# Mybatis 入门
- 框架是整个或部分系统的可重用设计;
- 它是我们软件开发中的一套解决方案。不同的框架解决不同的问题;
- 框架封装了很多细节,是开发者可以使用简单的方式去实现功能。提高了开发效率;
# 什么是持久层
- J2EE 是在 SUN 公司领导下,多家公司参与共同制定的企业级分布式应用程序开发规范;
- J2EE 中将整个应用分成三层架构:
- 表现层:User Interface;
- 业务逻辑层:Business Logic Layer;
- 数据访问层:Data Access Layer;
- 持久层又被称为 “数据访问层”。也就是用来负责对数据库的访问和操作;
- 之前我们一直使用 JDBC 作为持久层技术解决方案,用它来访问和操作数据库;
- 我们还了解过 Apache 的 BDUtils,它是对 JDBC 的简单封装;
WARNING
注意:J2EE 的三层架构和 MVC 设计模式是有区别的:
- 相同点:在 MVC 和三层架构中,视图层都用来展示数据给用户;
- 不同点:
- MVC 中,Model 层中包含了 “业务逻辑” 和 “数据库代码”;
- 三层架构中,数据访问层只用来处理和数据库相关操作;
- 三层架构中,业务逻辑层处理业务逻辑;
- 三层架构的 “业务逻辑层” + “数据访问层” = MVC 的 Model 层;
- MVC 中的 Controller 主要负责,告诉 Model 处理什么数据,然后告诉 View 展示什么数据;
- 🌰 拿用户登录举例:
- View:用户在网页访问到登录的 HTML 页面,输入用户名和密码,点击登录,发送给服务器一条 POST 请求;
- Controller:POST 请求被服务器的 Servlet 处理,拿出请求中的用户名和密码参数,然后传递给对应的 Service 方法;
- Model:Service 方法中,拿用户名和密码去数据库进行查找和比对:
- 匹配成功:把数据库中这个用户的其他信息查询出来,然后创建 User 对象,返回给 Servlet;
- 匹配失败:返回失败信息给 Servlet;
- Controller:Servlet 拿到返回后,再对浏览器进行响应;
- View:浏览器通过拿到的响应,绘制页面;
# 什么是 Mybatis
- MyBatis 几乎可以代替 JDBC,是一个支持普通 SQL 查询,存储过程和高级映射的,基于 Java 的持久层框架;
- MyBatis 对 JDBC 进行了封装,屏蔽了 JDBC API 的底层访问细节,使程序对于数据库的访问和操作更加简便;
- MyBatis 使用了 ORM 思想实现了对结果集的封装;
- ORM:Object Relational Mapping 对象关系映射;
- 把数据库表和实体类,数据库表中字段和实体类的属性对应起来。让我们可以通过操作实体类就实现操作数据库表;
# 第一个 Mybatis 实例
👇 下面先来看一下如何去使用 Mybatis:
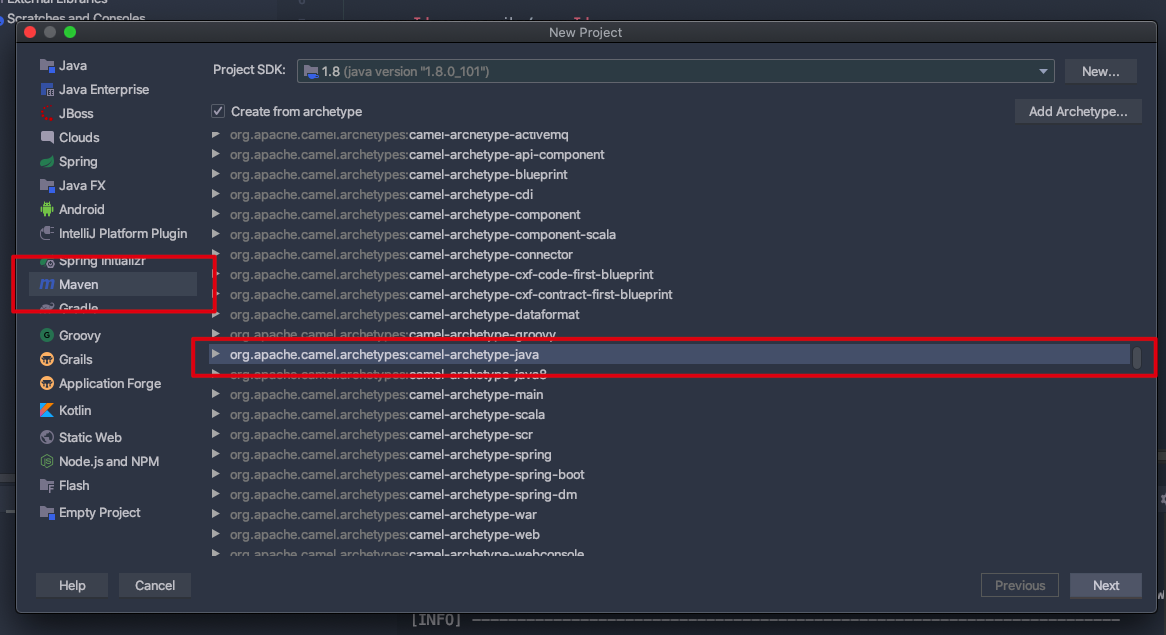
# 创建项目
- 用 IDEA 编译器;
- 使用 Maven 创建一个空的 Java 项目
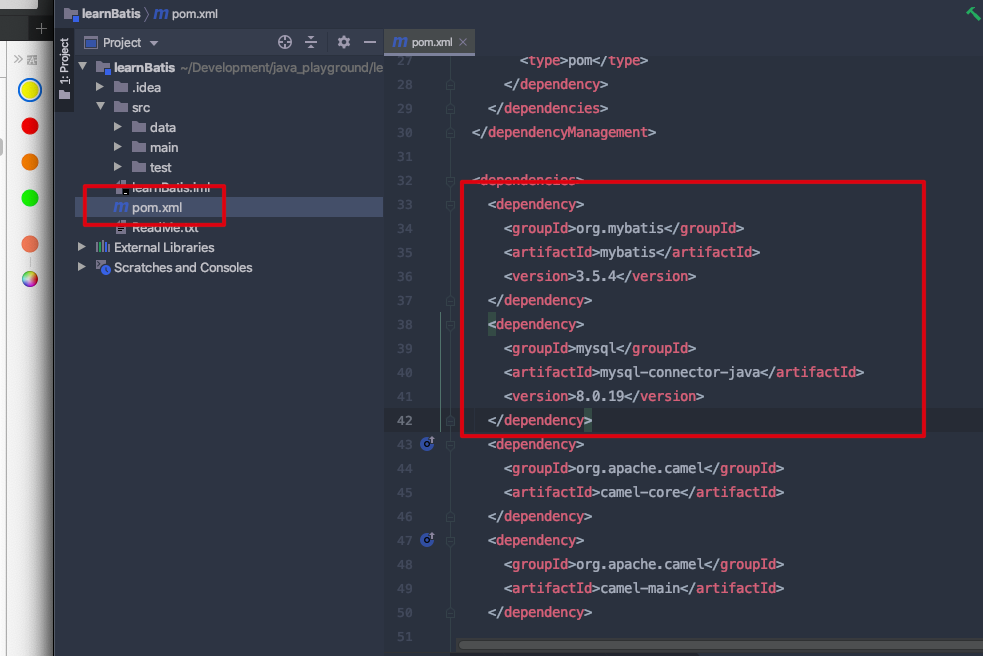
# 引入依赖
- 在项目目录中的
pom.xml文件中引入依赖;- mybatis
- mysql
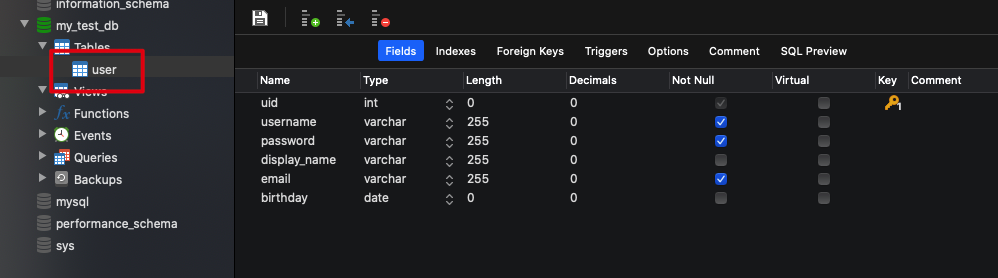
# 创建用户表
- 在数据库中创建用户表 User;
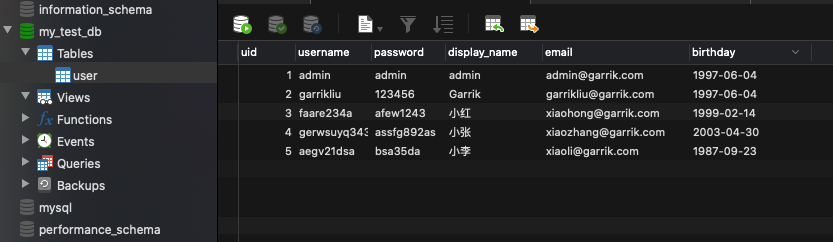
- 之后填入一些数据:
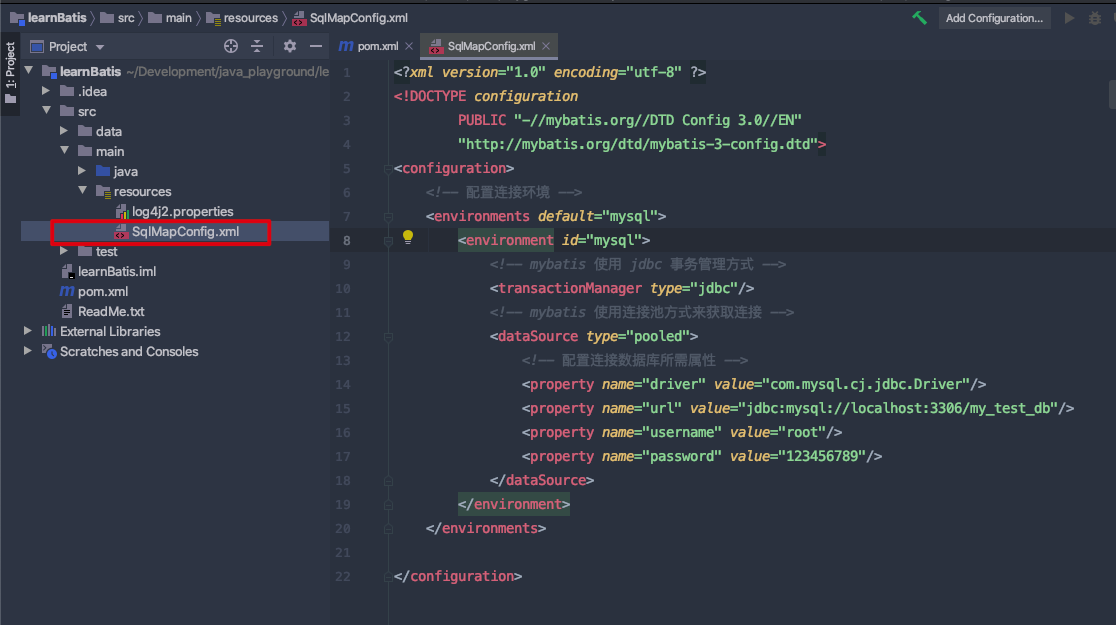
