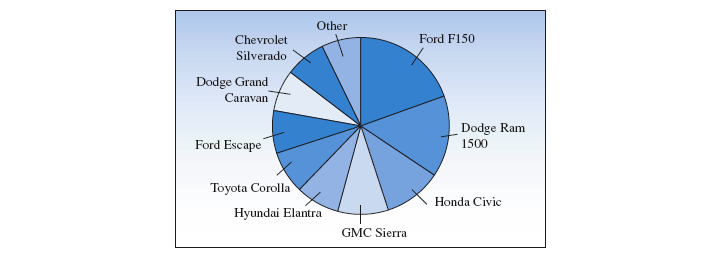
# 点图 Dot Plot
有很多数值数据很难将其归入某种类别。『 点图 Dot Plot 』是最简单的一种表示方式:
- 找到每个测量值在 轴上对应的位置,然后在上面画一个 "点",如果此位置上已经有点存在,则在该点之上进行堆叠。
- 当有多个测量值都具有相同的数值, 它们都落在了 轴上的同一个位置, 这些点堆叠起来称为一个柱形图案。
🌰 例子:
下图 👇 展现了 100 辆新车里程等级的测量值。
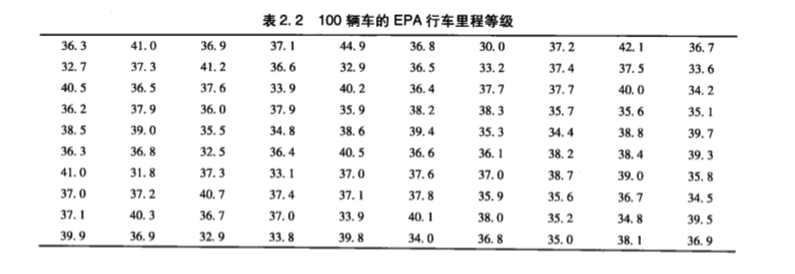
用点图 Dot Plot 进行表示:

# 茎叶图 Stem and Leaf Plot
构造『 茎叶图 Stem and Leaf Plot 』时:
- 先把数据集中的每一个测量值分为 "茎" 和 "叶" 两个部分.
- 🌰 例如,
1.32和2.45可以分成1 - 32和2 - 45
- 🌰 例如,
- 将 "茎" 按照数值大小依次排列成一列,再把每个测量值的 "叶" 放到对应的 "茎" 的后面。同一行上的 "叶" 可以按照大小顺序排列。
🌰 例子:
下图 👇 是对上面 100 辆新车里程等级的测量值的『 茎叶图 』表示:

# 直方图 Histogram
- 计算出 "最小测量值" 与 "最大测量值" 之间的间距,然后将其分为若干个等距的区间 ( 5 - 12 个 ) 。等同于,人为给数据创造出了类别。
- 计算出落入每个区间的测量值的个数,将其作为每个类别的 "频数",并计算出其 "相对频数"。然后用 "柱形" 进行表示。
🌰 例子:
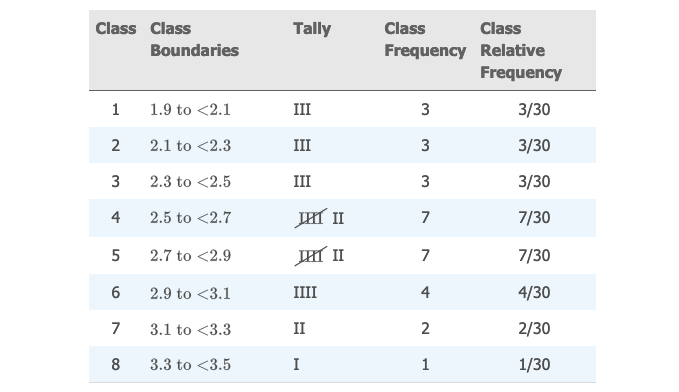
下表 👇 展示了 30 个大学一年级学生,第一学年的 GPA 分数。
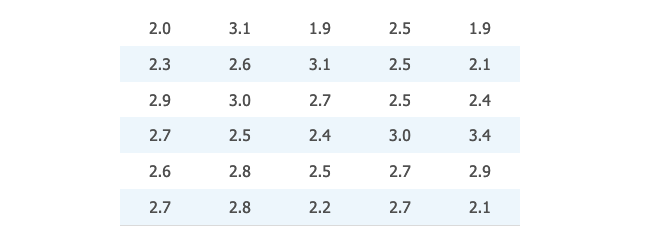
在 "点图" 的基础上,在横轴上分出了 8 个区间:

