# Java 基础知识
# 基础知识
# 注释
在 Java 中有三种加注释的方法:
- 在文字前面加
//; - 使用
/* */将一段文字包裹起来; - 使用
/**开始,以*/结束。这种注释可以被 javadoc 工具自动解析成文档。可以避免代码与文档分开写,而导致二者更新不同步的情况。具体使用方法后面讲;
# 基本数据类型 & 变量
- Java 是一个强类型语言,每个变量必须有一个类型;
- 在 Java 中一共有 8 种基本类型;
- 4 种整型 int, short, long, byte;
- 2 种浮点类型 float, double;
- 1 种字符类型 char;
- 1 种真值类型 boolean;
int, short, long, byte;

float, double;

- double 表示的数值精度是 fLoat 的二倍,所以也叫双精度数值;
- 基本上实际开发时都使用 double 类型去表示浮点数值;
- 默认情况下,一个浮点数值被认为是 double 类型,例如
3.14。如果要表示其为 float 类型,需要在数值后面加f或者F作为后缀,如3.14F;
char;
- char 类型是一个单一的 16 位 Unicode 字符;
- 最小值是
\u0000(即为 0); - 最大值是
\uffff(即为 65,535); \u为转义符,后面加上 16 进制数值,表示转换成 Unicode 字符;- char 类型的字面量值要用单引号括起来,例如
'A';
boolean;
- 有两个值
true和false; - 默认值是 false;
# 变量
- 在声明变量时,变量的类型位于变量名之前;
- 变量名大小写敏感;
- 变量名必须以字母开头,可以由数字,字母,下划线,美元符号组成;
- 可以在程序的任何地方进行变量的声明,但尽量靠近变量第一次使用的地方;
double salary;
int days;
boolean isValid;
- 声明完一个变量后,应该立刻进行显示的初始化,这样可以避免 BUG;
int days = 12;
# 常量
- 利用关键字
final指示常量; - 常量一旦被赋值就不能更改;
- 常量名习惯用大写;
final int DAY_OF_WEEK = 7;
# 类型转换
# 算术运算时的类型转换
在使用操作符(+,-,*,/,%)对两个操作数进行算术运算的时候,如果两个操作数类型不同,会默认进行类型转换:
- 如果其中一个是 double 类型,另一个转换成 double 类型;
- 否则,如果其中一个是 float 类型,另一个转换成 float 类型;
- 否则,如果其中一个是 long 类型,另一个转换成 long 类型;
- 否则,两个操作数都转换成 int 类型;
下图表示了数值类型之间的合法转换:
- 实心箭头表示没有信息丢失的转换;
- 虚箭头表示有精度损失的转换;
- 例如:
123456789是一个 int 类型,其包含的位数比 float 类型所能表达的位数多,这时如果将其转换成 float 类型,就会造成精度的损失;
- 例如:

# 强制类型转换
- 如果想将 double 转换成 int 类型,我们需要进行强制类型转换(cast) 操作。
- 语法格式是在圆括号中给出想要转换到的目标类型,后面紧跟待转换的变量名;
- 不要将 boolean 类型变量强制转换成任何类型,这样可以防止错误发生;
double x = 12.221;
int y = (int) x; // y = 12
# 字符串
- Java 没有内置的字符串类型;
- Java 字符串就是 Unicode 字符序列;
- 而标准 Java 类库中提供了一个 String 类,任何用双括号包裹的字符串都被认作是 String 实例;
- String 实例被称作不可变字符串,因为你不可以更改实例中的任何一个字符。如果想改变字符串变量的值,只能让其指向一个新的 String 实例;
String hello = "Hello World";
# 子串
使用 substring 方法可以从一个较大的字符串中提取一个子串:
- 接收两个参数,第一个是子串在原字符串中开始的下标;第二个参数是结束位置后一位的下标;
String hello = "Hello";
String s = hello.substring(0, 3); // Hel
# 拼接
使用 + 号可以进行字符串的拼接:
- 将一个字符串与一个非字符串进行拼接时,后者会被转换成字符串;
String x = "123";
String y = "xyz";
String z = x + y; // 123xyz
// ----
String x = "123";
String y = 123;
String z = x + y; // 123123
使用 String 类型的 join 静态方法,可以将多个字符串进行拼接时,用一个指定的定界符分隔;
- 定界符作为第一个参数;
String x = String.join("/", "Hello", "World"); // Hello/World
# 字符串相等判断
- 因为变量保存的是字符串实例的引用,不能用
==判断两个字符串内容是否相等; - 要用 String 实例的
equals方法去检测; - 方法返回一个 boolean 类型的值,作为判断结果;
String x = "abc";
String y = "abc";
boolean z = x.equals(y); // true
- 如果想忽略大小写可以用
equalsIgnoreCase方法;
String x = "abc";
String y = "ABC";
boolean z = x.equalsIgnoreCase(y); // true
# 常用 String 方法
下面汇总了 String 类常用的方法:



# 命令行输入输出
# 格式化输出
System.out.print()可以将字符串输出打印到控制台上;System.out.println()会在结尾添加一个换行符/n;System.out.printf可以用来进行格式化输出;
String x = "world";
String y = "Garrik";
System.out.printf("Hello, %s, %s.", x,y);
- 每一个以 % 字符开始的格式说明符都会被对应的参数所替换;
- % 后面的字母被称作转换符,指示被格式化的数值类型;
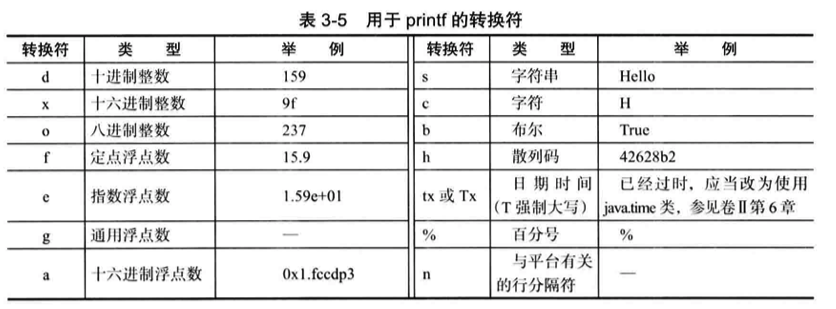
- % 和转换符之间还可以添加用于控制格式化输出的各种 “标志”;

System.out.printf("%8.2f", x)将以 8 个字符的宽度,和保留小数点后两个字符的精度打印 x。例如:12345.67;使用
String.format方法可以创建一个格式化的字符串,而不打印输出;
String world = "World";
String x = String.format("Hello, %s", world);
# 读取输入
- 想要通过控制台获取一个输入,先要创建一个
Scanner实例。并与标准输入流System.in进行关联; - 之后就可以使用 Scanner 类的各种方法实现输入操作了;
Scanner in = new Scanner(System.in);


# Number 类 & Math 类
- Java 为每一个基本数据类型都提供了对应的包装类;
- Integer, Long, Byte, Double, Float, Short;
- 它们都是 Number 类的子类;
- 当编译器把一个基本数据类型数值转换成对应的包装类实例时,被称为 “装箱”,反之称之为 “拆箱”;
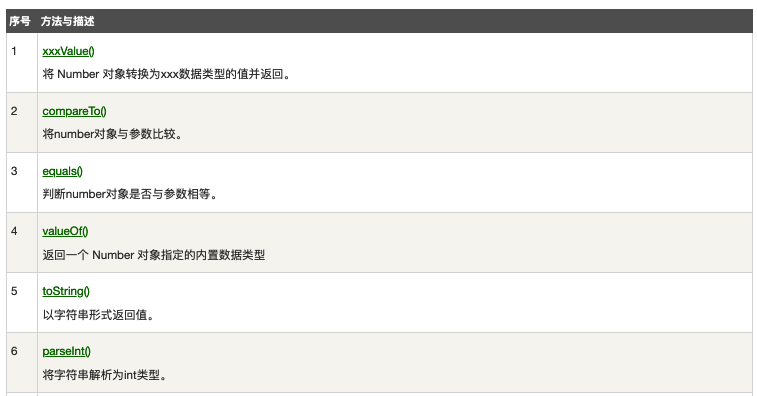
parseInt()方法用于将字符串参数作为有符号的十进制整数进行解析。可以通过第二个参数指定基数;
public class Test{
public static void main(String args[]){
int x =Integer.parseInt("9");
double c = Double.parseDouble("5");
int b = Integer.parseInt("444",16);
System.out.println(x); // 9
System.out.println(c); // 5.0
System.out.println(b); // 1092
}
}
- Java 的 Math 包含了用于执行基本数学运算的属性和方法;
- Math 的方法都被定义为
static形式,可以直接调用;