# 配置 Mybatis
- 在项目目录下的
/src/main/resources目录中创建SqlMapConfig.xml文件,作为 Mybatis 的配置文件;
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 配置连接环境,默认使用 mysql -->
<environments default="mysql">
<!-- 配置 mysql 数据库的连接 -->
<environment id="mysql">
<!-- mybatis 使用 jdbc 事务管理方式 -->
<transactionManager type="jdbc"/>
<!-- mybatis 使用连接池方式来获取连接 -->
<dataSource type="pooled">
<!-- 配置连接数据库所需属性 -->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/my_test_db"/>
<property name="username" value="root"/>
<property name="password" value="123456789"/>
</dataSource>
</environment>
</environments>
</configuration>
# 创建 User 实体类
- Mybatis 使用 ORM 对象关系映射的思想,实现了对查询结果集的封装;
- 数据表会对应一个实体类;
- 将数据表中的列名,和实体类的属性是一一对应的;
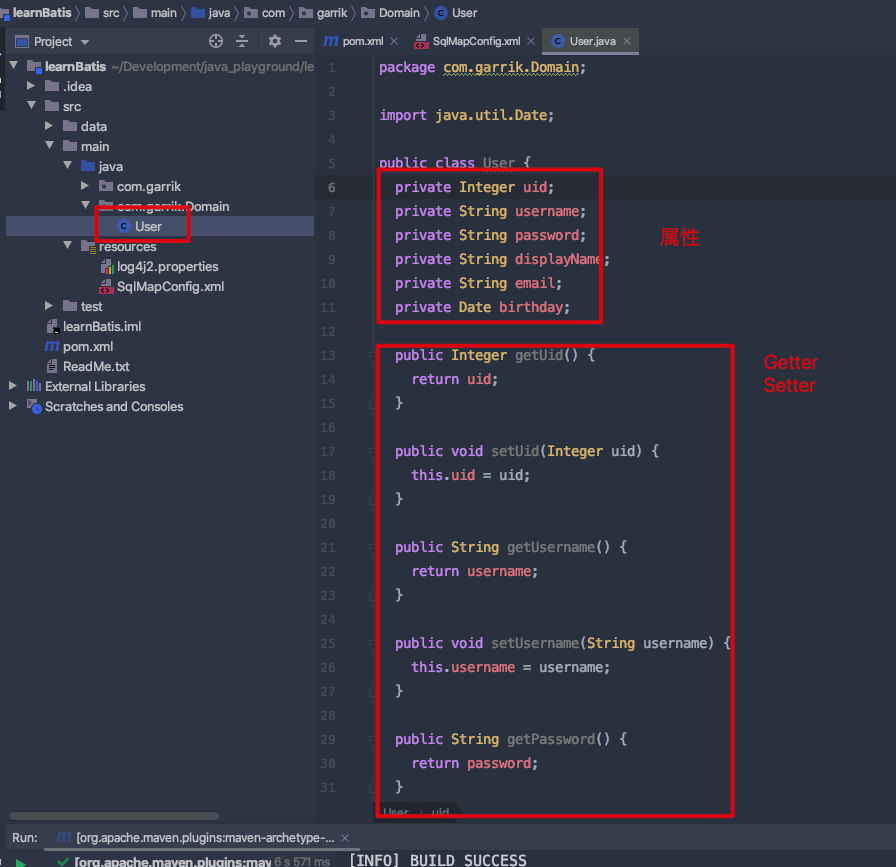
- 在
com.garrik.Domain包下,创建实体类 User; - 类里面按照数据表的列名,创建私有属性;
- 并且为所有属性创建 Getter / Setter 方法;
# 创建 User 类相关操作的接口类
在实际项目中,针对用户数据表我们会有很多 CRUD 操作;
- 在之前使用 JDBC 时,我们会先创建 DAO 接口类,在里面定义好所有需要的方法接口;
- 然后再去实现 DAO 接口;
- 在开发业务逻辑时,只需要使用 DAO 实现类,就可以完成增删改查的操作;
在 MyBatis 中,我们也用类似的思想;
但我们只需要定义好接口,接口的实现类 Mybatis 会帮我去做;
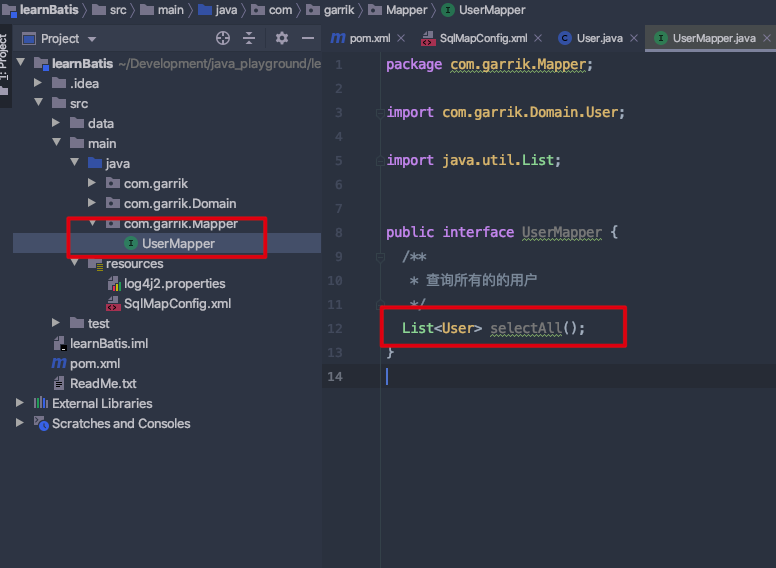
在
com.garrik.Mapper包下,创建UserMapper类;在里面定义一个接口
selectUser。我们希望它可以查询所有的用户,然后放到一个集合里面返回;
- 在 Mybatis 中,一种习惯是用 Mapper 作为接口类,和接口类对应的 XML 映射文件的后缀;
- 但是用别的后缀名称也无所谓,例如 DAO 也是可以的;
# 创建接口类对应的 Mapper 映射文件
在 Mybatis 中,接口类需要有一个对应的映射文件;
里面定义了每个接口应该执行什么样的 SQL 语句;
以及定义返回的结果集的类型;
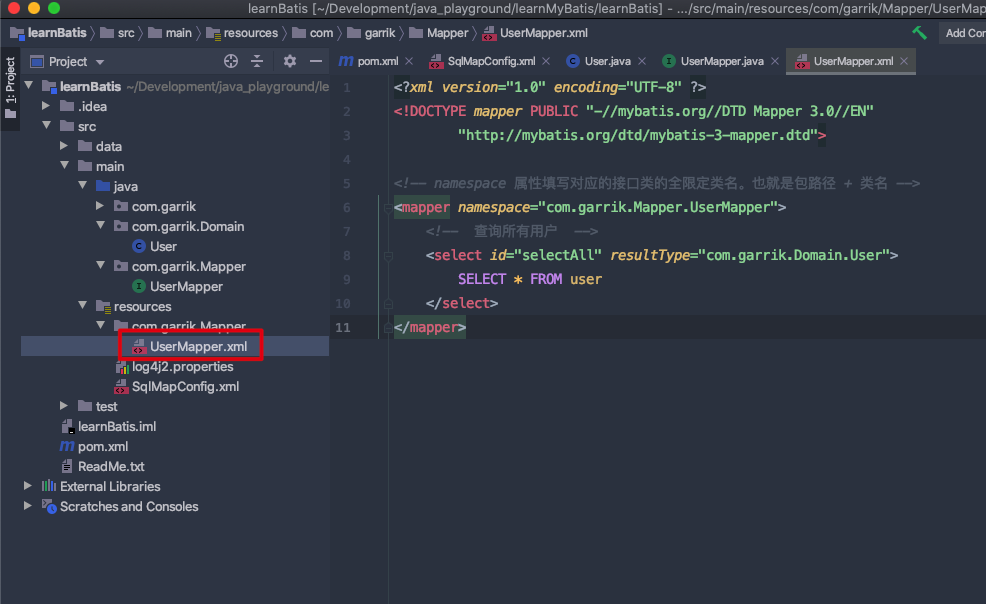
在
src/main/resources目录下创建com/garrik/Mapper目录;然后再在目录下创建
UserMapper.xml文件;
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace 属性填写对应的接口类的全限定类名。也就是包路径 + 类名 -->
<mapper namespace="com.garrik.Mapper.UserMapper">
