# 应用层
网络应用可以说是计算机网络存在的意义, 没有应用, 网络也就没什么用了;
这一节, 学习有关网络应用通信的原理和实现;
# 应用层协议原理
# 网络应用程序体系结构
应用程序体系结构, 规定了如何在各种端系统上组织应用程序.
开发者通常, 会采用两种主流的体系结构:
- 客户 - 服务器体系结构 client-server architecture;
- P2P 体系结构 P2P architecture:
# 客户 - 服务器体系结构
有一个打开的主机称为『 服务器 』, 它服务来自于许多称为『 客户 』的主机的请求.
- 请求会在服务器端进行处理, 然后服务器返回一个对应的响应给客户端;
- 客户 - 服务器体系结构中, 各个客户端之间不直接通信;
缺点: 随着客户请求的增大, 服务提供商必须不断地升级服务处理能力, 并且负担增加的流量和带宽的费用. 成本较大;
# P2P 体系结构
应用程序在主机之间直接通信, 这些主机称为『 对等方 』, 通信不依赖专有的服务器;
- 🌰 很多『 流量密集型应用 』都是 P2P 结构, 文件共享程序 (例如, BitTorrent), 对等方协助下载加速器 (例如, 迅雷), IPTV (例如, 迅雷看看)
- P2P 体系结构具有『 自扩展性 self-scalability 』, 随着用户的增多, 有更多的对等方互相之间分发文件, 整个系统的服务能力自发提升, 同时不需要服务器能力和带宽;

# 进程通信
程序员编写的应用程序, 最终会在操作系统中, 被创建为『 进程 process 』进行通信:
- 在一台主机上, 进程间使用操作系统提供的『 进程间通信机制 』进行通信;
- 而在不同端系统上, 进程通过计算机网络交换『 报文 message 』进行通信;
# 客户 & 服务器进程
⚠️ 注意, 这里的『 客户 』和『 服务器 』形容的是『 进程 』 与『 客户 - 服务器体系结构 』所指的不是一回事.
网络应用程序由成对的进程进行通信. 将发起通信的进程标识为『 客户 』, 将等待通信的进程称为『 服务器 』
- 🌰 在 Web 应用中, 由一个客户浏览器进程与一台 Web 服务器进程交换报文;
- 🌰 在 P2P 文件共享系统中, 下载文件的对等方是客户, 上传文件的对等方是服务器;
# 进程与计算机网络之间的接口
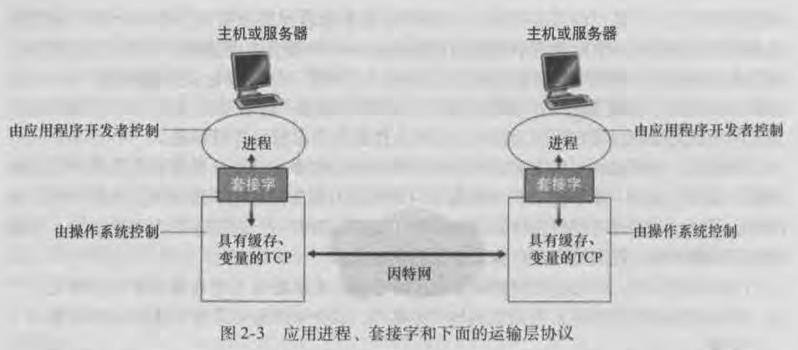
进程通过『 套接字 socket 』接口来向网络发送 / 接收报文:
- 套接字, 是主机内 "应用层" 与 "运输层" 之间的通信接口, 也就是运输层提供给应用层的 API;
- 通过套接字, 开发者可以控制应用层想要使用的运输层协议, 相关参数, 以及想要传送给运输层的相关数据;
- 套接字使用了运输层什么协议, 我们就说 "应用程序建立在由该协议提供的运输层服务之上";
# 进程寻址
为了正确的向另外一个主机上进程发送分组, 接收进程需要有一个地址, 该地址定义了两种信息:
- 主机的地址: 由『 IP 地址 』标识;
- 主机中的接收进程: 由主机上的『 端口号 』来标识;
# 可供应用程序使用的运输服务
存在着不止一种的运输层协议, 在开发应用程序时, 我们需要根据自己的需求选择合适的运输层协议;
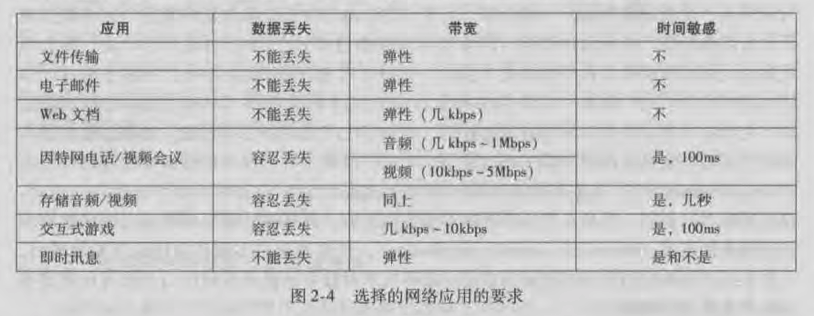
应用程序对运输层协议的需求, 大致可以分为如下四个方面:
可靠的数据运输:
- 分组在网络中传输时可能会造成丢包;
- 如果一个运输层协议能够确保从一端应用程序发来的数据能够准确无误的发送到另外一端的应用程序上, 那么就称此协议提供了『 可靠数据传输 reliable data transfer 』
- 应用程序可以放心把数据发送给提供可靠数据传输的运输层, 完全相信数据可以准确无误地传递到目的地;
- 对于『 容忍丢失的应用 loss-tolerant application 』不提供可靠数据传输的运输层协议是可以接收的;
- 🌰 例如, 音视频应用可以容许稍微的丢包;
吞吐量:
- 可用吞吐量就是发送进程能够向接收进程交付数据的速率;
- 具有吞吐量要求的应用程序被称为『 带宽敏感的应用 bandwidth sensitive application 』
- 对于这种应用, 有的运输层协议提供确保传输速率的服务;
- 对于没有特定的吞吐量需求的应用, 称为『 弹性应用 elastic application 』
- 但无论如何, 吞吐量越大越好是无疑的;
定时:
- 对于实时交互式应用程序, 它们对于数据交付的时间有严格的要求;
- 有的运输层协议可以提供『 定时保障 』, 保证数据能够以限定的时间内传输到目的地;
- 🌰 对于数据传输时间有严格要求的应用有: 网络游戏, 音视频直播;
安全性:
- 有的运输层协议可以为应用程序提供各种各样的安全性服务;
- 🌰 例如, 提供加密服务的运输层协议, 可以加密由发送进程传输的所有数据, 并且在接收端的运输层里将数据解密, 然后交付给接收进程;
# 因特网提供的运输服务
开发者需要根据应用的需求, 选择合适的运输层协议. 下图 👇 展示了不同应用的网络需求:
因特网为应用程序提供两个运输层协议:
- UDP
- TCP
TCP 服务:
- 面向连接服务:
- 在应用层数据报文开始传送之前,TCP 让客户和服务器互相交换运输层控制信息,这被称为『 握手 』
- 在握手阶段后,一个『 TCP 连接 』就在两个进程的套接字之间建立了;
- 这条链接是『 全双工 』的, 即连接双方的进程都可以在此连接之上互相收发报文;
- 当应用程序结束报文传输之后,必须断开该连接;
- 可靠度数据传送服务:
- 通信进程能够依靠 TCP 无差错,按适当顺序交付所有发送的数据;
UDP 服务:
- UDP 协议提供一种『 不可靠数据传送服务 』
- UDP 是『 无连接 』的,因此两个进程通信前没有握手过程;
- 当进程将一个报文发送给 UDP 套接字时, UDP 协议并不保证将这报文能传送到接收进程。
# HTTP
# HTTP 概述
20 世纪 90 年代, 万维网 (World Wide Web, WWW) 作为一个因特网应用程序被开发出来;
- WWW 中把各种信息按照页面的形式组合;
- 只包含有文本, 链接的页面称为『 超文本 』页面上的链接称为『 超链接 』
- 还包含有视频, 音频, 图像等信息的页面称为『 超媒体 』
- 各种资源之间通过 "超链接" 互相引用;

WWW 中使用『 统一资源定位符 URL 』来标识 WWW 中的各种资源.
