# 链表
# 删除链表中的节点
请编写一个函数,使其可以删除某个链表中给定的节点 ( 不是末尾 )。传入函数的唯一参数为「 要被删除的节点 」。
🌰 示例:
输入:head = [4,5,1,9], node = 5
输出:[4,1,9]
解释:给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
💡 思路:
- 从链表里删除一个节点
node的最常见方法是修改之前节点的next指针,使其指向之后的节点。

- 我们无法访问我们想要删除的节点「 之前 」的节点,不能直接修改前一个节点的
next指针。但是可以将想要删除的节点的值替换为它后面节点中的值,然后删除它之后的节点。

- 因为我们知道要删除的节点不是列表的末尾,所以我们可以保证这种方法是可行的。
public void deleteNode(ListNode node) {
node.val = node.next.val;
node.next = node.next.next;
}
📝 算法性能分析:
时间 & 空间复杂度都是:。
# 删除链表中倒数第 N 个节点
给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
🌰 示例:
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.
💡 思路:
- 第一个指针从列表的开头向前移动
n步,而第二个指针将从列表的开头出发。现在,这两个指针被n - 1个结点分开。我们通过同时移动两个指针向前来保持这个恒定的间隔,直到第一个指针到达最后一个结点。此时第二个指针将指向链表末尾倒数第n个结点的前一个结点。 - 让第二个指针所引用的结点的
next指针指向该结点的下下个结点。
public ListNode removeNthFromEnd(ListNode head, int n) {
if(head == null || head.next == null) {
head = null;
return head;
}
ListNode a,b;
a = head;
b = head;
for(int i = 0; i < n; i++) {
b = b.next;
}
if(b == null) return head.next;
while(b.next != null) {
a = a.next;
b = b.next;
}
a.next = a.next.next;
return head;
}
📝 算法性能分析:
- 时间复杂度:,该算法对含有 个结点的列表进行了一次遍历。
- 空间复杂度:,我们只用了常量级的额外空间。
# 反转链表
给定一个带头结点的单链表,请将其逆序。
🌰 示例:
即如果单链表原来为
head→1→2→3→4→5→6→7逆序后变为
head→7→6→5→4→3→2→1
# 就地逆序
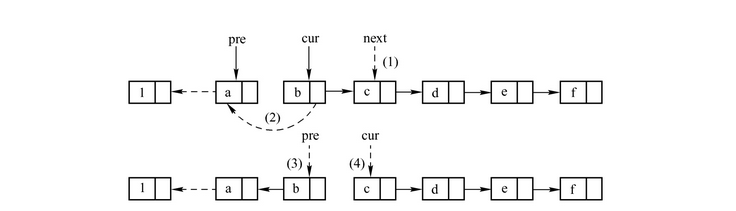
💡思路:
- 在遍历链表时,修改当前结点的
next指针的指向,让其指向它的前驱结点。为此,需要用一个指针变量来保存前驱结点的地址。 - 此外,为了在调整当前结点的
next指针的指向后还能找到后继结点,还需要另外一个指针变量来保存后继结点的地址。 - 然后从前到后一个个地进行遍历修改。
- 还需要特别注意对链表首尾结点的特殊处理。
public ListNode reverseList(ListNode head) {
// 判断链表是否为空,或者只有一个元素
if(head == null || head.next == null) {
return head;
}
ListNode pre = null; // 前驱结点
ListNode cur = null; // 当前结点
ListNode next = null; // 后驱结点
pre = head;
cur = pre.next;
pre.next = null;
while(cur.next != null) {
next = cur.next;
cur.next = pre; // cur.next 指向前驱结点
pre = cur; // 此次遍历的 cur 变成下次遍历的 pre
cur = next; // 此次遍历的 next 变成下次遍历的 cur
}
// 最后一个结点指向它的前一个结点
cur.next = pre;
// 链表的头结点指向最后一个节点
head = cur;
return head;
}
📝 算法性能分析:
- 以上这种方法只需要对链表进行一次遍历,因此,时间复杂度 为 。其中, 为链表的长度。
- 需要常数个额外的变量来保存当前结点,前驱结点,后继结点。因此,空间复杂度 为 。
# 递归法
public ListNode reverseList(ListNode head) {
// 判断链表是否为空
if(head == null) {
return head;
}
ListNode newHead = recursiveReverse(head);
return newHead;
}
private ListNode recursiveReverse(ListNode head) {
//
if(head.next == null) {
return head;
}
// 递归翻转链表,返回新链表的头结点
ListNode newHead = recursiveReverse(head.next);
ListNode newTail = head.next;
newTail.next = head;
head.next = null;
return newHead;
}
📝 算法性能分析:
- 由于递归法也只需要对链表进行一次遍历,因此,算法的时间复杂度也为 。
- 但是由于需要额外的压栈与弹栈操作,因此所需空间会更大,与「 方法 1 - 就地逆序 」相比性能会有所下降。
# 递归逆序打印链表 ( 不改变原始结构 )
void recursiveReversePrint(ListNode head) {
if(head == null) return;
recursiveReversePrint(head.next);
System.out.printf("%d ", head.val);
}
# 判断是否为回文链表
请判断一个链表是否为回文链表。
🌰 示例:
输入: 1->2->2->1
输出: true
💡 思路:
简单来想,可以将链表转化为一个数组,然后一个指针在前,一个指针在后,一个个地比较,但是这样空间复杂度为 。
假设,希望空间复杂度控制在 。
- 采用「 双指针法 」找到链表中间位置。
- 然后将后半段链表翻转。
- 一个指针指向前半段链表的 head,一个指向翻转后的后半段链表的 head。
- 一个个结点的对比。
public boolean isPalindrome(ListNode head) {
if(head == null || head.next == null) return true;
ListNode a, b, mid;
a = head;
b = head;
// 1. 使用双指针法,找到中间点
while(true) {
if(b.next == null || b.next.next == null) {
mid = a;
break;
}
a = a.next;
b = b.next.next;
}
// a 指针指向前半段链表的 head
a = head;
// 翻转后半段链表,然后 b 指针指向翻转后的 head
b = reverseLinkList(mid.next);
// 一个个的对比看是否相同
while(a != null && b != null) {
if(a.val != b.val) return false;
a = a.next;
b = b.next;
}
return true;
}
// 翻转链表
public ListNode reverseLinkList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
ListNode temp;
while(curr != null) {
temp = curr.next;
curr.next = prev;
prev = curr;
curr = temp;
}
return prev;
}
📝 算法性能分析:
- 时间复杂度:
- 空间复杂度:
# 判断是否为环形链表
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置( 索引从 0 开始 )。 如果 pos 是 -1,则在该链表中没有环。
🌰 示例:
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。