<!-- 查询所有用户 -->
<select id="selectAll" resultType="com.garrik.Domain.User">
SELECT * FROM user
</select>
</mapper>
<mapper>元素内的namespace内填写所对应接口类的 “全限定名称”。也就是接口类的 “包路径” + “类名”;<select>元素里定义了一个 SQL 的 SELECT 查询;<select>元素的 id 属性是值为,接口类的对应的方法名;resultType属性定义返回值的类型。此处就是实体类 User 的全限定名称;
# 在 Mybatis 配置文件中,配置映射文件
- 在写完了
UserMapper.xml映射文件后; - 我们还要把新加的映射,配置到之前写的 Mybatis 配置文件中;
- 在
SqlMapConfig.xml文件中加上如下标签;
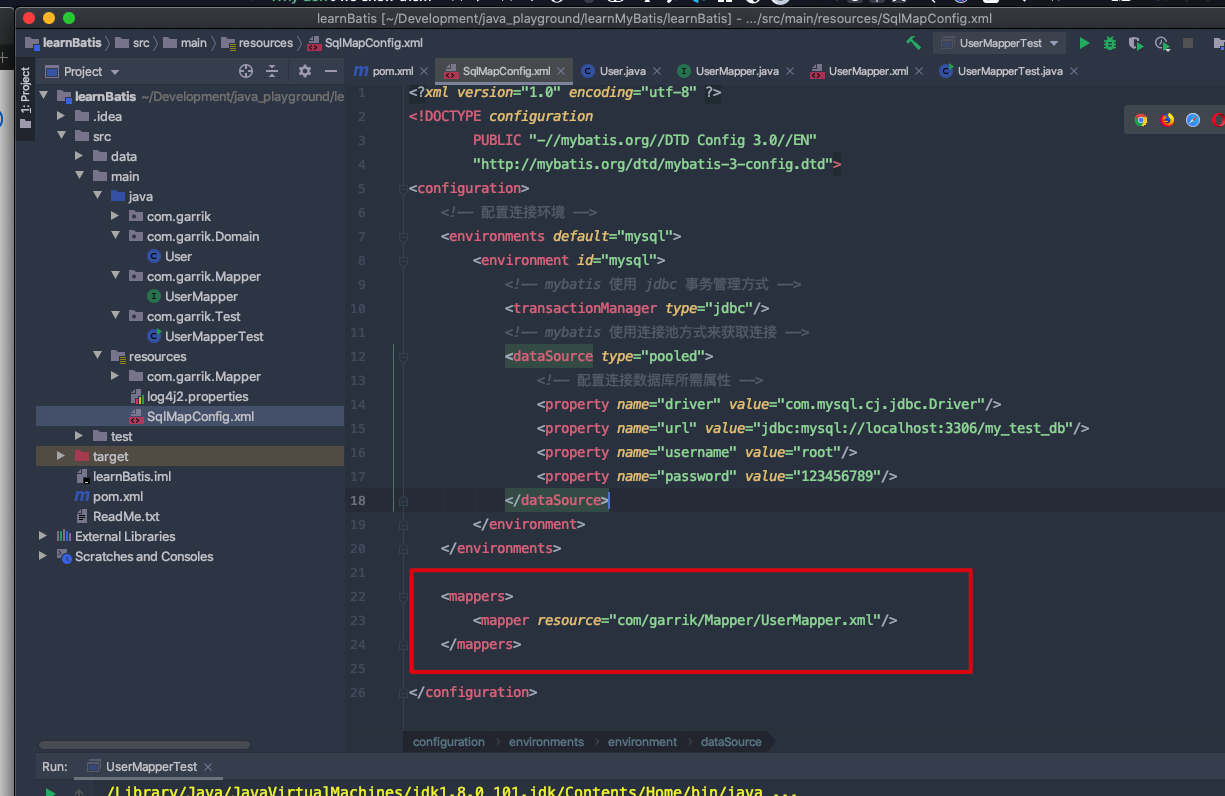
- 注意
<mapper>的resource属性后写的是 “目录路径” 不是 “包路径”。需要用/表示目录层级关系;
# 编写测试类,来执行查询
- 接下来就可以进行测试刚刚配置好的方法了;
// 读取配置文件
InputStream in = Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
// 创建一个 SqlSession 对象
SqlSessionFactory factory = builder.build(in);
SqlSession session = factory.openSession();
// 获取 Mybatis 帮你创建的接口实现类
UserMapper userMapper = session.getMapper(UserMapper.class);
// 调用方法,获取结果
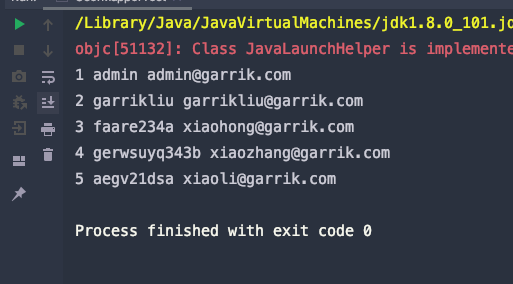
List<User> users = userMapper.selectAll();
for (User user : users) {
System.out.println(user.getUid() + " " + user.getUsername() + " " + user.getEmail());
}
// 关闭 sqlsession,关闭 InputStream
session.close();
in.close();
- 通过 Resources 实例类,来读取 Mybatis 配置文件;
- 然后使用 SqlSessionFactoryBuilder 来用刚刚读取的配置文件,创建 SqlSessionFactory 工厂对象,创建时它会在内部对配置进行解析;
- 之后通过工厂对象创建一个 SqlSession 实例;
- 将接口类的字节码,传入到实例的
getMapper方法,可以获取到接口的实现类; - 之后就能使用刚刚定义的
selectAll方法了; - 下面 👇 是调用结果;
# MyBatis XML 方式的基本用法
- MyBatis 使用 Java 的动态代理可以直接通过接口来调用相应的方法,不需要提供接口的实现类;
- 接口可以配合 XML 使用,也可以配合注解来使用;
- XML 可以单独使用,但是注解必须在接口中使用;
# 一个简单的权限控制需求
以下 👇 拿一个简单的权限控制需求来作为示例:
- 一个用户拥有若干角色;
- 一个角色拥有若干权限(权限就是对某个资源的某种操作,增删改查);
- 这样就构成了 “用户-角色-权限” 的授权模型;
- 模型中,用户与角色之间、角色与权限之间,一般是多对多的关系;