计算出每个区间的频数,以及相对频率:
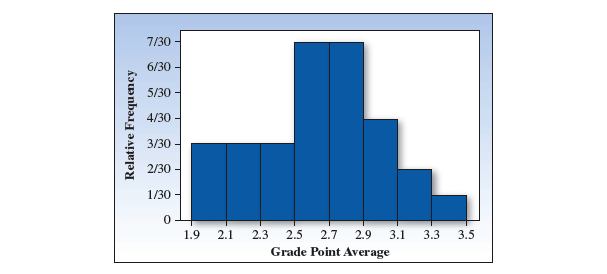
用 "直方图 Histogram" 来表示:
# 折线图 & 时间序列图
如果数据是随着一个有序类别而变化的,那么可以用『 折线图 Line Chart 』去表示数据变化的趋势。
最常见的一种折线图就是『 时间序列图 Time-Series Plot 』
当数据是 "随时间变化" 记录的。我们可以用 "时间序列图" 去进行表示:
- 轴表示时间, 轴表示数值。
- 每次观测之间需要有相同的时间间隔。
- daily, weekly, monthly, quarterly, yearly
- 时间序列图可以表示出来数值随时间变化的趋势。
🌰 例子:
下表 👇 以年为周期,展示了加拿大的人口增长数量。

下面的两个时间序列图中,分别用了两种不同的 轴刻度 scale。虽然数据相同,但是图表给人的直观感觉不同。在实际画图时,需要根据需求,选择最恰当的刻度。

折线图也可以很直观地表示出 "多组数据":