# 大数值
- 通过
BigInteger和BigDecimal类可以处理包含任意长度数字序列的数值; - 使用两个类中的静态方法
valueOf可以将普通的数值转换成大数值; - 但是加减乘除不能使用(
+,-,*,/)需要使用实例方法:+:add;-:subtract;*:multiply;/:divide;%:mod;


# 数组
- 可以通过以下两种形式声明数组:
int[] a = new int[100];int a[] = new int[100];
- 可以用于以下两种方式进行初始化:
int a[] = new int[] {1, 2, 3, 4, 5, 6};int a[] = {1, 2, 3, 4, 5, 6};- 数组的大小就是初始值的个数;
- 通过
Arrays.copyOf可以进行数组的拷贝,将一个数组的值拷贝到另一个数组中;- 第一个参数是被拷贝的数组;
- 第二个参数是新数组的长度;
- 如果长度小于原始数组就只拷贝最前面的数据;
int[] a = Arrays.copyOf(b, b.length);
int[] a = Arrays.copyOf(a, a.length * 2) // 数组扩容;


- 声明多维数组:
int[][] a = new int[100][100];
int[][] b = {
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5}
}
# 面向对象
面向对象编程具有三大特性:
- 封装:把数据和行为隐藏起来,只对外暴露出一些接口,来让外部能够对其进行使用,而内部的具体实现,外部并不知道;
- 继承:扩展一个已有的类,扩展出来的新类具有被扩展类的所有属性和方法,同时新类还可以加上自己的新属性和方法;
- 多态:指同一个行为具有多个不同表现形式或形态的能力。
- 在程序中,会出现变量所指向的具体实例对象,和通过这个变量来对实例对象调用的方法,在编译时不确定,需要在运行时确定的需求;
- 在支持多态的语言中,可以不更改源代码,让不同类型的实例自动赋值到变量上,从而导致通过此变量调用实例方法,随着实例类型的不同,而表现不同的运行状态;
# 类 & 对象
- 类(class)是构造对象的模板;
- 通过类创建对象的过程叫做创建类的实例(instance);
- 对象的数据叫做实例域(instance field),对象内操纵数据的过程叫做方法(method);
- 每个实例对象都有自己单独的实例域值,这些值的集合叫做这个对象的当前状态(state);
- 方法定义了对象所支持的行为(behavior),对象的状态必须通过调用方法来改变,如果被外部行为所改变,说明类的封装性遭到破坏;
# 什么东西应该作为一个类
- 简单的规则就是在分析问题的过程中寻找名词,而方法对应着动词;
- 🌰 例如,在订单处理系统中,会看见如下一些名词:
- 商品 Item,订单 Order,账户 Account,付款 Payment,等;
- 这些名词都可能会被作为一个类 Class;
- 这些名词可能涉及到的操作有:商品被添加到购物车;订单被取消/添加;用户支付订单;用户登录/登出;
- 其中动词有:添加,取消,支付,登录,登出;
- 这些动词就会称为对应类所支持的方法;
- 当然这条规则也只作为参考,具体实现还是根据你的情况而定;
# 类与类之间的关系
- 在类之间,常见的关系有:
- 依赖 uses-a;
- 聚合 has-a;
- 继承 is-a;
- 依赖(dependence),即 uses-a 关系,是最常见的一种关系。如果一个类的方法操作了另一个类的对象,那么就说这个类依赖于另一个类;
- 🌰 例如:订单 Order 对象需要依赖商品 Product 对象,因为订单里需要知道都买了什么商品;
- 类与类之间的相互依赖应当尽可能的减少,这样一个类的改变,可以尽可能地不会影响到其他的类。这被称作降低类之间的耦合性;
- 在 Java 中,依赖关系表现为局域变量、方法的形参,或者静态方法的调用;
class Car {
public static void run(){
System.out.println("汽车在奔跑");
}
}
class Driver {
//使用形参方式发生依赖关系
public void drive1(Car car){
car.run();
}
//使用局部变量发生依赖关系
public void drive2(){
Car car = new Car();
car.run();
}
//使用静态变量发生依赖关系
public void drive3(){
Car.run();
}
}
- 聚合(aggregation),即 has-a 关系。如果一个类包含另一个类的对象,那么它们就具有聚合关系;
- 同样,应当尽可能减少类之间的聚合,来保证低耦合;
- Java 中一般使用成员变量形式实现;
class Driver {
//使用成员变量形式实现聚合关系
Car mycar;
public void drive(){
mycar.run();
}
}
- 继承(inheritance),即 is-a 关系。如果一个类扩展自另一个类,那么它们就具有继承关系。扩展类拥有被扩展类的所有属性和方法,同时还加上自己的新属性和新功能;
- 在开发中,大多使用 UML 图来表示类与类之间的关系;
- UML 统一建模语言(Unified Modeling Language);
- UML 为开发团队提供标准通用的设计语言来开发和构建计算机应用;
- UML 支持面向对象的技术,能够准确的方便地表达面向对像的概念;

# 用户自定义类
用户自己编写的类的格式如下:

🌰 下面是一个 Class 的例子:
class Employee {
private String name;
private double salary;
private LocalDate hireDay;
public Employee(String name, double salary, int year, int month, int day) {
this.name = name;
this.salary = salary;
hireDay = LocalDate.of(year, month, day);
}
public String getName() {
return name;
}
public double getSalary() {
return salary;
}
public LocalDate getHireDay() {
return hireDay;
}
public void raiseSalary(double byPercent) {
double raise = salary * byPercent / 100;
salary += raise;
}
}
# 构造器
在上面的类里,这段函数被称作类的构造器。
public Employee(String name, double salary, int year, int month, int day) {
this.name = name;
this.salary = salary;
hireDay = LocalDate.of(year, month, day);
}
- 构造器与类必须同名;
- 构造器用来在创建类实例时,初始化实例域(属性);
- 每个类可以有一个以上的构造器,通过参数的不同来进行区别,这被称作重载;
- 构造器没有返回值;
- 构造器函数需要伴随着
new操作符一起使用;
# 隐式参数 & 显式参数
下面 👇 这个方法可以将调用这个方法的对象的 salary 实例域(属性)设置为新值;
public void raiseSalary(double byPercent) {
double raise = salary * byPercent / 100;
salary += raise;
}
下面的调用将 e 的 salary 属性的值增加了 5%。
Employee e = new Employee("Garrik", 1000, 1997, 06, 04);
e.raiseSalary(5);
raiseSalary 方法有两个参数:
- 第一个参数为 “隐式参数 implicit”,是出现在方法名前面的 Employee 类实例。也有人称为方法的调用者;
- 第二个参数为,“显式参数 explicit”,是传入方法名后面括号里的值;
在方法体中,关键字 this 表示隐式参数:
public void raiseSalary(double byPercent) {
double raise = this.salary * byPercent / 100;
this.salary += raise;
}
上面 👆 的函数也可以这样写,直接把 this 写在函数体中;
很多人喜欢这种风格,因为可以将实例域与局部变量很明显地区分开来;
当显式参数与实例域同名时,就必须要用 this 来指示实例域:
public Employee(String name, double salary, int year, int month, int day) {
this.name = name;
this.salary = salary;
hireDay = LocalDate.of(year, month, day);
}
# 修饰符
修饰符用来定义类、方法或者变量的特性;
Java 语言提供了很多修饰符,主要分为以下两类:
- 访问修饰符;
- 非访问修饰符;
# 访问修饰符
访问修饰符用来定义类、方法或其他成员的可访问性。Java 支持 4 种不同的访问修饰符:
default:
- 使用默认访问修饰符声明的变量和方法,对同一个包内的类是可见的;
private:
- 被声明为 private 的方法、变量和构造方法只能被所属类访问;
- 类和接口不能声明为 private,内部类除外;
- private 变量只能通过类中 public 的 getter 方法被外部访问;
public:
- 被声明为 public 的类、方法、构造方法和接口能够被任何其他类访问;
- 类所有的公有方法和变量都能被其子类继承;
protected:
- protected 可以修饰数据成员,构造方法,方法成员,不能修饰类(内部类除外);
- 如果子类与基类在同一包中,被声明为 protected 的变量、方法和构造器能被同一个包中的任何其他类访问;
- 如果子类与基类不在同一包中,那么在子类中,子类实例可以访问其从基类继承而来的 protected 方法,而不能访问基类实例的 protected 方法。这样就能保护不相关的类使用这些方法和变量;
- 父类中声明为 protected 的方法在子类中要么声明为 protected,要么声明为 public,不能声明为 private;

🌰 例子,下面代码中,父类使用了 protected 访问修饰符,子类重写了父类的方法:
- 如果把该方法声明为
private,那么除了 AudioPlayer 之外的类将不能访问该方法。 - 如果把该方法声明为
public,那么所有的类都能够访问该方法。 - 如果我们只想让该方法对其所在类的子类可见,则将该方法声明为
protected;
class AudioPlayer {
protected boolean openSpeaker(Speaker sp) {
// 实现细节
}
}
class StreamingAudioPlayer extends AudioPlayer {
protected boolean openSpeaker(Speaker sp) {
// 实现细节
}
}
# 非访问修饰符
Java 也提供了许多非访问修饰符:
static:
- 用来修饰属于类的方法和变量. 所有类的实例都共享着同一份静态变量和方法. 静态变量和方法也被称为 "类变量" 和 "类方法";
- 静态方法不能使用类的非静态变量;
final:
- 用来声明常量, 变量一旦赋值后, 不能被重新赋值;
- 被 final 修饰的实例变量必须显式指定初始值;
- 父类中的 final 方法被子类继承后不能被重写;
abstract:
- 抽象类不能用来实例化对象;
- 声明抽象类的唯一目的是为了将来对该类进行扩充;
- 如果一个类包含抽象方法,那么该类一定要声明为抽象类;
- 抽象类可以包含抽象方法和非抽象方法;
- 抽象方法是一种没有任何实现的方法,该方法的的具体实现由子类提供;
- 抽象方法不能被声明成 final 和 static;
- 任何继承抽象类的子类必须实现父类的所有抽象方法,除非该子类也是抽象类;
public abstract class SuperClass{
abstract void m(); //抽象方法
}
class SubClass extends SuperClass{
//实现抽象方法
void m(){
...
}
}
synchronized&volatile:主要用于线程的编程,这里先不讲;
# Getter & Setter
为了保证实例域 (实例的属性) 不会被外界随意修改, 保证封装性;
在类中通常把属性实例域设置为 private 私有;
同时提供 public 公共的 "Getter 访问器方法", 和 "Setter 更改器方法", 用以让外界来对实例域进行获取和修改;
class Employee {
private String name;
public String getName() {
return name;
}
public void setName(name) {
this.name = name;
}
}
好处:
- 即使类的内部实现改变, 只要 Getter 和 Setter 的名字不改, 不会影响到外部对该类的使用;
- 在 Setter 方法中, 可以对传入的属性进行错误检查, 以防错误数据传入;
- 防止外部对实例内部的属性进行随意更改;
不要编写返回引用类型对象的 Getter 方法;
- 在上面 👆 的 Employee 类
getHireDay方法就返回了一个 Date 类实例, 这样破坏了封装性;
class Employee {
// ...
private LocalDate hireDay;
// ...
public LocalDate getHireDay() {
return hireDay;
}
// ...
}
- 返回引用类型,会导致允许外部对实例内部属性进行修改;
- 假如我们有一个实例 harry, 然后
Date d = harry.getHireDay();d和harry.hireDay都指向同一个 Date 实例, 通过d就可以更改实例内部的属性;
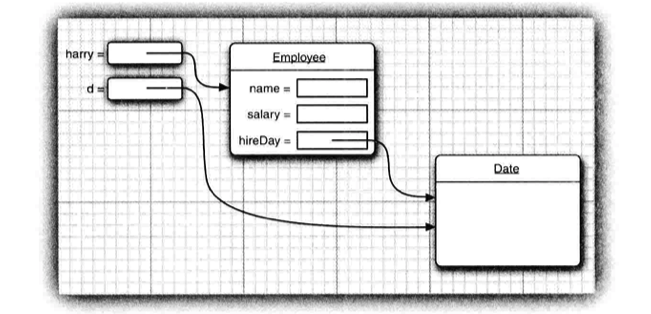
- 如果需要返回一个对象实例, 那么应该对它进行克隆 clone, 然后返回对象的克隆副本;
- 上面代码可以修改如下:

# 基于类的访问权限
类的方法可以访问同一个类的任何一个实例的私有域 (私有属性);

上面 👆 代码中, 在类方法中, 可以访问传入进来的同类实例的私有属性;
# 方法参数
在程序设计语言中, 将参数传递给方法有两种方式:
- 按值传递 (call by value): 表示方法接收的是调用者提供的值;
- 按引用传递 (call by reference): 表示方法接收的是调用者提供的内存地址;
在 Java 中, 函数接收的参数总是按值传递的. 函数接收的是参数值的拷贝.
但参数会有两种类型:
- 基本数据类型: 变量保存的是数据的值;
- 引用类型: 变量保存的是对象的地址;
对于基本数据类型, 函数内部将传入参数的值拷贝了一份给参数变量, 函数内部对参数变量的修改, 不会影响外部.
但是对于引用类型, 函数内部保存的是对象在内存中的地址, 通过地址可以直接访问到外部的对象实例, 并且能够对其进行操作.
WARNING
⚠️ 很多人以为对引用类型参数, 采用的是按引用传递. 但其实依旧是按值传递.
public void swap(Employee x, Employee y) {
Employee temp = x;
x = y;
y = temp;
}
如果是按引用传递, 那么内部对 x 和 y 的值的交换, 就会影响到外部作为参数传入的两个变量的值.
按值传递的意思是, 函数接收的是作为参数传入的变量上保存的值的拷贝. 变量上保存的是对象的地址.
按引用传递的意思是, 函数接收的是作为参数传入的变量的地址的拷贝. 通过这个地址引用, 可以在函数内部修改外部变量上保存的值.
# 传递可变数量的参数
如果想让一个方法接收不确定数量的参数, 可以使用 ... 来表示:
🌰 例如, 下面 👇 方法用来计算若干个数值中的最大值:
public double max(double... values) {
double largest = values[0];
for(double v : values) {
if(v > largest) {
largest = v;
}
}
return largest;
}
在方法内, 用一个数组来储存所传进来的不确定数量的参数.
# 对象构造
Java 提供了多种编写构造器的机制:
# 重载
Java 中允许多个方法具有同一个名字, 但是有不同的参数, 这被称为重载.
注意, 重载方法的返回值类型必须相同.
在代码编译时, 编译器会通过调用方法时传入的参数类型和数量, 来寻找匹配的方法. 如果找不到就报错, 这个过程称为重载解析 overloading resolution.
Java 允许重载任何方法, 构造器方法也可以进行重载.
# 默认构造器
如果编写类时, 没有提供构造器. Java 会提供给你一个默认无参数的构造器.
在构造器中, 所有的实例域都设置为默认值:
- 数值类型设置为 0;
- 布尔类型设置为 false;
- 对象类型设置为 null;
但如果类中提供了一个有参数的构造器, 没有提供无参数的构造器. 那么 Java 不会提供给你无参数的构造器.
如果你创建实例时没有提供任何参数, 就会报错.
# 调用另一个构造器
在构造器中, 如果第一行语句形如 this(...), 那么它可以调用同一个类的另一个构造器.
public class Employee {
private static int nextId = 0;
private long id;
private double salary;
public Employee(long id, double salary) {
this.id = id;
this.salary = salary;
}
public Employee(double salary) {
this(nextId, salary);
nextId++;
}
}
# 初始化块
在一个类的声明中, 可以包含多个代码块, 当要创建类的实例时, 这些块就会被执行.
代码块的位置无所谓, 写在类的最后面也会在实例化时, 先执行.

在代码块前可以加 static 关键字, 来表示一个静态初始化块.
静态初始化块会在类第一次加载的时候被执行. 一般用来对静态域进行初始化.

# 调用构造器时执行顺序
- 所有的数据域初始化为默认值;
- 按照在类中声明的顺序, 一次执行所有的初始化块;
- 如果被执行构造器的第一行调用了另一个构造器, 那么先执行另一个构造器;
- 然后再执行构造器主体;
# 包
Java 允许使用包 package 将类组织起来;
通过使用包可以确保类名的唯一性;
Sun 公司简易将公司的网站域名以逆序的形式作为包名, 并且对不同的项目使用不同的子包;
- 🌰 例如, 我的网站叫
garrikliu.com那么我的项目包名就叫com.garrikliu. 我网站下有一个购物商场, 那么这个项目的包名就是com.garrikliu.mystore;
一个类可以使用所属包内的所有类, 以及其他包中的公共类 (public class).
通过两种方式可以访问另一个包中的公共类:
第一种, 在每一个类名前添加完整的包名:
java.time.LocalDate today = java.time.LocalDate.now();
第二种, 使用 import 语句引入一个特定的类或者整个包. import 语句应该位于源文件的顶部.
// 引入 util 下面的所有类
import java.util.*;
// 引入 LocalDate 类
import java.time.LocalDate;
⚠️ 只能使用 * 匹配一个包下面的所有类, 而不能引入多个包. 例如:
import java.*;
import java.*.*;
上面 👆 的两种写法都是不对 ❌ 的.
如果一个包中需要使用两个同名的类, 那么只能在使用时, 在类名前加上完整的包名了.
java.util.Date deadLine = new java.util.Date();
java.sql.Date today = new java.sql.Date(...);
# 静态导入
import 语句还可以导入类中的静态方法和静态域.
import static java.lang.System.*;
上面 👆 这条语句可以导入 System 类中的所有静态方法和静态类, 使用时不用添加类名前缀.
out.println("Hello World"); // System.out.println
# 把类放入包中
想要把一个类放入包中, 就要在类的源文件的开头, 写上包的名字, 格式如下:
package com.garrik.mystore;
public class Product {
...
}
不写的话, 源文件内的类就不会被放入包中, 而是放入一个默认包 default package.
# 文档注释
JDK 包含一个工具叫做 javadoc, 它可以通过源文件中的代码注释, 生成一个 HTML 文件;
因为文档是直接通过源代码的注释生成的, 可以保证文档与代码的一致性. 分开管理的话, 很容易出现版本对不上的问题.
默认情况下, javadoc 工具从以下几个部分提取信息:
- 包;
- 公共类和接口;
- 公共 public 和受保护 protected 的构造器和方法;
- 公共 public 和受保护 protected 的域 (属性);
应该为以上 👆 几个部分编写注释.
注释以 /** 开始, 以 */ 结束.
/** ... */ 中间内容为自由格式文本 free-form text:
- 自由格式文本中, 可以使用 HTML 元素;
- 例如
<em>...</em>,<strong>...</strong>,<img ... />等; - 但是有些元素, 例如
<h1>或者<hr>它们会与文档的格式产生冲突, 具体规则可以单独去查阅;
# 类注释
在类的定义之前, 写入类注释.
📒 注释结构参考:
/**
* 类 <code>{类名称}</code> {此类功能描述}
*
* @author {作者}
* @version {版本}
*/
🌰 示例:
/**
* Class <code>Object</code> is the root of the class hierarchy.
* Every class has <code>Object</code> as a superclass. All objects,
* including arrays, implement the methods of this class.
*
* @author xxxxxxxxx
* @version 1.61
*/
public class Object {}
⚠️ 没必要在每一行前面都写 * 星号, 上面的注释也可以写成:
/**
Class <code>Object</code> is the root of the class hierarchy.
Every class has <code>Object</code> as a superclass. All objects,
including arrays, implement the methods of this class.
@author xxxxxxxxx
@version 1.61
*/
只不过现在大多 IDE 都会自动加星号, 开发时不用管太多.
# 方法注释
在每个方法之上都要写方法的注释.
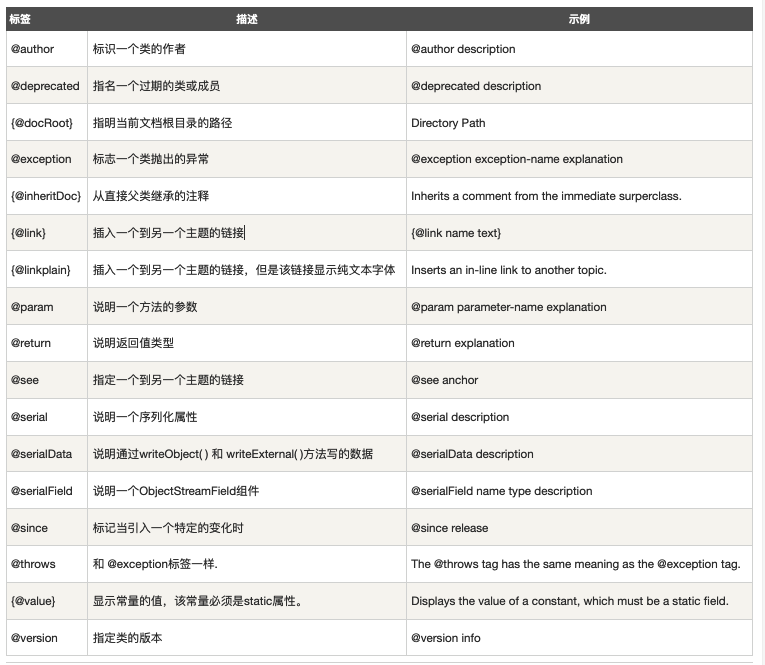
可以使用如下标记来帮助描述方法相关信息:
@param变量描述, 用以说明一个方法的参数;@return返回值描述, 说明一个方法的返回值;@throws异常描述, 用于表示这个方法有可能抛出异常;
📒 注释结构参考:
/**
* {方法的功能描述}
*
* @param {参数名} {参数说明}
* @return {返回参数说明}
* @exception {说明在某情况下,将发生什么异常}
*/
🌰 示例:
/**
* Returns a new string that is a substring of this string. The
* substring begins with the character at the specified index and
* extends to the end of this string.
*
* Examples:
* <blockquote><pre>
* "unhappy".substring(2) returns "happy"
* "Harbison".substring(3) returns "bison"