# 创建数据库
-- ----------------------------
-- Table structure for sys_role
-- ----------------------------
DROP TABLE IF EXISTS `sys_role`;
CREATE TABLE `sys_role` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '角色ID',
`role_name` varchar(50) DEFAULT NULL COMMENT '角色名',
`enabled` int(11) DEFAULT NULL COMMENT '有效标志',
`create_by` bigint(20) DEFAULT NULL COMMENT '创建人',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='角色表';
-- ----------------------------
-- Records of sys_role
-- ----------------------------
INSERT INTO `sys_role` VALUES ('1', '管理员', '1', '1', '2016-04-01 17:02:14');
INSERT INTO `sys_role` VALUES ('2', '普通用户', '1', '1', '2016-04-01 17:02:34');
-- ----------------------------
-- Table structure for sys_user
-- ----------------------------
DROP TABLE IF EXISTS `sys_user`;
CREATE TABLE `sys_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`user_name` varchar(50) DEFAULT NULL COMMENT '用户名',
`user_password` varchar(50) DEFAULT NULL COMMENT '密码',
`user_email` varchar(50) DEFAULT 'test@mybatis.tk' COMMENT '邮箱',
`user_info` text COMMENT '简介',
`head_img` blob COMMENT '头像',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1035 DEFAULT CHARSET=utf8 COMMENT='用户表';
-- ----------------------------
-- Records of sys_user
-- ----------------------------
INSERT INTO `sys_user` VALUES ('1', 'admin', '123456', 'admin@mybatis.tk', '管理员用户', 0x1231231230, '2016-06-07 01:11:12');
INSERT INTO `sys_user` VALUES ('1001', 'test', '123456', 'test@mybatis.tk', '测试用户', 0x1231231230, '2016-06-07 00:00:00');
-- ----------------------------
-- Table structure for sys_privilege
-- ----------------------------
DROP TABLE IF EXISTS `sys_privilege`;
CREATE TABLE `sys_privilege` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '权限ID',
`privilege_name` varchar(50) DEFAULT NULL COMMENT '权限名称',
`privilege_url` varchar(200) DEFAULT NULL COMMENT '权限URL',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8 COMMENT='权限表';
-- ----------------------------
-- Records of sys_privilege
-- ----------------------------
INSERT INTO `sys_privilege` VALUES ('1', '用户管理', '/users');
INSERT INTO `sys_privilege` VALUES ('2', '角色管理', '/roles');
INSERT INTO `sys_privilege` VALUES ('3', '系统日志', '/logs');
INSERT INTO `sys_privilege` VALUES ('4', '人员维护', '/persons');
INSERT INTO `sys_privilege` VALUES ('5', '单位维护', '/companies');
-- ----------------------------
-- Table structure for sys_user_role
-- ----------------------------
DROP TABLE IF EXISTS `sys_user_role`;
CREATE TABLE `sys_user_role` (
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`role_id` bigint(20) DEFAULT NULL COMMENT '角色ID'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户角色关联表';
-- ----------------------------
-- Records of sys_user_role
-- ----------------------------
INSERT INTO `sys_user_role` VALUES ('1', '1');
INSERT INTO `sys_user_role` VALUES ('1', '2');
INSERT INTO `sys_user_role` VALUES ('1001', '2');
-- ----------------------------
-- Table structure for sys_role_privilege
-- ----------------------------
DROP TABLE IF EXISTS `sys_role_privilege`;
CREATE TABLE `sys_role_privilege` (
`role_id` bigint(20) DEFAULT NULL COMMENT '角色ID',
`privilege_id` bigint(20) DEFAULT NULL COMMENT '权限ID'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='角色权限关联表';
-- ----------------------------
-- Records of sys_role_privilege
-- ----------------------------
INSERT INTO `sys_role_privilege` VALUES ('1', '1');
INSERT INTO `sys_role_privilege` VALUES ('1', '3');
INSERT INTO `sys_role_privilege` VALUES ('1', '2');
INSERT INTO `sys_role_privilege` VALUES ('2', '4');
INSERT INTO `sys_role_privilege` VALUES ('2', '5');
# 创建实体类
对应着数据表,创建出它们的实体类;
下面 👇 给出实体类 SysUser 的例子:
package com.garrik.Domain;
import java.util.Date;
/** 用户表 */
public class SysUser {
/** 用户ID */
private Long id;
/** 用户名 */
private String userName;
/** 密码 */
private String userPassword;
/** 邮箱 */
private String userEmail;
/** 简介 */
private String userInfo;
/** 头像 */
private byte[] headImg;
/** 创建时间 */
private Date createTime;
// 省略掉 Getter 和 Setter
}
- Java 实体类中属性的命名方式习惯采用 “驼峰命名法”;
- 数据表中的列名习惯采用 “下划线命名法”;
- 在后面我们需要配置它们之间的映射关系;
- 实体类中属性的数据类型不要使用基本类型;
- 🌰
private int age默认情况下age的值为 0。当使用age属性时,它总是有一个值; - 某些情况下,无法实现
age为null。这样age != null判断总是为true,可能会发生意外的 BUG;
- 🌰
# SELECT
- 在开发业务时,数据库查询是很常见的一类操作;
- 在之前使用 JDBC 时,要手动对结果集进行处理,将结果映射到具体的对象中去;
- 使用 MyBatis 时,只需要在 XML 中添加一个
select元素,写一个 SQL,再 做一些简单的配置,就可以将查询的结果直接映射到对象中; - 下面 👇 让我们对 SysUser 实体类,进行一些查询操作;
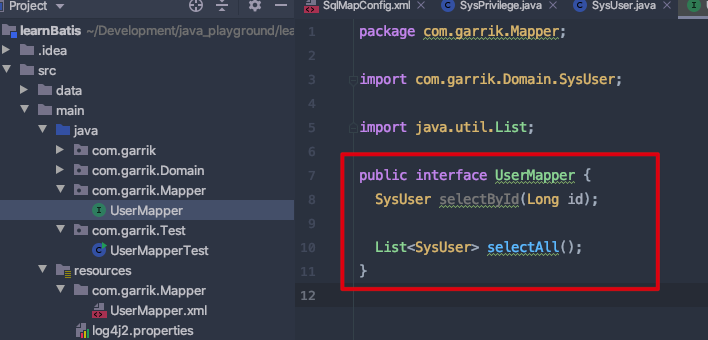
# 定义接口
- 假设我们要实现:
- 通过 id 查询用户操作;
- 查询所有用户操作;
- 第一步,先定义好接口类;
- 在 Mapper 包下面创建
UserMapper
# 编写映射文件
- 第二步,编写接口类对应的映射配置文件;
- 使用
<select>标签来映射 SQL 查询语句;
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.garrik.Mapper.UserMapper">
<!-- 配置实体类属性和查询结果列的对应关系 -->
<resultMap id="userMap" type="com.garrik.Domain.SysUser">
<id property="id" column="id"/>
<result property="userName" column="user_name"/>
<result property="userPassword" column="user_password"/>
<result property="userEmail" column="user_email"/>
<result property="userInfo" column="user_info"/>
<result property="headImg" column="head_img" jdbcType="BLOB"/>
<result property="createTime" column="create_time" jdbcType="TIMESTAMP"/>
</resultMap>
<!-- 根据 id 查询用户 -->
<select id="selectById" resultMap="userMap">
SELECT *
FROM sys_user
WHERE id = #{id}
</select>
<!-- 查询所有的用户 -->
<select id="selectAll" resultType="com.garrik.Domain.SysUser">
SELECT id AS id,
user_name AS userName,
user_password AS userPassword,
user_email AS userEmail,
user_info AS userInfo,
head_img AS headImg,
create_time AS createTime
FROM sys_user
</select>
</mapper>
<mapper>标签的namespace的属性值定义其所关联的 “接口类” 的 “全限定名称”;<select>标签的id的属性值为其对应的 “接口方法名”;<select>标签内部是 SQL 查询语句;#{id}是 SQL 中使用的预编译参数的一种方式,大括号中的 id 是传入的参数名;
上面 👆 对于两个方法,<select> 标签里面的内容略有不同,我们来详细看一下:
- 首先,因为数据表的列名采用 “下划线命名法”;
- 实体类的属性名采用 “驼峰命名法”;
- 所以命名上是不同的;
- 我们需要在配置时,定义查询结果列的名称,和实体类的属性的映射关系;
<!-- 配置实体类属性和查询结果列的对应关系 -->
<resultMap id="userMap" type="com.garrik.Domain.SysUser">
<result property="id" column="id"/>
<result property="userName" column="user_name"/>
<result property="userPassword" column="user_password"/>
<result property="userEmail" column="user_email"/>
<result property="userInfo" column="user_info"/>
<result property="headImg" column="head_img" jdbcType="BLOB"/>
<result property="createTime" column="create_time" jdbcType="TIMESTAMP"/>
</resultMap>
<!-- 根据 id 查询用户 -->
<select id="selectById" resultMap="userMap">
SELECT *
FROM sys_user
WHERE id = #{id}
</select>
- 通过
<resultMap>设置返回结果集的类型,实体类属性与查询结果列的对应关系; id属性定义<resultMap>的名称。<select>通过这个名称,在resultMap属性中进行引用;type属性定义查询结果集所映射到的实体类;<result>标签中通过property和column两个属性来表示 “实体类属性”,和 “查询结果集列名” 的对应关系;<result>标签里的jdbcType属性定义当前列对应的 “数据库数据类型”- 由于数据库对于时间数据,分为 date, time, datetime 类型,但是 Java 中一般都是 java.util.Date 类型;
- 为了让 Mybatis 知道当前实体类的属性,映射到数据库中是什么数据类型。我们需要定义
jdbcType属性;
<!-- 查询所有的用户 -->
<select id="selectAll" resultType="com.garrik.Domain.SysUser">
SELECT id AS id,
user_name AS userName,
user_password AS userPassword,
user_email AS userEmail,
user_info AS userInfo,
head_img AS headImg,
create_time AS createTime
FROM sys_user
</select>
- 另一种方法是,通过
resultType直接指定返回结果集映射的实体类; - 在 SQL 语句中,为所有列名和属性名不一致的列,通过
AS设置别名。别名需要设置为对应的实体类属性名; - 这样查询结果的列名,和实体类的属性名一致了;
除此之外,还有一种方法是:
- Mybatis 提供一个全局属性
mapUnderscoreToCamelCase; - 通过配置这个属性为
true,可以自动将以下画线方式命名的数据库列映射到 Java 对象的驼峰式命名的属性中; - 想要使用该功能,需要在 MyBatis 的配置文件中增加如下配置:
<settings>
<setting name="mapUnderscoreToCamelCase" value="true" />>
</settings>
这样配置完,上面的 selectAll 代码就可以写成这样:
<!-- 查询所有的用户 -->
<select id="selectAll" resultType="com.garrik.Domain.SysUser">
SELECT id,
user_name,
user_password,
user_email,
user_info,
head_img,
create_time
FROM sys_user
</select>
# 在 Mybatis 配置文件中配置映射关系
- 我们还需要在 Mybatis 配置文件中的
<mappers>元素中配置所有的 Mapper; - 之前我们使用的是下面这种配置方式:

- 需要将所有映射文件一一列举出来,如果增加了新的映射文件,还需要在此处进行配置,操作起来比较麻烦;
- 另一种简便的配置方式如下:
<mappers>
<package name="com.garrik.Mapper"/>
</mappers>
- 这种配置方式会先查找
com.garrik.Mapper包下所有的接口,循环对接口进行如下操作:- 判断接口对应的命名空间是否已经存在,如果存在就抛出异常,不存在就继续进行接下来的操作;
- 加载接口对应的 XML 映射文件,将接口全限定名转换为路径;
- 例如,将接口
tk.mybatis.simple.mapper.UserMapper转换为tk/mybatis/simple/mapper/UserMapper.xml
- 例如,将接口
- 然后搜索对应的 XML 资源,如果找到就解析 XML;
- 处理接口中的注解方法;
# 多表查询
- 在实际业务中,会经常遇到多表关联查询;
- 关联查询结果的类型也会有多种情况;
第一种:返回结果只包含一个数据表的信息:
- 假设我们想根据用户 id 获取用户拥有的所有角色;
- 需要查询 sys_user、 sys_role 和 sys_user_role 这 3 个表;
- 该方法写在任何一个对应的 Mapper 接口中都可以;
- 下面将这个方法写到 UserMapper 中;
<!-- 通过用户 id 查询用户所拥有的角色 -->
<select id="selectRolesByUserId" resultType="com.garrik.Domain.SysRole">
SELECT r.id,
r.role_name AS roleName,
r.enabled,
r.create_by AS createBy,
r.create_time AS createTime
FROM sys_user u
INNER JOIN sys_user_role ur on u.id = ur.user_id
INNER JOIN sys_role r on ur.role_id = r.id
WHERE u.id = #{userId}
</select>
- 虽然这个多表关联的查询中涉及了 3 个表,但是返回的结果只有 sys_role 表中的信息;
- 所以直接使用 SysRole 作为返回值类型即可;
第二种:返回的结果包含多个数据表的信息:
- 以第一种情形为基础;
- 假设查询的结果不仅要包含 sys_role 中的信息,还要包含当前用户的部分信息;
- 可以直接在 SysRole 实体类中增加一个类型为 SysUser 的实例属性;
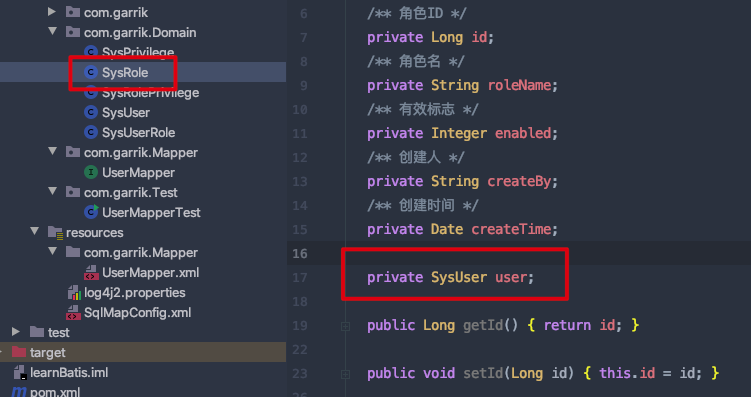
- 然后修改 XML 中的 selectRolesByUserId 方法;
- 设置别名的时候,使用的是 “user.属性名”;
- user 是 SysRole 中刚刚增加的属性。userName 和 userEmail 是 SysUser 对象中的属性;
- 通过这种方式可以直接将值赋给 user 字段中的属性;
<!-- 通过用户 id 查询用户所拥有的角色 -->
<select id="selectRolesByUserId" resultType="com.garrik.Domain.SysRole">
SELECT r.id,
r.role_name AS roleName,
r.enabled,
r.create_by AS createBy,
r.create_time AS createTime,
u.user_name AS "user.userName",
u.user_email AS "user.userEmail"
FROM sys_user u
INNER JOIN sys_user_role ur on u.id = ur.user_id
INNER JOIN sys_role r on ur.role_id = r.id
WHERE u.id = #{userId}
</select>
# INSERT
# 一个简单的插入示例
下面 👇 实现一个插入新用户的功能;
- 通过
<insert>标签来定义插入操作; - 先在 UserMapper 接口类中,新增方法
int insert(SysUser sysUser); - 然后在 UserMapper.xml 添加如下代码:
<insert id="insert">
INSERT INTO sys_user (id, user_name, user_password, user_email, user_info, head_img, create_time)
VALUES (#{id}, #{userName}, #{userPassword}, #{userEmail}, #{userInfo}, #{headImg, jdbcType=BLOB},
#{createTime, jdbcType=TIMESTAMP})
</insert>
#{属性名}可以从参数中取出其对应属性的值。在这里我们的参数是 SysUser 类型的对象;
之后编写测试代码:
try {
// 创建一个用户实例
SysUser user = new SysUser();
user.setId((long) 2);
user.setUserName("Garrik");
user.setUserPassword("123456");
user.setUserEmail("garrikliu@gmail.com");
user.setUserInfo("测试用户");
user.setHeadImg(null);
user.setCreateTime(new Date());
int result = userMapper.insert(user);
System.out.println(result);
if (result > 0) {
sqlSession.commit(); // 提交
} else {
sqlSession.rollback();
}
} finally {
in.close();
sqlSession.close();
}
- 需要注意,由于默认的
sqlSessionFactory.openSession()是不自动提交更改到数据库的; - 我们需要手动执行
commit进行提交; insert方法返回的 int 类型返回值,是执行的 SQL 语句影响的行数;
# 获取主键
- 上面 👆 代码中,我们手动设置了 id 的值;
- 但是数据表中,id 作为主键,是一个自增的值。我们不需要手动去设置;
下面 👇 来做一些修改:
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
INSERT INTO sys_user (user_name, user_password, user_email, user_info, head_img, create_time)
VALUES (#{userName}, #{userPassword}, #{userEmail}, #{userInfo}, #{headImg, jdbcType=BLOB},
#{createTime, jdbcType=TIMESTAMP})
</insert>
useGeneratedKeys设置为true后,MyBatis 会使用 JDBC 的getGeneratedKeys方法来取出 由数据库内部生成的主键- 获得主键值后将其赋值给
keyProperty配置的参数id属性。也就是作为参数 SysUser 类型实例的id属性; - 由于要使用数据库返回 的主键值,所以 SQL 上下两部分的列中去掉了
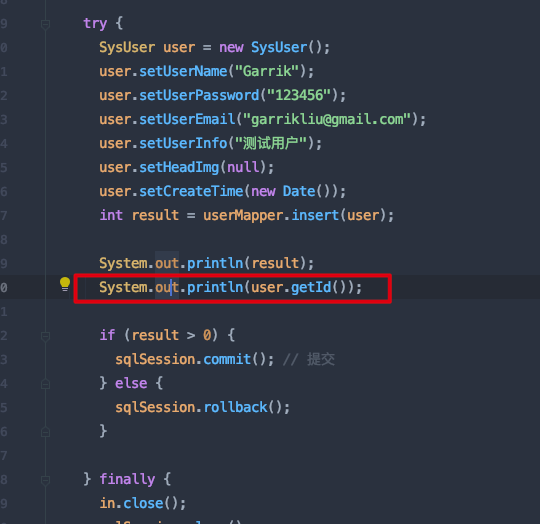
id列和对应的#{id}属性; - 在测试代码中,可以再
insert方法执行完毕后,打印一下user.getId()的值,看一下是否能获取到返回的主键值;
# 使用 selectKey 返回主键的值
- 上面这种回写主键的方法只适用于支持主键自增的数据库;
- 有些数据库(如 Oracle) 不提供主键自增的功能;
- 对于这种情况,可以使用
<selectKey>标签来获取主键的值; - 这种方式不仅适用于不提供主键自增功能的数据库,也适用于提供主键自增功能的数据库;
<insert id="insert">
INSERT INTO sys_user (user_name, user_password, user_email, user_info, head_img, create_time)
VALUES (#{userName}, #{userPassword}, #{userEmail}, #{userInfo}, #{headImg, jdbcType=BLOB},
#{createTime, jdbcType=TIMESTAMP})
<selectKey keyColumn="id" resultType="long" keyProperty="id" order="AFTER">
SELECT LAST_INSERT_ID()
</selectKey>
</insert>
keyColumn和keyProperty是一一对应的关系。前者指定数据表的列名,后者指定实体类的属性名;resultType用于设置返回值类型;order属性的设置和使用的数据库有关:- 在 MySQL 数据库中,
order属性设置的值是 AFTER,因为当前记录的主键值在insert语句执行成功后才能获取到; - 而在 Oracle 数据库中,
order的值要设置为 BEFORE,这是因为 Oracle 中需要先从序列获取值,然后将值作为主键插入到数据库中。
- 在 MySQL 数据库中,
selectKey元素中的内容。它的内容就是一个独立的 SQL 语句;- 在 MySQL 中,SQL 语句
SELECT LAST_INSERT_ID()用于获取数据 库中最后插入的数据的 ID 值; - 不同的数据库,语句也不同,这里不展开;
# UPDATE
- 使用
<update>标签执行更新操作; - 在 UserMapper 接口类中,新增
int updateById(SysUser sysUser)方法; - 之后在
UserMapper.xml文件中新增:
<update id="updateById">
UPDATE sys_user
SET user_name = #{userName},
user_password = #{userPassword},
user_email = #{userEmail},
user_info = #{userInfo},
head_img = #{headImg, jdbcType=BLOB},
create_time = #{createTime, jdbcType=TIMESTAMP}
WHERE id = #{id}
</update>
- 然后测试代码如下:
try {
SysUser user = userMapper.selectById((long) 2);
user.setUserName("Xiang");
int result = userMapper.updateById(user);
System.out.println(result);
System.out.println(user.getUserName());
if (result > 0) {
sqlSession.commit(); // 提交
} else {
sqlSession.rollback();
}
} finally {
in.close();
sqlSession.close();
}
# DELETE
- 使用
<delete>标签执行删除操作; - 在 UserMapper 接口类中,新增
int deleteById(Long id)方法; - 之后在
UserMapper.xml文件中添加:
<delete id="deleteById">
DELETE
FROM sys_user
WHERE id = #{id}
</delete>
- 测试代码是:
try {
int result = userMapper.deleteById((long) 1047);
System.out.println(result);
if (result > 0) {
sqlSession.commit(); // 提交
} else {
sqlSession.rollback();
}
} finally {
in.close();
sqlSession.close();
}
# 接口方法接收多个参数
- 前面的例子里方法都只有一个参数;
- 在实际应用中经常会遇到接口方法使用多个参数的情况;
- 可以通过给参数配置 @Param 注解,在 SQL 部分就可以通过配置的注解值来使用参数;