- 格式为: <协议>://<主机名>:<端口号>/<路径>
WWW 的应用层协议是『 超文本传输协议 HyperText Transfer Protocol, HTTP 』
HTTP 由两个程序实现, 一个客户程序, 一个服务器程序, 它们分别运行在不同的端系统中. 通过交换 HTTP 报文进行会话;
- 客户程序通常指『 Web 浏览器 』;
- 服务器程序通常指『 Web 服务器 』;
HTTP 使用 TCP 作为它的支撑运输协议:
- HTTP 客户端,首先发起一个与服务器的 TCP 连接,一旦建立连接,该浏览器与服务器进程就可以通过套接字接口访问 TCP;
- 因为 TCP 连接提供可靠的数据传输服务,所以一个客户进程发出的每个 HTTP 请求,最终报文都能完整的送达服务器。同理, 服务器的响应也能够完整地到达客户端;
HTTP 是一个『 无状态协议 』,HTTP 服务器并不保存关于客户的任何信息;
# 非持续连接 & 持续连接
在客户端与服务器建立 TCP 连接时, 有如下两种方式:
- 非持续连接 non-persistent connection:
- 每个 TCP 连接只传输一个请求报文和一个响应报文;
- 在客户端接收到服务端响应后, TCP 连接就会断开;
- 等下次客户端想要给服务器发请求时, 再重新建立 TCP 连接;
- 持续连接 persistent connection:
- TCP 连接可以保持, 持续的发送请求和响应;
- 通常会对连接设置一个闲置时间, 如果 TCP 连接空闲超过这个时间, 连接就会断开;
- HTTP 协议默认使用持续连接;
# HTTP 报文格式
HTTP 报文有两种:
- 请求报文;
- 响应报文;
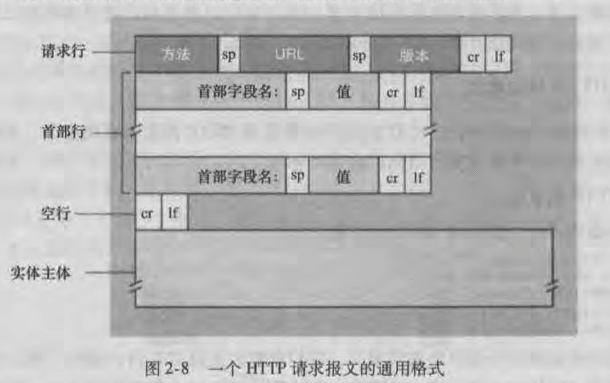
# 请求报文
下图 👇 是请求报文的组成结构:

# 响应报文
下图 👇 是响应报文的组成结构:

响应报文中会根据请求的结果, 给出一个对应的状态码. 例如:
- 200: 请求成功;
- 301: 请求的对象被永久转移了;
- 400: 请求不被服务器理解;
- 404: 被请求的资源不在服务器上;
# Cookie
- 因为 HTTP 协议是无状态的, 服务器默认不知道请求的客户端是谁;
- 但是很多功能的实现需要依靠对于用户的识别, Cookie 技术可以帮应用实现这个功能;
下图 👇 展示了客户端与服务器之间如何使用 Cookie 实现客户识别:
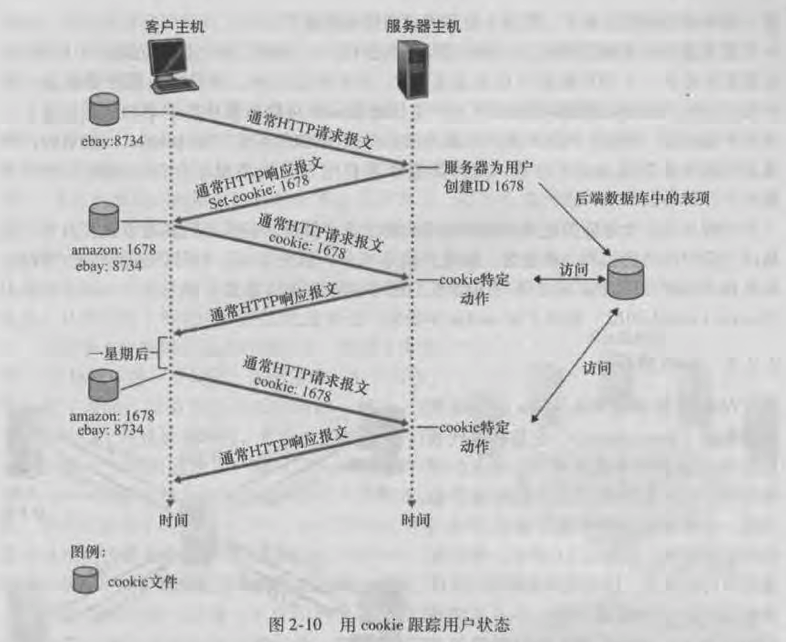
- 当客户端第一次访问服务器时, 服务器生成关于客户端的唯一识别码 ID, 并把此 ID 作为索引, 用于在数据库中储存和客户端相关的信息;
- 接下来服务器将一个包含
Set-cookie的首部字段的 HTTP 响应报文发送给客户端, 首部字段的值包含服务器生成的 ID; - 当客户端接收到响应后, 浏览器检测到报文中的
Set-cookie首部字段, 它会在浏览器中管理 Cookie 的文件中添加一行, 该行包含服务器的主机名和Set-cookie字段的值; - 当客户端再去向服务器发送请求时, 浏览器会把自身保存的 Cookie 信息放到 HTTP 请求报文的
cookie首部行中; - 服务器接收到请求报文, 解析
cookie字段的值, 把它放到数据库中去检索出和对应客户端相关的信息;