# 使用「 哈希表 」
💡 思路:
- 通过检查一个结点此前是否被访问过来判断链表是否为环形链表。
- 遍历所有结点并在哈希表中存储每个结点的引用。
- 如果当前结点为空结点
null( 即已检测到链表尾部的下一个结点 ),那么我们已经遍历完整个链表,并且该链表不是环形链表。 - 并且该链表不是环形链表。如果当前结点的引用已经存在于哈希表中,那么返回
true,即该链表为环形链表。
public boolean hasCycle(ListNode head) {
HashSet<ListNode> nodeSet = new HashSet<>();
while(head != null) {
if(nodeSet.contains(head)) return true;
else nodeSet.add(head);
head = head.next;
}
return false;
}
📝 算法性能分析:
- 时间复杂度:,对于含有 个元素的链表,我们访问每个元素最多一次。添加一个结点到哈希表中只需要花费 的时间。
- 空间复杂度:,空间取决于添加到哈希表中的元素数目,最多可以添加 个元素。
# 使用「 双指针 」
💡 思路:
- 慢指针每次移动一步,而快指针每次移动两步。
- 如果列表中不存在环,最终快指针将会最先到达尾部,此时我们可以返回
false。 - 而如果存在环,最终快慢两个指针会相遇。
public boolean hasCycle(ListNode head) {
if (head == null || head.next == null) {
return false;
}
ListNode slow = head;
ListNode fast = head.next;
while (slow != fast) {
if (fast == null || fast.next == null) {
return false;
}
slow = slow.next;
fast = fast.next.next;
}
return true;
}
📝 算法性能分析:
- 时间复杂度:
- 空间复杂度:,我们只使用了慢指针和快指针两个结点
# 从无序链表中移除重复项
给定一个没有排序的链表,去掉其重复项,并保留原顺序。
- 如原始链表为
1→3→1→5→5→7, - 去掉重复项后变为
1→3→5→7。
# 顺序删除
💡 思路:通过双重循环直接在链表上执行删除操作。外层循环用一个指针从第一个结点开始遍历整个链表,然后内层循环用另外一个指针遍历其余结点,将与外层循环遍历到的指针所指结点的数据域相同的结点删除。
public ListNode removeDuplicateNodes(ListNode head) {
if(head == null || head.next == null) return head;
ListNode outerCur, innerCur, innerPre;
outerCur = head;
while(outerCur != null) {
innerCur = outerCur.next;
innerPre = outerCur;
while(innerCur != null) {
if(innerCur.val == outerCur.val) innerPre.next = innerCur.next;
else innerPre = innerCur;
innerCur = innerCur.next;
}
outerCur = outerCur.next;
}
return head;
}
📝 算法性能分析:
- 由于这种方法采用双重循环对链表进行遍历。时间复杂度为
- 。在遍历链表的过程中,使用了常量个额外的指针变量来保存当前遍历的结点,前驱结点。空间复杂度为
# 使用 HashSet
💡 思路:
- 建立一个 HashSet。从头开始遍历链表中的所以结点。
- 如果结点内容已经在 HashSet 中,则删除此结点,继续向后遍历。
- 如果结点内容不在 HashSet 中,将此结点内容添加到 HashSet 中,继续向后遍历。
public ListNode removeDuplicateNodes(ListNode head) {
if(head == null || head.next == null) return head;
// 建立 HashSet
HashSet hashSet = new HashSet();
ListNode curNode = head;
ListNode preNode = curNode;
// 遍历链表
while(curNode != null) {
// 结点中的数字不在 HashSet 之中
if(!hashSet.contains(curNode.val)) {
hashSet.add(curNode.val);
preNode = curNode;
}
// 如果已存在,则直接跳过
else {
preNode.next = curNode.next;
}
curNode = curNode.next;
}
return head;
}
# 从有序链表中移除重复项
💡 思路:由于输入的列表已排序,因此我们可以通过将结点的值与它之后的结点进行比较来确定它是否为重复结点。如果它是重复的,我们更改当前结点的 next 指针,以便它跳过下一个结点并直接指向下一个结点之后的结点。
public ListNode deleteDuplicates(ListNode head) {
ListNode curNode = head;
while (curNode != null && curNode.next != null) {
if(curNode.val == curNode.next.val) {
curNode.next = curNode.next.next;
} else {
curNode = curNode.next;
}
}
return head;
}
# 计算两个单链表所代表的数之和
给定两个单链表,链表的每个结点代表一位数,计算两个数的和,并且返回一个新的链表来表示它们的和。
# 两个链表是逆序的

public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode result = new ListNode(0);
ListNode curl1 = l1, curl2 = l2, curResult = result, nextResult;
int vall1, vall2, sum, carry;
while(curl1 != null || curl2 != null) {
vall1 = (curl1 != null) ? curl1.val : 0;
vall2 = (curl2 != null) ? curl2.val : 0;
sum = curResult.val + vall1 + vall2;
carry = sum / 10;
curResult.val = sum % 10;
nextResult = new ListNode(carry);
if(curl1 != null) curl1 = curl1.next;
if(curl2 != null) curl2 = curl2.next;
if(curl1 == null && curl2 == null && carry == 0) {
curResult.next = null;
} else {
curResult.next = nextResult;
curResult = nextResult;
}
}
return result;
}
# 两个链表是顺序的
# 合并两个有序链表
将两个有序链表合并为一个新的有序链表并返回。
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode curMerged = new ListNode(0);
ListNode merged = curMerged;
while(l1 != null && l2 != null) {
if(l1.val <= l2.val) {
curMerged.next = l1;
l1 = l1.next;
} else {
curMerged.next = l2;
l2 = l2.next;
}
curMerged = curMerged.next;
}
curMerged.next = l1 != null ? l1 : l2;
return merged.next;
}
📝 算法性能分析:
- 时间复杂度:, 和 分别是两个链表的长度。
- 空间复杂度: 我们只需要常数的空间存放若干变量。
# 链表排序
给定一个链表进行排序。要求:
- 只能修改结点的
next,不能修改数据; - 时间复杂度控制在 ,空间复杂度为
💡 思路 采用「 归并排序 」
对数组做归并排序的空间复杂度为 ,分别由新开辟数组 和递归函数调用 组成,而根据链表特性:
- 数组额外空间:链表可以通过修改引用来更改节点顺序,无需像数组一样开辟额外空间;
- 递归额外空间:递归调用函数将带来 的空间复杂度,因此若希望达到 空间复杂度,则不能使用递归。
通过递归实现链表归并排序,有以下两个环节:
分割 cut 环节:
- 找到当前链表中点,并从中点将链表断开。
- 我们使用
fast,slow快慢双指针法,奇数个节点找到中点,偶数个节点找到中心左边的节点。 - 找到中点
slow后,执行slow.next = null将链表切断。 - cut 递归终止条件:当
head.next == null时,说明只有一个节点了,直接返回此节点。
合并 merge 环节:
- 双指针法合并。设置两指针
left,right分别指向两链表头部,比较两指针处节点值大小,由小到大加入合并链表头部,指针交替前进,直至添加完两个链表。
- 双指针法合并。设置两指针

public ListNode sortList(ListNode head) {
if(head == null) return head;
return divide(head);
}
private ListNode divide(ListNode head) {
if(head.next == null) return head;
ListNode slow = head, fast = head;
while(fast.next != null && fast.next.next != null) {
slow = slow.next;
fast = fast.next.next;
}
ListNode left = head;
ListNode right = slow.next;
slow.next = null;
return merge(divide(left), divide(right));
}
private ListNode merge(ListNode left, ListNode right) {
ListNode curMerged = new ListNode(0);
ListNode merged = curMerged;
while(left != null && right != null) {
if(left.val <= right.val) {
curMerged.next = left;
left = left.next;
} else {
curMerged.next = right;
right = right.next;
}
curMerged = curMerged.next;
}
curMerged.next = left != null ? left : right;
return merged.next;
}