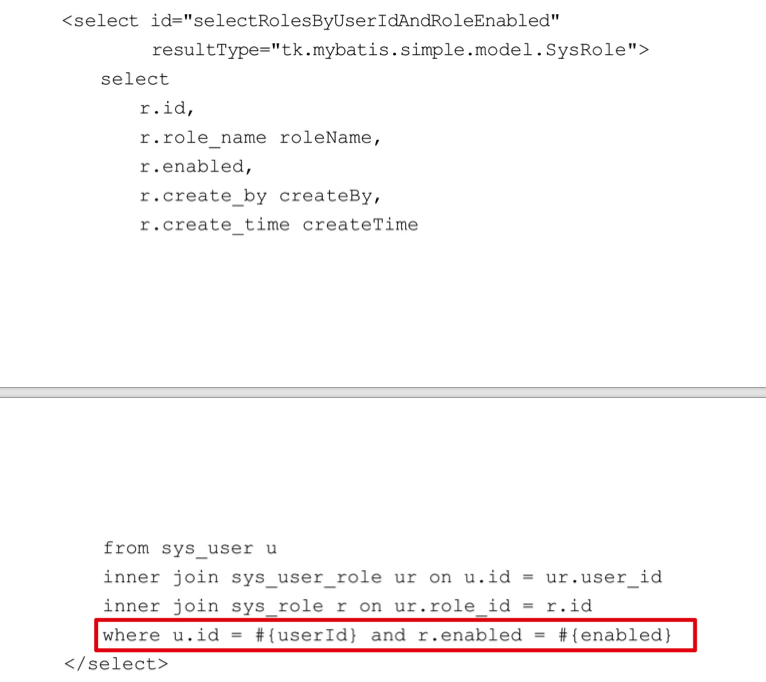

- 在 SQL 中,可以通过点取值方式 使用
#{user.id}和#{role.enabled}从两个 JavaBean 中取出指定属性的值;
# MyBatis 注解方式的基本用法
- MyBatis 注解方式就是将 SQL 语句直接写在接口方法上;
- 一般情况下不建议使用注解方式;
# @Select
现在让我们用注解的方式重新写 UserMapper 接口类中的 selectById 方法;
- 在接口方法上直接加注解;
- 参数可以是字符串数组类型,也可以是字符串类型;
@Select({"SELECT * FROM sys_user", "WHERE id = #{id}"})
SysUser selectById(Long id);
// ---- 或者 -----
@Select({"SELECT * FROM sys_user WHERE id = #{id}"})
SysUser selectById(Long id);
使用注解方式同样需要考虑数据表字段,和 Java 属性字段映射的问题:
第一种是通过 SQL 语句使用别名来实现;
@Select({
"SELECT id,",
"user_name AS userName,",
"user_password AS userPassword,",
"user_email AS userEmail,",
"user_info AS userInfo,",
"head_img AS headImg,",
"create_time AS createTime",
"FROM sys_user",
"WHERE id = #{id}"
})
SysUser selectById(Long id);
第二种是在 Mybatis 配置文件中设置 mapUnderscoreToCamelCase 为 true;
<settings>
<setting name="mapUnderscoreToCamelCase" value="true" />>
</settings>
第三种是使用 resultMap 方式;
- XML 中的
resultMap元素有一个对应的 Java 注解@Results,使用这个注解来实现属性映射; @Result注解对应着 XML 文件中的<result>元素- 把
@Result注解写在对应的@Select注解之上就可以了;
@Results({
@Result(property = "id", column = "id"),
@Result(property = "userName", column = "user_name"),
@Result(property = "userPassword", column = "user_password"),
@Result(property = "userEmail", column = "user_email"),
@Result(property = "userInfo", column = "user_info"),
@Result(property = "headImg", column = "head_img", jdbcType = JdbcType.BLOB),
@Result(property = "createTime", column = "create_time", jdbcType = JdbcType.TIMESTAMP),
})
@Select({"SELECT * FROM sys_user", "WHERE id = #{id}"})
SysUser selectById(Long id);
- 如果多个接口方法都需要使用同一个
@Results注解的话; - 从 MyBatis 3.3.1 版本开始,
@Results注解增加了一个id属性,设置了id属性后,就可以通过id属性引用同一个@Results配置了;

- 使用
@ResultMap注解引用即可,注解的参数值就是上面代码中设置的id的值;

# @Insert
@Insert 注解本身是简单的,但如果需要返回主键的值,情况会变得稍微复杂一些;
# 不需要返回主键
- 用注解的方式重写 UserMapper 的
insert方法; - 这个方法和 XML 中的 SQL 完全一样,这里不做特别介绍;
@Insert({
"INSERT INTO sys_user",
"(user_name, user_password, user_email, user_info, head_img, create_time)",
"VALUES (",
"#{userName}, #{userPassword}, #{userEmail}, #{userInfo},",
"#{headImg, jdbcType=BLOB},",
"#{createTime, jdbcType=TIMESTAMP}",
")"
})
int insert(SysUser sysUser);
# 返回自增主键
- 因为
id主键是自增的; - 我们想要获取到它,并把它设置到创建的 SysUser 类型实例中;
- 和使用 XML 的方式类似,我们需要设置 useGeneratedKeys 和 keyProperty 属性;
- 增加一个
@Options注解,在这个注解中设置 useGeneratedKeys 和 keyProperty 属性;
@Insert({
"INSERT INTO sys_user",
"(user_name, user_password, user_email, user_info, head_img, create_time)",
"VALUES (",
"#{userName}, #{userPassword}, #{userEmail}, #{userInfo},",
"#{headImg, jdbcType=BLOB},",
"#{createTime, jdbcType=TIMESTAMP}",
")"
})
@Options(useGeneratedKeys = true, keyProperty = "id")
int insert(SysUser sysUser);
# 返回非自增主键
- 使用
@SelectKey注解,配置和 XML 中基本相同; - 其中
before为false时功能等同于order = "AFTER",before为true时功能等同于order = "BEFORE"
@Insert({
"INSERT INTO sys_user",
"(user_name, user_password, user_email, user_info, head_img, create_time)",
"VALUES (",
"#{userName}, #{userPassword}, #{userEmail}, #{userInfo},",
"#{headImg, jdbcType=BLOB},",
"#{createTime, jdbcType=TIMESTAMP}",
")"
})
@SelectKey(
statement = "SELECT LAST_INSERT_ID()",
keyColumn = "id",
keyProperty = "id",
resultType = Long.class,
before = false)
int insert(SysUser sysUser);
# @Update
- 改写 UserMapper 接口类的
updateById方法;
@Update({
"UPDATE sys_user",
"SET user_name = #{userName},",
"user_password = #{userPassword},",
"user_email = #{userEmail},",
"user_info = #{userInfo},",
"head_img = #{headImg, jdbcType=BLOB},",
"create_time = #{createTime, jdbcType=TIMESTAMP}",
"WHERE id = #{id}"
})
int updateById(SysUser sysUser);
# @Delete
- 重写 UserMapper 接口类的
deleteById方法;
@Delete("DELETE FROM sys_user WHERE id = #{id}")
int deleteById(Long id);
# Provider 注解
- 除了上面 4 种注解可以使用简单的 SQL 外;
- MyBatis 还提供了 4 种 Provider 注解;
- 分别是:
- @SelectProvider;
- @InsertProvider;
- @UpdateProvider;
- @DeleteProvider;
- 它们同样可以实现查询、插入、更新、删除操作;
下面通过@SelectProvider 用法来了解 Provider 注解方式的基本用法:
- 创建 PrivilegeMapper 接口,添加
selectById方法,代码如下:

- 其中 PrivilegeProvider 类代码如下:

- Provider 注解中提供了两个必填属性
type和method; type配置的是一个包含method属性指定方法的 “类”;- 这个类必须有空的构造函数;
- 这个类中对应的方法,返回的值就是要执行的 SQL 语句。所以方法返回数据类型必须是 String 类型;
- 上面的代码,拼接 SQL 语句时使用了
new SQL方法; - 也还可以直接返回 SQL 字符串;

- SQL 较长或需要拼接时推荐使用
new SQL的方式;
# MyBatis 动态 SQL
- MyBatis 的强大特性之一便是它的动态 SQL;
- 在实际开发中,经常会需要对不同的判断条件,来拼接 SQL 语句;
- MyBatis 采用了功能强大的 OGNL(Object-Graph Navigation Language)表达式语言;
# OGNL 用法
MyBatis 常用的 OGNL 表达式如下:

# if
# 在 WHERE 条件中使用 if
- if 标签通常用于 WHERE 语句中,通过判断参数值来决定是否使用某个查询条件;
- 假设现在有一个新的需求:实现一个用户管理高级查询功能,根据输入的条件去检索用户信息。需要支持以下三种情况:
- 当只输入用户名时,需要根据用户名进行模糊查询;
- 当只输入邮箱时,根据邮箱进行完全匹配;
- 当同时输入用户名和邮箱时,用这两个条件去查询匹配的用户;
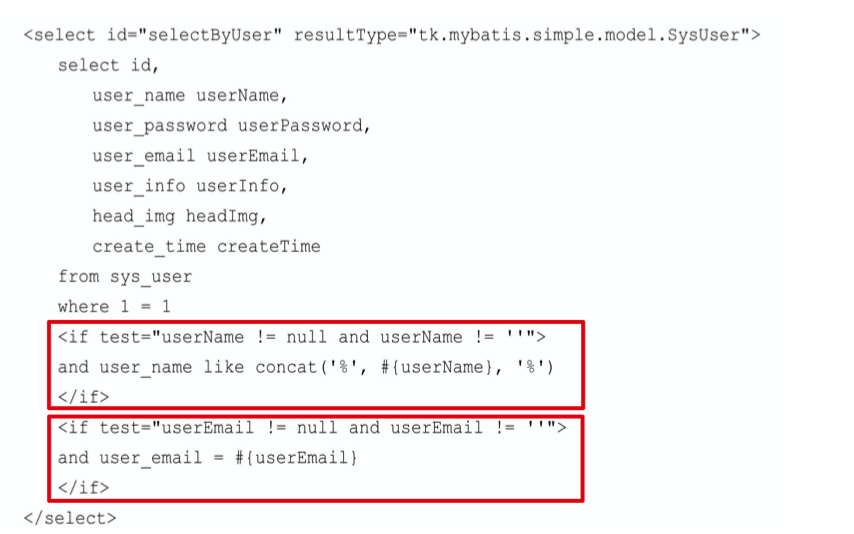
- if 标签有一个必填的属性
test; test的属性值是一个符合 OGNL 要求的判断表达式- 上面两个条件的属性类型都是 String,对字符串的判断首先需要判断字段是否为 null,然后再去判断是否为空;
- 但在 OGNL 表达式中,这两个判断的顺序 不会影响判断的结果,也不会有空指针异常;
- 注意 SQL 中
where关键字后面的条件where 1=1:- 由于两个条件都是动态的,所以如果没有 1=1 这个默认条件,当两个 if 判断都不满足时,最后生成的 SQL 就会以 where 结束;
- 加上 1=1 这个 条件就可以避免 SQL 语法错误导致的异常;
- 这种写法并不美观,后面介绍 where 标签的用法,可以替代这种写法;
# 在 UPDATE 更新中使用 if
- 现在要实现这样一个需求:
- 只更新有变化的字段;
- 更新的时候不能将原来 有值但没有发生变化的字段更新为空或 null;
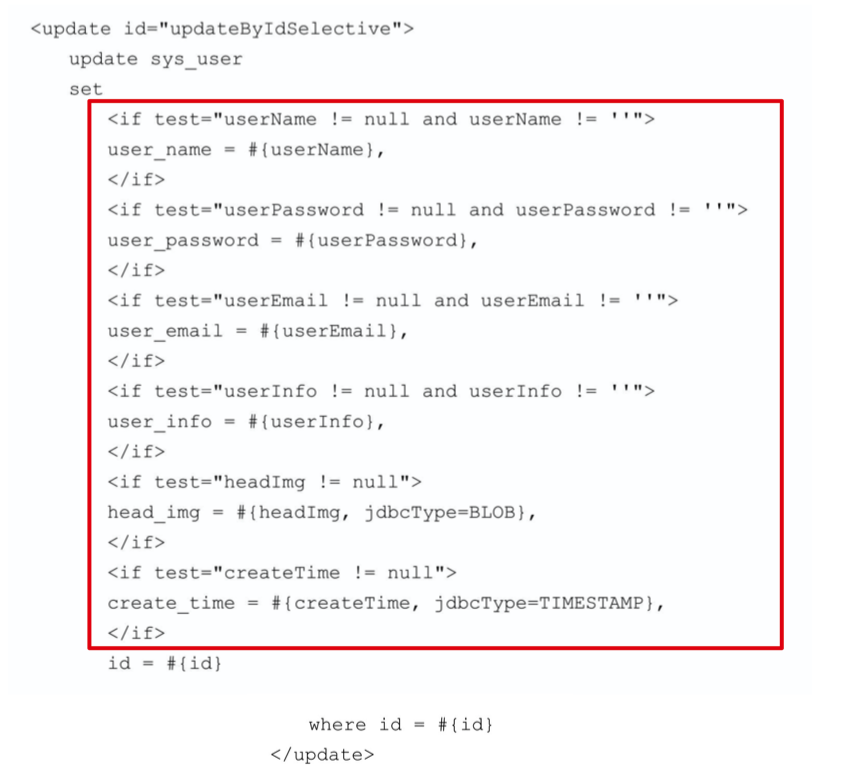
- 需要注意的有两点:
- 第一点是每个 if 元素里面 SQL 语句后面的逗号;
- 第二点就是 where 关键字前面的
id=#{id}这个条件;
- 原因是,如果所有的 if 判断都失败。最终的 SQL 语句是
update sys_user set id=#{id} where id=#{id}如果 where 前面没有加id=#{id},最后就会出错; - 如果前面的 if 判断结果成功,但因为每一行后面都有一个逗号。如果没有这个条件,最终的 SQL 是:
update sys_user set user_name=#{userName},where id=#{id}。也会报错;
# 在 INSERT 动态插入列中使用 if
- 在数据库表中插入数据的时候,如果某一列的参数值不为空,就使用传入的值,如果传入参数为空,就使用数据库中的默认值;
- 使用 if 就可以实现这种动态插入列的功能;
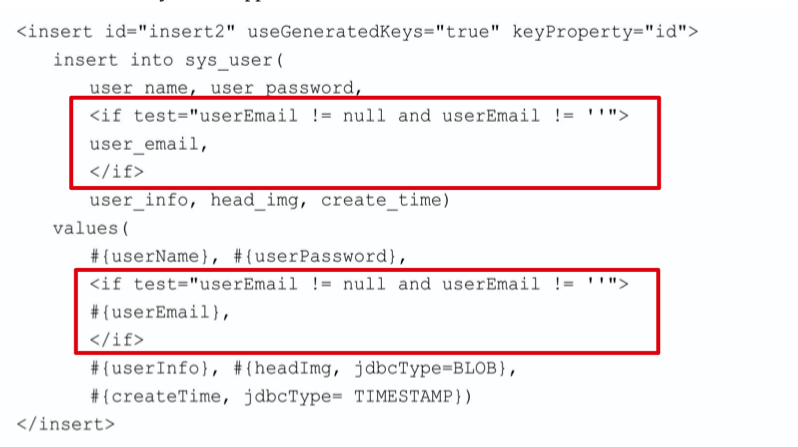
- 要注意,若在列的部分增加 if 条件,则 values 的部分也要增加相同的 if 条件,必须保证上下可以互相对应,完全匹配;
- 如果参数没有给 userEmail 属性赋值,这样就会使用数据库的默认值;
# choose
- 上一节的 if 标签提供了基本的条件判断,但是它无法实现 if - else 的逻辑;
- 要想实现这样的逻辑,就需要用到
choosewhenotherwise标签; - choose 元素中包含 when 和 otherwise 两个标签;
- 一个 choose 中至少有一个 when,有 0 个或者 1 个 otherwise;
- 在 sys_user 表中,除了主键 id 外,我们认为 user_name(用户名)也是唯一的,所有的用户名都不可以重复;
- 现在进行如下查询:当参数 id 有值的时候优先使用 id 查询;
- 当 id 没有值时 就去判断用户名是否有值,如果有值就用用户名查询;
- 如果用户名也没有值,就使 SQL 查询无结果。