# 用 "数值" 描述 Numerical 数据
Graph can help you describe the basic shape of a data distribution. However, there are some limitations of using the graphs.
- 假设你要口头描述一组数据,图片帮不上忙,你需要有一种方式去描述数据,能够让对方在脑海中呈现出画面。
- 用图像去做统计推断是不精确的。
『 数值型描述度量 numerical descriptive measures 』可以解决上述的问题。它由总体或样本的测量值计算而得的数值。描述了总体或样本的特征。
- 『 参数 parameters 』与总体的测量值相关,是描述总体特征的数值。
- 『 统计量 statistics 』由样本测量值计算而得,是描述样本特征的数值。
# 中心趋势度量
『 中心趋势度量 measure of centre 』描述了数据分布的中心位置。
『 算术平均值 arithmetic mean 』把所有数据求和再除以数据的个数来获得。
- 用符号 表示『 样本均值 』
- 用符号 表示『 总体均值 』
『 中位数 median 』数据从小到大排列后的位于中间的数值。
- 用符号 表示『 样本中位数 』
- 用符号 表示『 总体中位数 』
中位数不会受极端值的影响。平均数容易受极端值的影响。
- 🌰 例如,一个酒吧里坐着 5 个工人,平均工资是 3000 美元。突然比尔盖茨进来了,一下子就把平均工资提升到了一个无法想象的高度。但是 5 个工人的收入并没有任何增加。"中位数" 就可以避免这个问题,比尔盖茨的加入并不会改变先前的中位数。
『 众数 mode 』在数据集合中出现次数最多的数值。
- 数据中可能存在众数,可能不存在众数,也可能存在多个众数。
- 和中位数一样,极端值不会影响众数。
🌰 例子:
下表 👇 列出了 30 个一年级学生第一学年的 GPA 成绩:
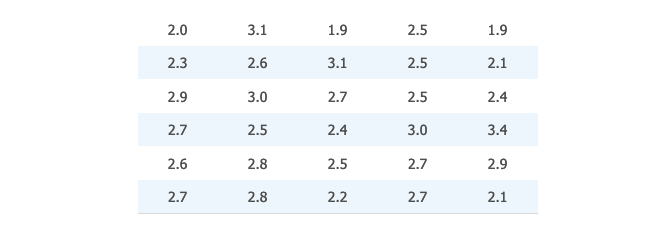
GPA 成绩的相对频率直方图:
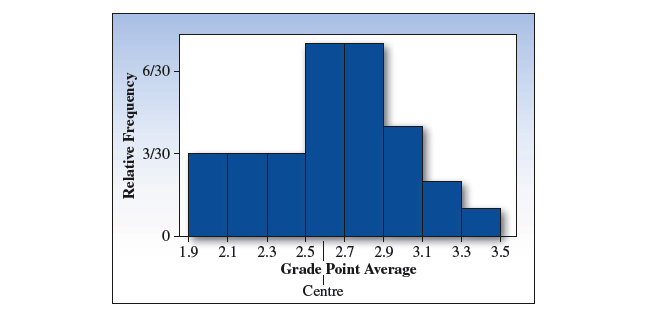
- 『 平均数 』为
2.5552 - 『 中位数 』为
2.6 - 『 众数 』为
2.5和2.7
# 变异性度量
两组具有相同 "中心位置" 的数据可能在图中看起来差别很大。每组数据中观测值到中心位置的距离都是不固定的。
『 变异性度量 measures of variability 』描述了一组数据距离中心位置的离散程度。
『 极差 range 』数据集合中最大测量值减去最小测量值的差。
『 方差 variance 』表示数据偏离平均值的程度。等于所有测量值与 "平均值" 的差的平方和,除以数据个数减 1
- 用符号 表示『 样本方差 』
- 用符号 表示『 总体方差 』
也可以简化为:
- 以 作为分母的原因是,这样计算出来的 可以更准确地去估计 。具体的数学推导这里就不介绍。
『 标准差 standard deviation 』方差的平方根。
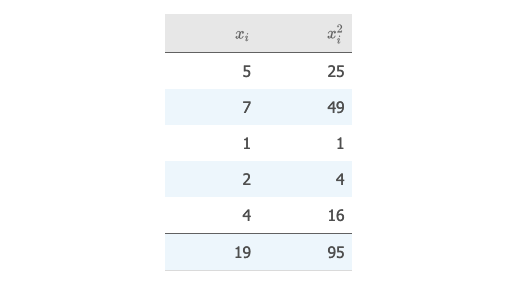
🌰 例子:
计算 5,7,1,2,4 这组数据的 "方差" 和 "标准差":
- "方差" 或 "标准差" 越大,数据的离散程度越大,图形看起来越 "胖"。反之,数据看起来越 "瘦"。
- 如果 "方差" 或 "标准差" 为 ,则意味着所有的测量值都是相同的。
# 经验法则 & 切比雪夫法则
"标准差" 可以应用在两个很有名的描述 "数据分布" 的法则之中:
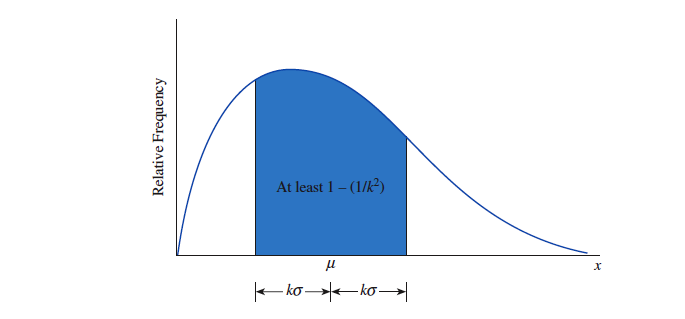
『 切比雪夫法则 Tchebysheff‘s Theorem 』由俄国科学家 Tchebysheff 证明的结论。
- 可以应用于任何数据集合之中,无论数据的频数分布是什么形状的。也因如此,该法则的估计更保守一些。
- 认为对于任意大于 的数 ,至少有 的测量值落在平均值的 个标准差范围内,即 :
- 很少的测量值落入平均值的 个标准差范围内。
- 至少 测量值落入平均值的 个标准差范围内。
- 至少 测量值落入平均值的 个标准差范围内。
『 经验法则 Empirical Rule 』由科学家通过观察真实数据集得到出的实际经验准则。
- 只可以对呈现丘型对称分布的数据集使用。
- 认为大约 的观测值位于均值 个标准差范围内。
- 认为大约 的观测值位于均值 个标准差范围内。
- 认为几乎所有的观测值都位于均值 个标准差范围内。
由上面两条法则可以推出,"标准差" 大约等于 "极差" 除以 。但这只是一种非常粗糙的估计值。
# 相对位置度量
『 相对位置度量 measures of relative standing 』用以描述一个观测值在数据集中的相对位置。
『 得分 』以 "标准差" 为单位, 描述了测量值相对于均值的距离。
- 负的得分表示测量值位于均值的左边。正的得分表示测量值位于均值的右边。
- 根据 "切比雪夫法则" 和 "经验法则",可以推导出:
- 大约 75% 到 95% 的观测值 得分在 和 之间。
- 大约 89% 到 99.7% 的观测值 得分在 和 之间。
🌰 例子:
一个样本中的观测值为:1,1,0,15,2,3,4,0,1,3
可以算出:
- = 10
- = 3
- = 4.42
对于观测值 = 15,它的 得分为:
『 百分位数 percentile 』在数据集的分布曲线中,第 百分位数 ( th percentile ) 表示 轴上的一个值,它大于 的观测值, 小于 的观测值。
- 适用于观测值数量 比较大的数据集合。
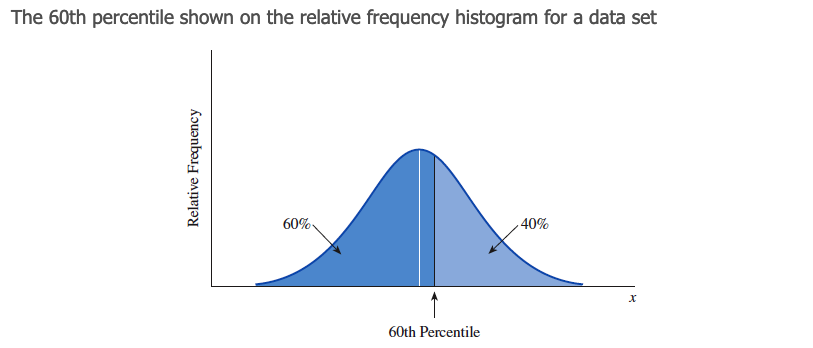
- 🌰 上图中画出了 "第 60 百分位数" ( the 60th percentile ),它对应的 值大于 60% 的观测值,小于 40% 的观测值。在曲线内,也可以认为这个位置左边的面积占 60%,右边的面积占 40%。
有一些特殊的百分位数,有特殊的称呼:

- 第 25 百分位数, 称为『 下四分位数 lower quartiles, 』也称为『 first quartiles, 』
- 第 50 百分位数, 称为『 中四分位数 median quartiles 』, 也是数据集的『 中位数 』也称为『 second quartiles 』
- 第 75 百分位数, 称为『 上四分位数 upper quartiles, 』也称为『 third quartiles, 』
- 『 四分位距 interquartile range, IQR 』等于
🌰 例子:
找出下面 👇 观测值集合的四分数:
先从小到大进行排序:
- n = 11
- Position of = 0.25(11 + 1) = 3
- Position of = 0.75(11 + 1) = 3
在排好序的观测值队列中到对应位置的数值:
- = 4
- = 31
- IQR = 31 - 4 = 27
# 异常值检测
一个数据集中有时会包含一些不规则的测量值, 我们可能并不希望数据集中包含这样的测量值。
这样的测量值称为『 异常值 outlier 』, 用符号 表示。
异常值出现的原因有:
- 在观测或记录测量值时出现了错误;
- 测量值来自于不同的总体;
- 测量值是正确的, 其代表一个偶然事件;
可以通过计算一个值的 得分 来判断它是否是异常值。
- 根据经验法则可以知道,几乎所有的观测值的 得分的绝对值都小于 3。
- 所以,如果一个观测值的 得分绝对值大于 3,那么可以认为其是一个异常值。
通过构造数据集合的『 盒子图 Box Plot 』也可以找出异常值。
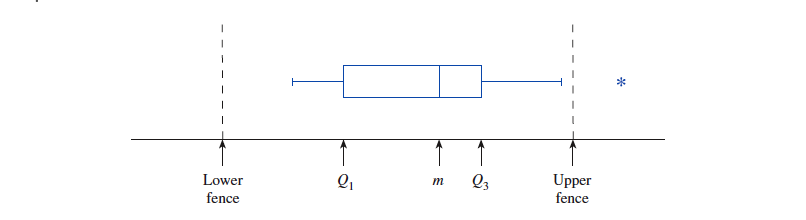
- 先找出 "下四分位数" 和 "上四分位数",并且以这两个位置 ( 关键点 ) 为边界画一个长方形 "盒子",并在其中用直线标出 "中位数" 的位置。
- 将距离每一关键点 1.5 IQR 处的点标记为数据集的『 内篱笆 』把关键点与内篱笆之内的 "末端测量值" 用线连接到盒子上。
- 下侧内篱笆 Lower Fence =
- 上侧内篱笆 Uower Fence =
- 将距离每一关键点 3 IQR 处的点标记为数据集的『 外篱笆 』用
*表示落在内篱笆和外篱笆之间的测量值。 - 落在外篱笆之外的值,可以认为是异常值。
🌰 例子:

# 用 "图表" 描述 Bivariate 数据
很多时候,我们会在试验中对一个试验单位身上两个变量进行测量,这样获得的数据成为『 二元数据 bivariate data 』
- 🌰 经济学家调查每个家庭的每月食品消费情况,他可能会同时记录 "每月食品消费的金额" 和 "家庭人口数量" 这两个变量的值。
- 🌰 地产销售调查所在地区二手房屋价格,他可能会同时记录 "房屋成交价格" 和 "房屋平米数" 这两个变量的值。
我们需要一些方法去描述 Bivariate 数据。
# 列联表 & 并行条形图
当数据是按两个变量交叉分类时,我们用『 列联表 Contingency Table 』去进行表示。
- 轴表示一个变量, 轴表示另一个变量。数据值位于横纵轴交叉处。
- 数据按 2 个变量交叉分类的列联表,称为『 两维列联表 』。
- 数据按 1 个变量分类的列联表,称为『 一维列联表 』,也就是前面 👆 看到的那些表。依次类推,数据按照 3 个或更多变量分类的列联表称为『 多维列联表 』
🌰 例子:
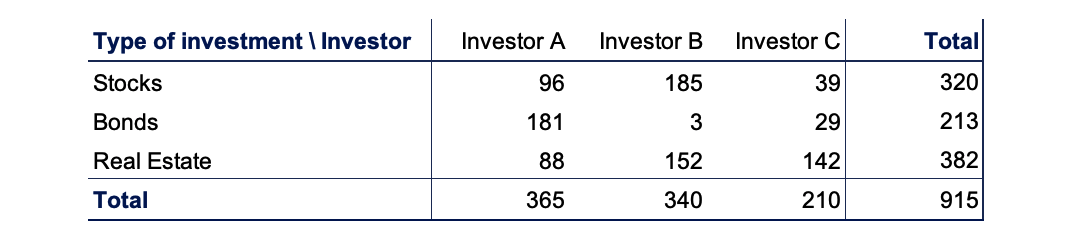
通过『 并行条形图 Side-by-Side Bar Chart 』可以可视化地表示出列联表:
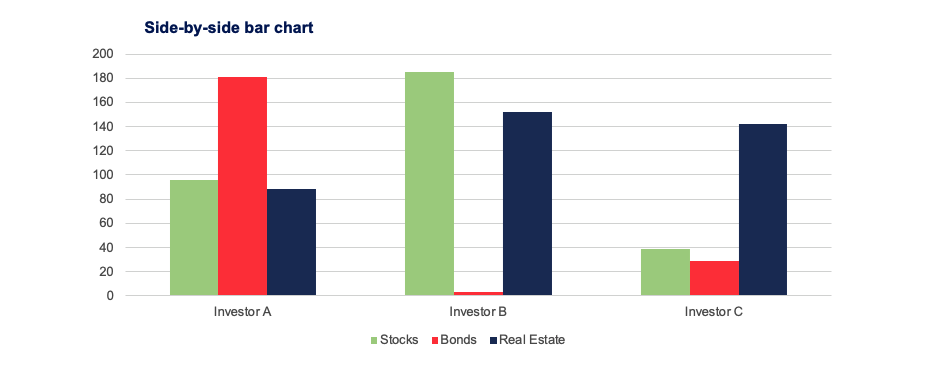
下面是用『 并行饼状图 Side-by-Side Pie Chart 』进行表示:

# 散点图 Scatter Plot
当两个变量的值都为 quantitative 时,当用『 散点图 Scatter Plot 』可以比较两个变量之间可能存在的关系。
- 轴表示一个变量, 轴表示另一个变量。
- 在图上用一个 "点" 来同时表示两个变量的值。
- 当两个变量之间存在 "线性关系" 时,所有的点应当都大致落在一条线的周围。
🌰 例子:
下表 👇 列出了 100 名学生 "阅读" 和 "写作" 的成绩:

用 "散点图" 来表示,可以看出所有的 "点" 是大致围绕着一条直线分布的。可以猜想 "阅读" 和 "写作" 的成绩是具有线性关系的。

# 用 "数值" 描述 Bivariate 数据
下面介绍几个对于散点图的的数值型描述度量。
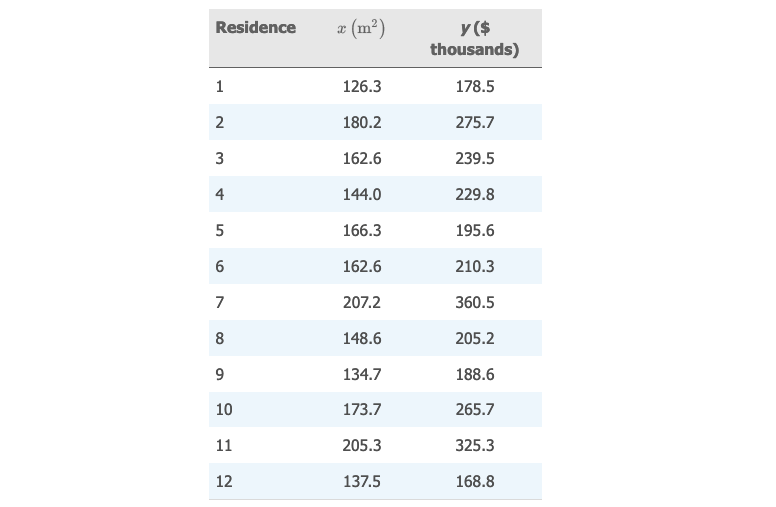
👆 这个表中记录了 12 个房屋 "售价" 和 "居住面积" 的数据。
根据前面所学,我们可以单独算出来 和 的平均数,标准差,等数值描述性度量。但是这些度量没有体现出 "变量 和 之间的关系"。
『 协方差 covariance 』可以度量出两个变量间的 "线性关系"。计算公式为:
也等于:

『 相关系数 correlation coefficient 』可以表示出两个变量间的 "线性关系强度"。
- 和 是变量 和 的『 标准差 』。
- 是变量 和 的『 协方差 』
- 表示两个变量间有 "正" 的线性关系。
- 表示两个变量间有 "负" 的线性关系。
- 表示两个变量间 "没有" 线性关系。
🌰 例子:
拿最上面 👆 的那个房屋数据举例。它的散点图如下:
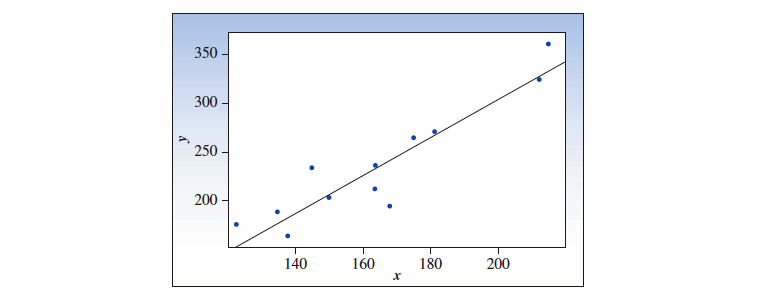
计算得出: = 26.15822, = 29.7592
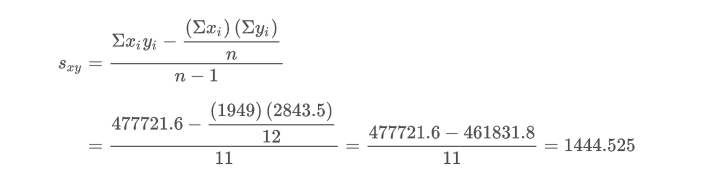

相关系数 的值接近于 ,可以认为 "房屋售价" 和 "居住面积" 有很强的正的线性关系。随着居住面积的增加,房屋售价也同步增加。
在认为两个变量间具有某种关系时,假如变量 的值依赖于 ( depends on ) 的值,则称:
- 为『 自变量 independent variable 』
- 为『 因变量 dependent variable 』
如果 和 呈现线性关系的话,那么应该存在一条表示两个变量之间关系的直线
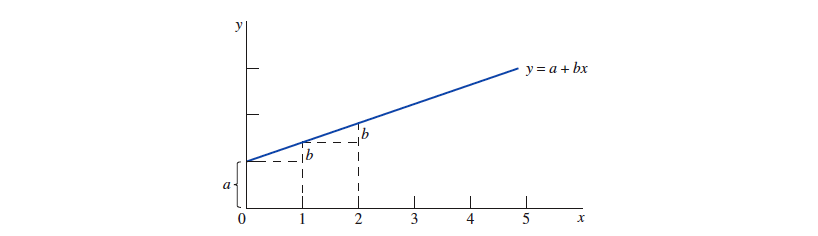
- is called the『 y-intercept 』
- is called the『 slope 』of the line, for every one-unit increase in , increases by an amount .
数据集合中的观测值,在散点图中应当围绕着这条直线散布。从每个点到这条直线做一条 "垂线",它代表点到直线的误差,这条直线使得 "误差的平方和" 最小,称为 the best-fitting line relating to ,也被叫做『 最小二乘直线 least-squares line 』或『 回归直线 regression 』
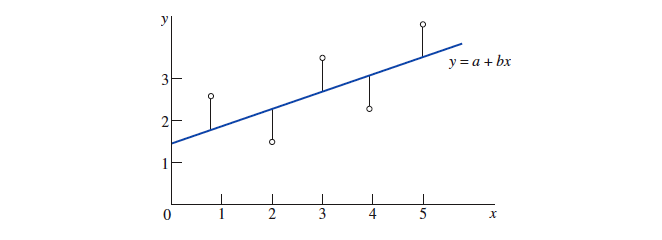
具体 和 d 值可以用如下公式求出:
🌰 例子:

计算得出:
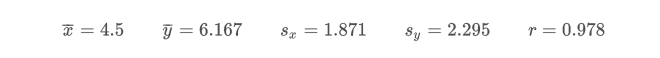
进一步计算出 和 的值:
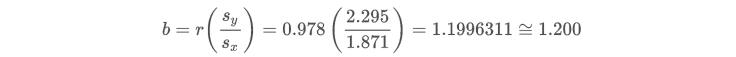

可以得出
在散点图中表示:

# 📝 综合练习
下表 👇 列出了房产公司的销售数据。左边是 Product 相关信息,右边是 Customer 相关信息。

从表中,我们先去计算一下顾客『 Gender 』的 "频数" 和 "相对频率"。并且 Pie Chart 来表示:
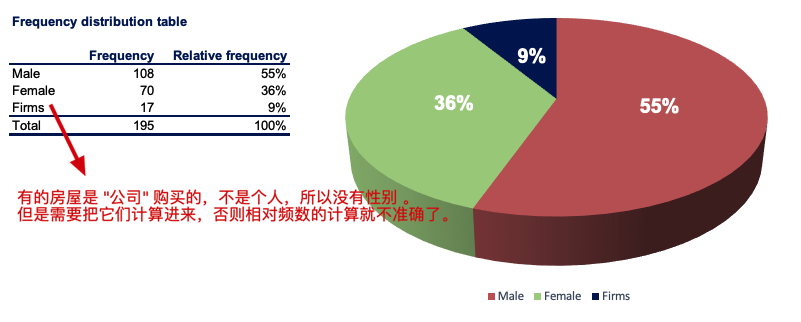
- 图中使用了『 帕累托图表 pareto diagram 』用条形图去表示每个分类的频数,用折线图去表示累积相对频率。
再关注一下『 Location 』这个变量:

接下来关注一下『 Age at time of purchase 』"顾客购买房屋时的年龄" 这个变量的情况:
用 "直方图" 来绘制出数据分布,间距 interval 为 1:

去掉 "公司" 购买那部分数据,然后选取一个更合适的 "年龄区间",计算出来 "频数" 和 "相对频率" 以及相关的统计量,并且绘制新的直方图:

接下来,关注『 Age 』和『 Price 』两个变量。我们来看看它们之间是否存在关系:
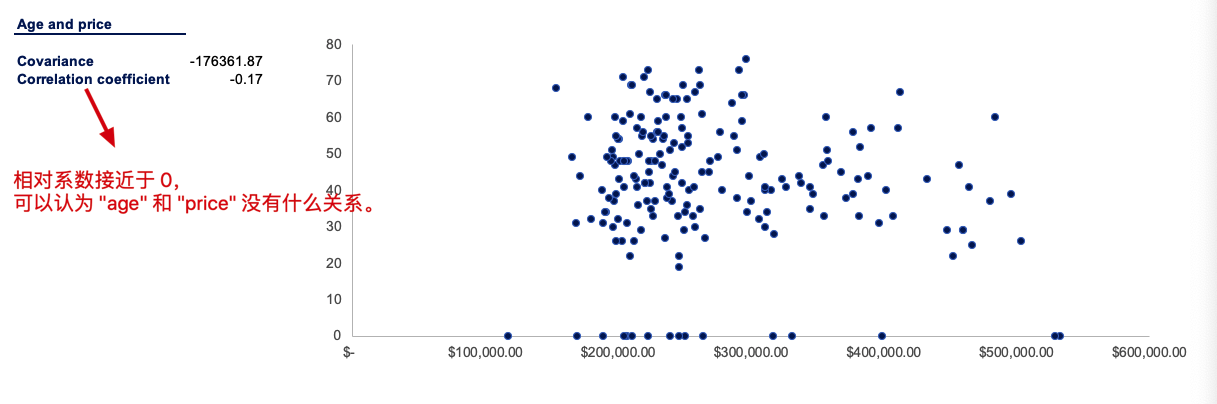
根据上面 👆 的各种描述性统计,我们可以得出以下分析结论:

# 其他
下图 👇 展示了根据你想要展示的目的和数据类型不同,所需要使用的最适合的图表:
