# 数组
# 删除排序数组中的重复项
给定一个排序数组,你需要在「 原地 」删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
🌰 示例:
给定 nums = [0,0,1,1,1,2,2,3,3,4],
函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。
你不需要考虑数组中超出新长度后面的元素。
💡 思路:使用「 双指针法 」
因为数组是排好序的,我们可以放置两个指针 和 ,其中 是慢指针,而 是快指针。只要 我们就增加 以跳过重复项。
当我们遇到 时,跳过重复项的运行已经结束,因此我们必须把它( )的值复制到 。然后递增 ,接着我们将再次重复相同的过程,直到 到达数组的末尾为止。
public int removeDuplicates(int[] nums) {
int i = 0, j;
for(j = 1; j < nums.length; j++) {
if(nums[i] != nums[j]) { // 如果 i 和 j 指向的数字不一样,
i++; // i 就向前走一步,
nums[i] = nums[j]; // 然后把 j 指向的值赋给 i 指向的元素。
}
}
return i + 1;
}
📝 算法性能分析:
- 时间复杂度:
- 空间复杂度:
# 买股票的最佳时机
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易( 多次买卖一支股票 )。
但是,你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
🌰 示例:
输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
💡 思路:
连续比较 数组相邻元素之间的差值,如果第二个数字大于第一个数字,就代表有利润。将这些差值累加在一起,就是总利润。

从上图中,我们可以观察到 的和等于差值 所对应的连续峰和谷的高度之差。
public int maxProfit(int[] prices) {
int total = 0;
for(int i = 0; i < prices.length - 1; i++) {
if(prices[i + 1] > prices[i]) {
total += prices[i + 1] - prices[i];
}
}
return total;
}
# 旋转数组
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
🌰 示例:
# 使用额外的数组
💡 思路:
- 用一个额外的数组来将每个元素放到正确的位置上。
- 也就是原本数组里下标为 的我们把它放到 的位置。然后把新的数组拷贝到原数组中。
public void rotate(int[] nums, int k) {
int[] a = new int[nums.length];
for (int i = 0; i < nums.length; i++) {
a[(i + k) % nums.length] = nums[i];
}
for (int i = 0; i < nums.length; i++) {
nums[i] = a[i];
}
}
📝 算法性能分析:
- 时间复杂度:
- 空间复杂度:
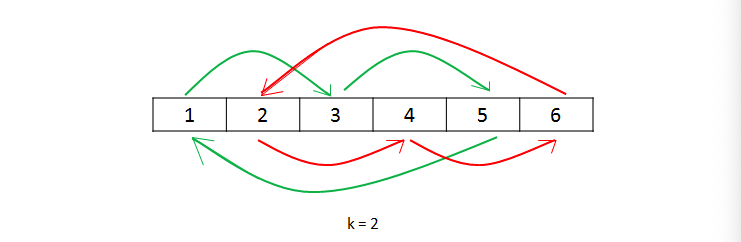
# 使用环状替换
💡 思路:
- 如果我们直接把每一个数字放到它最后的位置,但这样的后果是遗失原来的元素。因此,我们需要把被替换的数字保存在变量
temp里面。
public void rotate(int[] nums, int k) {
int n = nums.length;
int count = 0;
int currIndex, nextIndex;
int prevVal, tempVal;
k = k % n; // k 可能大于等于 n
for (int start = 0; count < n; start++) {
currIndex = start;
prevVal = nums[start];
do {
nextIndex = (currIndex + k) % n; // 找出下一个位置
tempVal = nums[nextIndex]; //
nums[nextIndex] = prevVal; // 将当前位置的值,赋给下个位置
prevVal = tempVal; //
currIndex = nextIndex; // 指向下一个位置
count++; // 移动次数 + 1
} while (start != currIndex); // 如果下一个位置是此次循环的起始位置,
// 说明 n 是 k 的整数倍,下次循环的起始位置
// 应该是上次起始位置 + 1
}
}
📝 算法性能分析:
- 时间复杂度:
- 空间复杂度:
# 存在重复元素
给定一个整数数组,判断是否存在重复元素。
如果任意一值在数组中出现至少两次,函数返回 true。如果数组中每个元素都不相同,则返回 false。
🌰 示例:
输入: [1,2,3,1]
输出: true
💡 思路:
public boolean containsDuplicate(int[] nums) {
HashSet hashSet = new HashSet();
for(int i = 0; i < nums.length; i++) {
if(hashSet.contains(nums[i])) return true;
else hashSet.add(nums[i]);
}
return false;
}
📝 算法性能分析:
- 时间复杂度:
- 空间复杂度:
# 只出现一次的数字
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
🌰 示例:
输入: [2,2,1]
输出: 1
💡 思路:使用 HashSet
public int singleNumber(int[] nums) {
HashSet<Integer> hashSet = new HashSet<>();
for(int i = 0; i < nums.length; i++) {
int value = nums[i];
if(!hashSet.contains(value)) hashSet.add(value);
else hashSet.remove(value);
}
Iterator<Integer> iterator = hashSet.iterator();
Integer result = iterator.next();
return result.intValue();
}
# 两个数组的交集
给定两个数组,编写一个函数来计算它们的交集。
输出结果中每个元素出现的次数,应与元素在两个数组中出现次数的最小值一致。
🌰 示例:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[4,9]
💡 思路:

public int[] intersect(int[] nums1, int[] nums2) {
// 先遍历长度较短的数组,可以使哈希表的所占空间尽量变小
if (nums1.length > nums2.length) {
return intersect(nums2, nums1);
}
Map<Integer, Integer> map = new HashMap<>();
// 哈希表中保存数组 1 中 "出现的数字" 和 ""出现的次数" 的映射。
for(int i = 0; i < nums1.length; i++) {
int count = map.get(nums1[i]) == null ? 1 : map.get(nums1[i]) + 1;
map.put(nums1[i], count);
}
// 用一个数组保存找到的交集
int[] intersection = new int[nums1.length];
int j = 0;
// 遍历数组 2,每找到一个在哈希表中存在的数字,就将其 "次数" 减 1。
// 如果次数仍旧大于 0 就放入数组中。
for(int i = 0; i < nums2.length; i++) {
if(map.get(nums2[i]) == null || map.get(nums2[i]) <= 0) continue;
intersection[j] = nums2[i];
j++;
map.put(nums2[i], map.get(nums2[i]) - 1);
}
return Arrays.copyOfRange(intersection, 0, j);
}
# 加一
给定一个由整数组成的非空数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
这个整数不会以零开头。
🌰 示例:
输入: [1,2,3]
输出: [1,2,4]
解释: 输入数组表示数字 123。
💡 思路:
- 由于同一个数字在两个数组中都可能出现多次,因此需要用哈希表存储每个数字出现的次数。对于一个数字,其在交集中出现的次数等于该数字在两个数组中出现次数的最小值。
- 首先遍历第一个数组,并在哈希表中记录第一个数组中的每个数字以及对应出现的次数,然后遍历第二个数组,对于第二个数组中的每个数字,如果在哈希表中存在这个数字,则将该数字添加到答案,并减少哈希表中该数字出现的次数。
- 为了降低空间复杂度,首先遍历较短的数组并在哈希表中记录每个数字以及对应出现的次数,然后遍历较长的数组得到交集。
public int[] plusOne(int[] digits) {
int carry = 0, tempCarry = 0;
int length = digits.length;
// 最后一个元素 + 1
carry = (digits[length - 1] + 1) / 10;
digits[length - 1] = (digits[length - 1] + 1) % 10;
// 从后往前计算
for(int i = digits.length - 2; i >= 0; i--) {
tempCarry = (digits[i] + carry) / 10;
digits[i] = (digits[i] + carry) % 10;
carry = tempCarry;
}
// 扩容
if(carry >= 1) {
int newArr[] = new int[length + 1];
newArr[0] = 1;
for(int i = 0; i < length; i++) {
newArr[i + 1] = digits[i];
}
return newArr;
}
return digits;
}
📝 算法性能分析:
- 时间复杂度:,其中 和 分别是两个数组的长度。需要遍历两个数组并对哈希表进行操作,哈希表操作的时间复杂度是 ,因此总时间复杂度与两个数组的长度和呈线性关系。
- 空间复杂度:,其中 和 分别是两个数组的长度。对较短的数组进行哈希表的操作,哈希表的大小不会超过较短的数组的长度。为返回值创建一个数组
intersection,其长度为较短的数组的长度。
# 移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
空间复杂度需要为
🌰 示例:
输入: [0,1,0,3,12]
输出: [1,3,12,0,0]
💡 思路:
- 使用「 双指针法 」用两个指针
i和j,第一次遍历的时候指针j用来记录当前有多少非 0元素。遍历的时候每遇到一个非 0元素就将其挪到数组前面,第一次遍历完后,j指针的下标就指向了最后一个非 0元素下标。 - 第二次遍历的时候,起始位置就从
j开始到结束,将剩下的这段区域内的元素全部置为0。
public void moveZeroes(int[] nums) {
if(nums == null) return;
int i = 0, j = 0;
// 第一次遍历的时候,找出所有非 0 的数字,把他们提到数组前面。
for(i = 0; i < nums.length; i++) {
if(nums[i] != 0) {
nums[j] = nums[i];
j++;
}
}
// 第二次遍历把末尾的元素都赋为 0 即可
for(i = j; i < nums.length; i++) {
nums[i] = 0;
}
}
📝 算法性能分析:
- 时间复杂度:
- 空间复杂度:
# 两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那两个整数,并返回他们的数组下标。
假设每种输入只会对应一个答案。同时,数组中同一个元素不能使用两遍。
🌰 示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
💡 思路:
- 使用哈希表,保存数组中每个元素的值,和对应的索引。
- 在进行迭代并将元素插入到表中的同时,检查表中是否已经存在当前元素所对应的目标元素。如果它存在,那我们已经找到了对应解,并立即将其返回。
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
// 在 map 里找看有没有匹配的元素,有的话直接返回
if (map.containsKey(complement)) {
return new int[] { map.get(complement), i };
}
// 没有的话,就将当前元素加入到 map 中
map.put(nums[i], i);
}
return new int[] {};
}
📝 算法性能分析:
- 时间复杂度:,我们只遍历了包含有
n个元素的列表一次。在哈希表中进行的每次查找只花费 的时间 - 空间复杂度:,所需的额外空间取决于哈希表中存储的元素数量,该表最多需要存储
n个元素。