- when 相当于 if;
- otherwise 相当于 else;
- 在以上查询中,如果没有 otherwise 这个限制条件,所有的用户都会被查询出来;
# where, set, trim
# where
where 标签的作用:
- 如果该标签包含的元素中有返回值,就插入一个 where;
- 如果 where 后面的字符串是以 AND 和 OR 开头的,就将它们剔除;
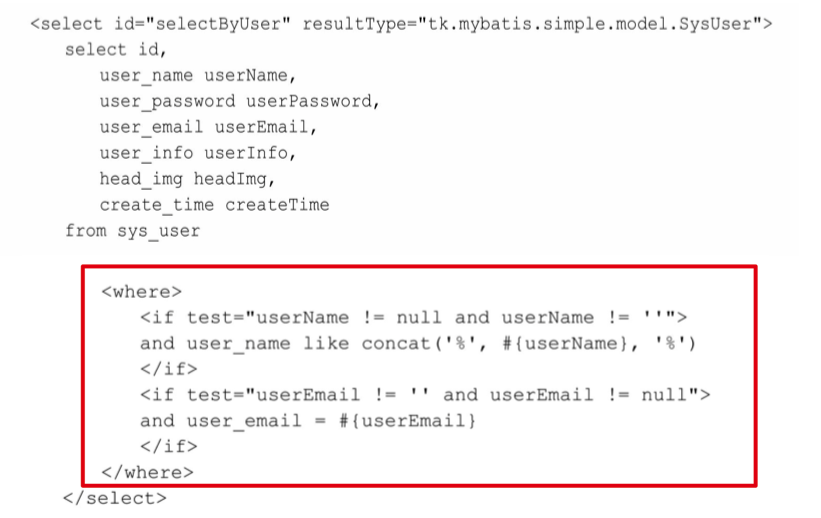
- 当 if 条件都不满足的时候,where 元素中没有内容,所以在 SQL 中不会出现 where;
- 如果 if 条件满足,where 元素的内容就是以 and 开头的条件,where 会自动去掉开头的 and,然后添加上一个 where;
- 这种方式生成的 SQL 更干净、更贴切,不会在任何情况下都有
where 1=1这样的条件。
# set
set 标签的作用:
- 如果该标签包含的元素中有返回值,就插入一个 set;
- 如果 set 后面的字符串是以逗号结尾的,就将这个逗号剔除;
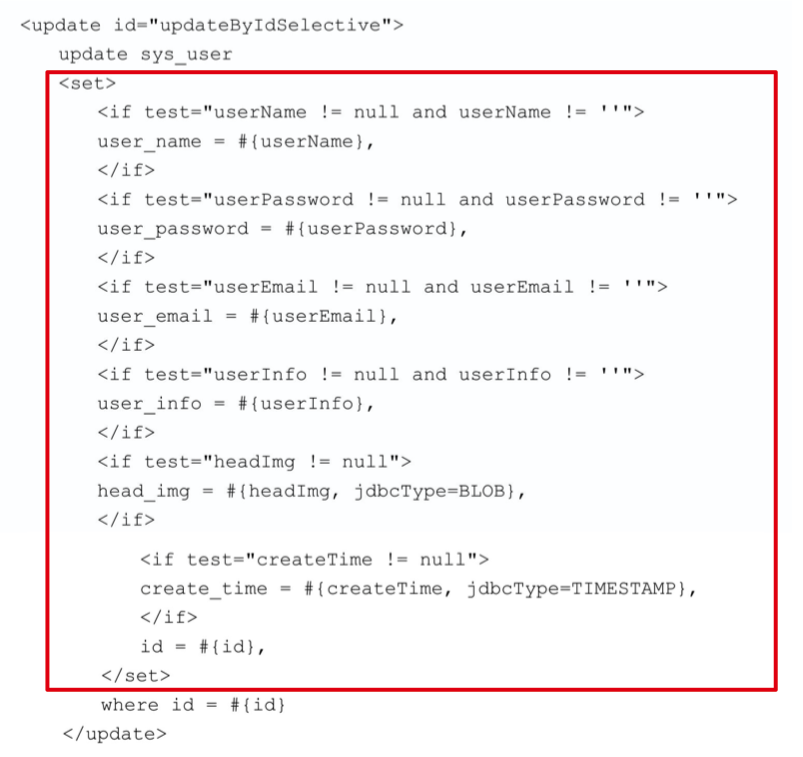
- 在 set 标签的用法中,SQL 后面的逗号没有问题了,但是如果 set 元素中没有内容,照样会出现 SQL 错误;
- 以为了避免错误产生,类似
id=#{id}这样必然存在的赋值仍然有保留的必要;
# trim
- where 和 set 标签的功能都可以用 trim 标签来实现;
- trim 标签有如下属性:
- prefix:当 trim 元素内包含内容时,会给内容增加 prefix 指定的前缀;
- prefixOverrides:当 trim 元素内包含内容时,会把内容中匹配的前缀字符串去掉;
- suffix:当 trim 元素内包含内容时,会给内容增加 suffix 指定的后缀;
- suffixOverrides:当 trim 元素内包含内容时,会把内容中匹配的后缀字符串去掉;
where 标签对应 trim 的实现如下:
- 这里的 AND 和 OR 后面的空格不能省略;

set 标签对应的 trim 实现如下:

# foreach
- foreach 可以对数组、Map 或实现了 Iterable 接口(如 List、Set)的对象进行遍历;
- 数组在处理时会转换为 List 对象;
# foreach 实现 in 集合
下面介绍如何根据传入的 “用户 id 集合” 查询出所有符合条件的用户;
- 首先在 UserMapper 接口中增加如下方法;

- 在 UserMapper.xml 中增加如下代码;
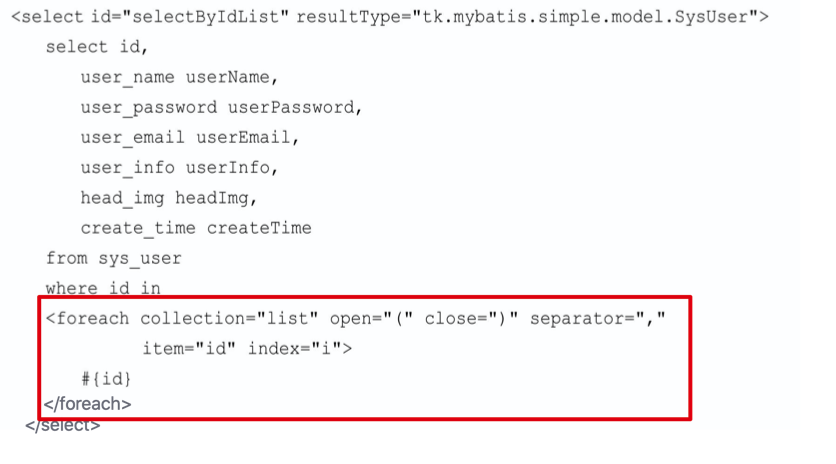
foreach 包含以下属性:
- collection:必填,值为要迭代循环的对象的名字;
- item:变量名,当前正在被迭代的集合中的元素的引用;
- index:索引的属性名,在集合数组情况下值为当前索引值,当迭代循环的对象是 Map 类型时,这个值为 Map 的 key 值;
- open:整个循环内容开头的字符串。
- close:整个循环内容结尾的字符串。
- separator:每次循环的分隔符;
对于 collection 属性:
- 如果传入的是单参数且参数类型是一个 List 的时候,collection 属性值为 list;
- 如果传入的是单参数且参数类型是一个 array 数组的时候,collection 的属性值为 array;
- list 和 array 都是参数默认的名字;
- 推荐使用 @Param 来指定参数的名 字,这时 collection 就设置为通过 @Param 注解指定的名字;
- 当有多个参数的时候,要使用 @Param 注解给每个参数指定一个名字。因此将 collection 设置为 @Param 注解指定的名字即可;
- 如果参数是一个对象,这种情况下指定为对象的属性名即可。比如参数 student 里面有一个属性 courses 是一个集合,那 collection 的值为
student.courses;
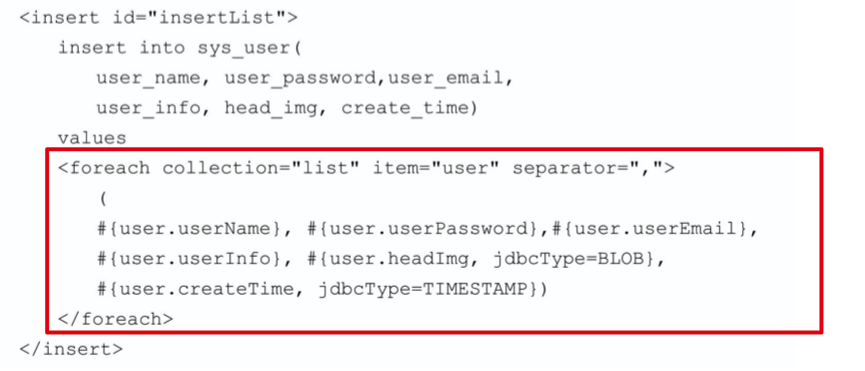
# foreach 实现批量插入
# foreach 实现动态 UPDATE
- 当参数是 Map 类型的时候,foreach 标签的 index 属性值对应的不是索引值,而是 Map 中 的 key;
- 利用这个 key 可以实现动态 UPDATE;


- key 作为列名,对应的值作为该列的名字;
# bind
- bind 标签可以使用 OGNL 表达式创建一个变量并将其绑定到上下文中;

- 在上面的例子中,我们使用到了
concat函数拼接字符串; - 但是这个函数在不同的数据库中,表现是有区别的;
- 为了抹除这种区别,我们可以使用 bind 作为替换;

- bind 标签的两个属性都是必选项;
- name 为绑定到上下文的变量名;
- value 为 OGNL 表达式;
- 创建一个 bind 标签的变量后,就可以在下面直接使用;