# Web 缓存
- 『 Web 缓存器 Web Cache 』也称『 代理服务器 Proxy Server 』
- 它位于客户端与初始服务器之间。 通过配置浏览器,使客户端的所有 HTTP 请求首先指向 WEB 缓存器;
- 缓存器会先在自身找是否有客户端想要请求的对象的副本。如果有的话就直接返回给客户端;
- 如果没有的话就去向初始服务器进行请求,并会在接收到响应后,现在缓存器中保存一份副本,然后再返回给客户端;
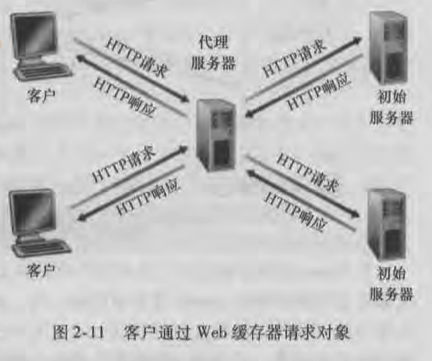
WEB 缓存器的好处:
- WEB 缓存器通常由 ISP 提供;
- 在因特网上部署 WEB 缓存器只要有如下原因:
- 当客户端与初始服务器之间的瓶颈宽带低于客户端与 WEB 缓存器之间的瓶颈宽带时,WEB 缓存器可以大大减少客户请求的响应时间。( 通常客户与 WEB 缓存器之间有一个高速连接 )
- WEB 缓存器能够大大减少一个机构的接入链路到因特网的通信量,通过减少通信量可以减少该机构的带宽需求,并因此来降低费用;

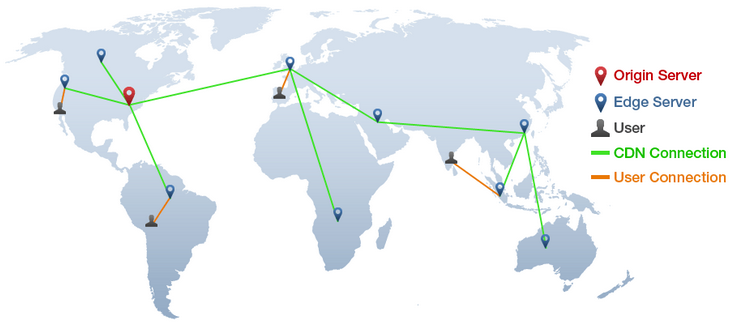
内容分发网路:
- 『 内容分发网络 Content Distribution Network, CDN 』是 WEB 缓存器的一个重要应用;
- CDN 公司在因特网上安装了许多地理上分散的缓存器, 使得大量流量可以实现本地化;
- 可以提高客户端请求远距离服务器时的响应速度;
# DNS
# DNS 服务概述
- 为了方便人类记忆, 使用『 主机名 hostname 』对一台主机进行标识;
- 🌰
www.baidu.com,www.google.com - 然而主机名并没有提供主机在因特网中的位置信息;
- 🌰
- 使用『 IP 地址 』对主机的位置进行标识;
- 🌰
121.7.106.83 - 每台主机都有一个唯一的 IP 地址;
- 🌰
- IP 地址具有层次结构, 从左至右地扫描它时, 可以一步步地得到关于主机位置越来越具体的信息;
- 为了得到主机名和 IP 地址的映射, 需要使用『 域名系统 Domain Name System, DNS 』, 其将主机名解析为 IP 地址;
- DNS 协议是一个应用层协议, 运行在 UDP 连接上, 默认在 DNS 服务器上使用 53 号端口;
- DNS 协议通常服务于其他应用层协议, 例如 HTTP, SMTP 和 FTP;
- 🌰 为了使用户的主机能够将一个 HTTP 请求发送到指定的 Web 服务器
www.someserver.com, 该用户主机需要先获得www.someserver.com的 IP 地址:- 先将主机名
www.someserver.com发送到同一台主机上运行的 DNS 客户端; - DNS 客户端向 DNS 服务器发送一个包含主机名的请求;
- DNS 服务器返回 IP 地址查询结果给 DNS 客户端;
- 用户主机的 DNS 客户端再把 IP 地址发送给浏览器;
- 之后浏览器向 IP 地址对应的主机的 HTTP 服务器发起一个 TCP 连接;
- 先将主机名
# DNS 工作机理
- 可以想象最简单的一种 DNS 实现就是整个因特网上只部署一台 DNS 服务器, 这台服务器负责所有的主机名与 IP 地址的查询. 但是很显然在今日的因特网体量下, 这种实现并不可用:
# 分布式, 层次性查询
- DNS 采用了分布式的设计方案. 使用了大量的 DNS 服务器以层次的方式组织, 并且分布在全世界范围;
- 在这种分布模型中, 有三种类型的 DNS 服务器:
- 根 DNS 服务器;
- 顶级域 DNS 服务器 Top-Level Domain, TLD;
- 权威 DNS 服务器;
🌰 假定一个 DNS 客户想要获取主机名 www.amazon.com 的 IP 地址, 大概流程如下:
- 客户首先与根服务器连接, 查询顶级域名
.com的 TLD 服务器的 IP 地址; - 客户再与 TLD 服务器连接, 请求
amazon.com的权威服务器 IP 地址; - 最后, 客户再与
amazon.com的权威服务器连接, 请求主机www.amazon.com的 IP 地址;
- 除了上述的 DNS 服务器, 在层次结构之外, 还有一种『 本地 DNS 服务器 』
- 基本上每个 ISP 都会部署一台本地 DNS 服务器;
- 当客户主机发出 DNS 请求时, 会先被发往相连的 ISP 的本地 DNS 服务器, 然后再由它去将请求转发到因特网中的 DNS 层次结构;
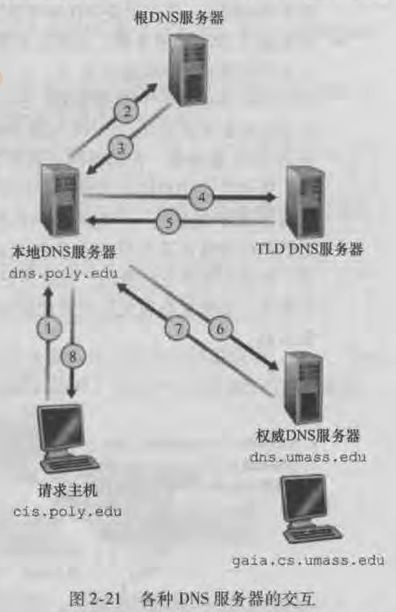
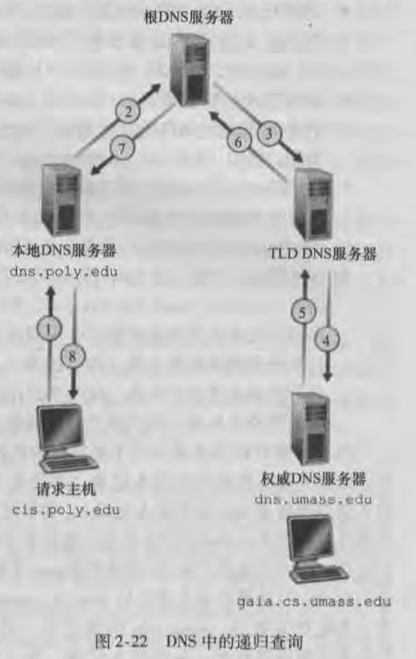
- 上面 👆 两张图分别展示了『 迭代查询 iterative query 』和『 递归查询 recursive query 』
- 实践中, 查询通常都是用的第一图 (图 2-21) 所示的查询方法, 请求主机到本地 DNS 服务器是 "递归查询", 本地 DNS 主机与 DNS 层次结构中的服务器是 "迭代查询";
# DNS 缓存
- 为了提高查询性能, DNS 服务器中存采用『 DNS 缓存 』
- 原理就是当某个 DNS 服务器接收到一个 DNS 查询响应时, 会把结果保存在本地的储存器中;
- 这样当再有相同主机名的查询到达此服务器时, 就可以不用再往下查询, 直接返回之前保存的 IP 地址;
- DNS 缓存都会有一个过期时间, 当缓存超过了设置的时间就会被删除;
- 通过在本地 DNS 服务上使用 DNS 缓存, 可以大大提高用户主机对于 IP 地址的查询效率;
# DNS 记录和报文
# DNS 记录
- DNS 服务器中储存了『 资源记录 Resource Record, RR 』
- RR 提供了主机名到 IP 地址的映射;
- 每个 DNS 回答报文包含了一到多条资源记录;
- 资源记录是一个包含了下列字段的 4 元组:
- Name;
- Value;
- Type;
- TTL;
- TTL 全称 Time To Live, 表示该资源记录在 DNS 服务器的缓存中的过期时间;
- Name 和 Value 的值取决于 Type 类型:
Type = A:- Name 是主机名;
- Value 是主机名对应的 IP 地址;
- A 类型的资源记录提供了主机名到 IP 地址的映射;
- 🌰
bar.foo.com, 145.37.32.123, A
Type = NS:- Name 是个域, 例如
foo.com - Value 是知道如何获取该域中的主机 IP 地址的权威 DNS 服务器的主机名;
- NS 类型的资源记录用与沿着查询链条来路由 DNS 查询;
- 🌰
foo.com, dns.foo.com, NS
- Name 是个域, 例如
Type = CNAME:- Name 是一个域名;
- Value 是别名为 Name 值的 "主机" 的 "规范主机名";
- CNAME 类型的资源记录能够向查询的主机提供一个主机名对应的规范主机名;
- 🌰
foo.com, bar.foo.com, CNAME - CNAME 使得可以在一个主机上支持多个 IP 地址, 以此来实现多个服务共同运行在一个主机上;
Type = MX:- Name 是一个域名;
- Value 是别名为 Name 值的 "邮件服务器" 的 "规范主机名";
- MX 记录允许在一台主机上, 邮件服务器和其他服务器具有相同的别名, 例如
foo.com. 通过 DNS 客户请求记录的不同, DNS 服务器返回不同的规范主机名; - 🌰
foo.com, mail.bar.foo.com, MX
- 如果一台 DNS 服务器是用于某特定主机名的权威 DNS 服务器,那么该 DNS 服务器会有一条包含该主机名的 "类型 A" 记录;
- 如果服务器不是用于查询某主机名的权威服务器,那么该服务器将包含一个 "类型 NS" 记录,该记录对应于包含主机名的 DNS 服务器的域;
- 同时它还将包括一条类型 A 记录,其提供了在 NS 记录的 Value 字段中的域, 对应的 DNS 服务器的 IP 地址;
- 🌰 例如:
umass.edu, dns.umass.edu, NSdns.umass.edu, 128.119.40.111, A
- 🌰 例如:
# DNS 报文
- DNS 只有两种报文类型,『 查询报文 』和『 回答报文 』
- 两种报文有着相同的格式;

- 首部区域:
- 前 12 个字节是首部区域, 第一个字段是『 标识符 』, 是一个 16 比特的数, 用以标识该查询. 这个标识符会被复制到查询的回答报文中, 客户可以用它来匹配发出的请求和响应;
- 后面是若干个『 标志位 』:
- 『 查询/回答 』标志位, 指出报文是查询报文, 还是回答报文;
- 『 权威 』标志位, 指出回答是否从权威 DNS 服务器发出;
- 『 希望递归 』标志位, 表示该 DNS 服务器没有某记录, 希望之星递归查询;
- 『 递归可用 』标志位, 表示该 DNS 服务器支持递归查询;
- 再之后是 4 个『 关于数量的字段 』, 用以指出首部区域后面四个区域中, 分别包含的信息数量;
- 问题区域:
- 包含正在进行的查询信息, 内容有:
- 名字字段: 指出正在被查询的主机名;
- 类型字段: 指出关于该主机名要询问的问题类型;
- 包含正在进行的查询信息, 内容有:
- 回答区域:
- 包含了对最初请求的名字的资源记录;
- 回答区域中可以包含多条资源记录;
- 因此一个主机名也能有对个 IP 地址;
- 权威区域:
- 包含了其他权威服务器的记录;
- 附加信息区域:
- 包含了其他有帮助的记录;
- 🌰 例如:
- 对于一个 MX 请求的回答报文中的回答区域里包含一个资源记录, 该记录提供了邮件服务器的规范主机名;
- 该附加区域包含一个类型 A 的记录, 其提供了用于该邮件服务器的规范主机名的 IP 地址;
下图 👇 展示了使用 nslookup 程序向 IP 地址为 8.8.8.8 的 DNS 服务器查询 www.baidu.com 主机名的结果:
8.8.8.8是谷歌提供的公用 DNS 服务器;

# 在 DNS 数据库中插入记录
假如你有一个主机, 上面运行着一个 Web 服务器, 你想要给它弄一个域名:
- 第一步, 先去『 注册登记机构 register 』注册一个想要的域名. 注册登记机构是一个商业实体, 其能帮你创建域名;
- 🌰 例如
garrik.com
- 🌰 例如
- 市面上有很多的注册登记机构, 它们都在『 因特网名字和地址分配机构 ICANN 』获得了授权;
- 当你向注册登记机构注册域名时, 需要向该机构提供你的基本和辅助『 权威 DNS 服务器 』的主机名和 IP 地址;
- 🌰 例如,
dns1.garrik.com, 212.212.212.1和dns2.garrik.com, 212.212.212.2
- 🌰 例如,
- 注册登记机构会为这两个权威 DNS 服务器生成对应的『 类型 NS 』和『 类型 A 』记录, 并且写入
.com的中『 顶级域 DNS 服务器, TLD 』 - 同时, 你还要将用于 Web 服务器
www.garrik.com的『 类型 A 』记录写入你的『 权威 DNS 服务器 』中;
# P2P
上面 👆 所讲述的应用都采用的 "客户 - 服务器" 架构, 这种应用极大地依赖于服务提供商的服务器;
前面说过采用 P2P 体系架构的应用, 成对的间歇连接的主机 (对等方) 彼此间直接连接. 对于服务提供商的服务器依赖最小;
下面 👇 介绍两种采用 P2P 架构设计的应用:
# P2P 文件分发
- 『 文件分发应用 』, 即是从一个单独的服务器开始, 向大量的主机分发一个文件;
- 对于『 客户 - 服务器架构 』的文件分发应用, 该服务器必须向每个主机单独发送该文件的一个副本;
- 对于『 P2P 架构 』的文件分发应用, 每个接收到了文件数据的对等方能够协助服务器, 向其他对等方分发该接收到的文件部分;
下面 👇 我们就来通过比较这两种架构下, 分发文件所花费的时间, 来展示一下 P2P 应用的扩展性.
# P2P 的扩展性
🤔 假设:
- 表示服务器接入链路的上传速度;
- 表示第 对等方接入链路的上传速度;
- 表示第 对等方接入链路的下载速度;
- 表示被分发的文件比特长度;
- 表示对等方的数量;
- 『 分发时间 distribution time 』指的是 个对等方, 都接收到了要分发的文件副本所花的时间;

客户 - 服务器架构:
- 服务器必须向 个对等方分别传输此文件的一个副本, 所以总共需要传输 个比特. 服务器的上传速率为 , 所以分发时间至少为
- 令 为具有最小下载速度的对等方, 即
- 具有最小下载速度的对等方需要不少于 秒的时间去获得整个文件. 因此最小分发时间至少为
- 因此得到, 总共分发时间:
P2P 架构:
- 在分发开始时只有服务器具有文件. 服务器经其他链路至少分发该文件每个比特一次. 因此最小分发时间至少为
- 具有最小下载速度的对等方获取完所有的文件数据至少需要 , 如果其时间大于 , 则最小分发时间为
- 在 P2P 架构中, 对等方之间可以互相分发他们获得的数据的. 则整个系统的总上传能力等于服务器上传速度, 加上每个对等方的上传速度, 即
- 系统总共要向 个对等方分别上传 比特的数据, 总共 个比特. 所需时间至少为
- 上面的三种时间进行比较, 因此得到总共分发时间:
下图 👇 表示出了随着 的增大, 两种架构分发时间的涨势:

可以看出, 随着对等方数量的增大, P2P 架构的分发系统, 所花的时间并没有增长很多, 它的服务能力是自扩展的. 原因是, 对等方即使消费者, 也是服务器提供者.
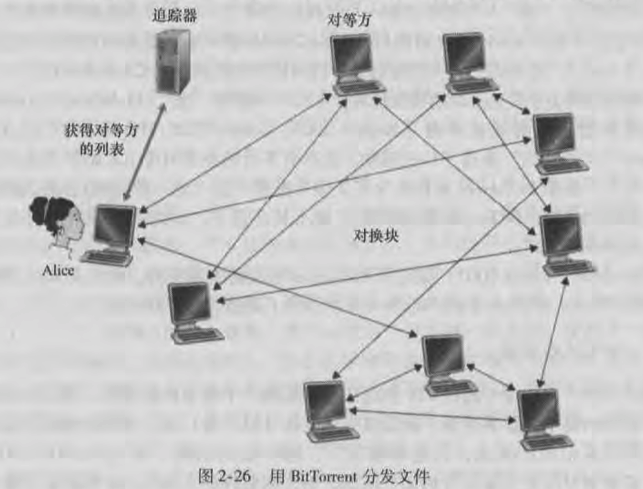
# BitTorrent 协议
- BitTorrent 是目前流行的文件分发 P2P 协议;
- 在 BitTorrent 术语中, 参与一个特定文件分发的所有对等方的集合,被称为一个『 洪流 torrent 』
- 在一个洪流中对等方彼此下载和上传等长度的『 文件块 chunk 』
- 每个洪流中有一个基础设施节点称为『 追踪器 tracker 』
- 当有新的对等方加入洪流时,他向追踪器注册自己并周期性的通知追踪器他仍在洪流中。通过这种方式,追踪器跟踪洪流中的所有对等方;
- 同时, 当有新的对等方加入洪流时, 追踪器随机分配对等方集合的自己给这个新加入对等方,新加入对等方尝试与这个子集上的对等方机建立并行的 TCP 连接;
- 成功创建 TCP 连接的对等方称为『 临近对等方 』, 整个洪流中的对等方可以随时加入或退出,所以一个对等方的临近对等方将随时间而改变;
- 对等方会周期性的询问他的临近对等方他们所具有的文件块,并向他们请求自己没有的文件块;
- 在对等方决定该向他的邻居请求哪些块时,采用了『 最稀缺优先 rarest first 』技术;
- 核心思想是, 针对他没有的块,向他的邻居中请求最稀缺的 块,也就是那些在他的邻居中副本数量最少的文件块;
- 通过这种方式,最稀缺文件块得到更为迅速的重新分发,可以均衡每个块在洪流中的副本数量;
- 在对等方决定响应哪些邻居的请求时, 采用了『 对换算法 』
- 核心思想是, 对等方根据当前能够以最高速率向他提供数据的邻居给出其优先权;
- 对等方持续性的测量从每个邻居那里接收到的比特速率,并确定以最高速率流入的一个邻居集合. 这些对等方式被称为『 疏通 unchoked 』
- 而其他的相邻对等方被称为『 阻塞 』即当前对等方不会向其他的阻塞对等方发送任何块;
- 每过一段时间当前对等方随机地向它另外一个邻居发送文件块。我们称当前对等方为 A,随机选择的对等方为 B;
- 如果 A 的传输速度比 B 当前的疏通对等方的速度要快,A 就可能成为 B 的疏通. 同时从之前 B 的疏通集合中剔除掉一个最慢的对等方;
- B 这个时候也会向 A 发送文件块,如果 B 的传输速度足够快,B 也有可能成为 A 的疏通。这被称为『 对换 』
- 每隔一段时间,他们还会向新的随机对等方发送文件块,并重复上面的过程;
- 通过对换, 能够让所有对等方找到彼此互相协调的上传/下载速率;