* "emptiness".substring(9) returns "" (an empty string)
* </pre></blockquote>
*
* @param beginIndex the beginning index, inclusive.
* @return the specified substring.
* @exception IndexOutOfBoundsException if
* <code>beginIndex</code> is negative or larger than the
* length of this <code>String</code> object.
*/
public String substring(int beginIndex) {
return substring(beginIndex, count);
}
# 域注释
只需要对公共域 (公共属性) 编写注释.
通常类中的公共域, 同时也是静态常量, 一般来说类中的属性都是私有的, 很少见公有的.
📒 注释结构参考:
/**
* {此值是用来存储/记录什么的}
*/
private String str;
🌰 示例:
/**
* The value is used for character storage.
*/
private char value[];
# 通用标记
# 注释规范
下列规范参考自 <阿里巴巴 Java 开发手册 v1.5.0>
- 类、类属性、类方法必须使用 Javadoc 规范注释;
- 所有的抽象方法(包括接口中的方法)必须要用 Javadoc 注释、除了返回值、参数、异常说明外,还必须指出该方法做什么事情,实现什么功能;
- 所有的类都必须添加创建者
@author; - 方法内部单行注释,在被注释语句上方另起一行,使用
//注释。方法内部多行注释 使用/* */注释,注意与代码对齐; - 所有的枚举类型字段必须要有注释,说明每个数据项的用途;
- 代码修改的同时,注释也要进行相应的修改;
- 注释掉代码时, 需要在上方给出详细说明,而不是简单地注释掉。如果代码无用,则删除;
- 代码被注释掉有两种可能性:1. 后续会恢复此段代码逻辑。2. 永久不用。前者如果没有备注信息,难以知晓注释动机。后者建议直接删掉;
- 对于注释的要求:
- 能够准确反映设计思想和代码逻辑;
- 能够描述业务含义,使别的程序员能够迅速了解到代码背后的信息;
- 好的命名、代码结构是自解释的,注释力求精简准确、表达到位;
- 语义清晰的代码不需要额外的注释;
# 继承
# 继承基础
在 Java 中通过关键字 extends 来让一个类继承自另一个类.
继承表现了类与类之间的 "is-a" 关系.
public class Manager extends Employee {
...
}
被继承的类, 称为 "超类 superclass", "基类 base class", 或 "父类 parent class.
新创建的类叫做 "子类 subclass", "派生类 derived class", 或 "孩子类 child class"
子类会继承父类所有的非 private 的属性和方法.
在子类中可以添加新的域名, 方法, 或者覆盖超类的方法, 但是不能够删除从超类继承来的方法或者域.
在 Java 中, 并不支持多继承, 也就是一个类派生自多个类, 这是不可以的.
# 重写
通过重写子类可以根据自己的需要, 重新编写从父类继承来的方法.
class Animal{
public void move(){
System.out.println("动物可以移动");
}
}
class Dog extends Animal{
public void move(){
System.out.println("狗可以跑和走");
}
}
方法的重写规则:
- 参数列表必须完全与被重写方法的相同;
- 返回类型与被重写方法的返回类型可以不相同,但是必须是父类被重写方法原返回值的派生类;
- 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为 public,那么在子类中重写该方法就不能声明为 protected;
- 声明为 final 的方法不能被重写;
- 声明为 static 的方法不能被重写,但是能够被再次声明;
- 子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为 private 和 final 的方法;
- 子类和父类不在同一个包中,那么子类只能够重写父类的声明为 public 和 protected 的非 final 方法;
- 重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常, 重写后的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以;
- 构造方法不能被重写;
# super
在子类中, 通过关键字 super:
- 可以用来访问直接父类的实例域;
- 可以用来调用父类的方法;
- 使用
super()可以调用父类的构造函数;
🌰 使用示例:
为了简化子类的构造函数, 在子类中可以直接调用父类的构造函数.
class Person {
int id;
String name;
Person(int id, String name) {
this.id = id;
this.name = name;
}
}
class Emp extends Person {
float salary;
Emp(int id, String name, float salary) {
super(id, name);// reusing parent constructor
this.salary = salary;
}
void display() {
System.out.println(id + " " + name + " " + salary);
}
}
class TestSuper5 {
public static void main(String[] args) {
Emp e1 = new Emp(1, "ankit", 45000f);
e1.display();
}
}
⚠️ 注意, super 和 this 不是相同的概念. super 不是一个对象的引用, 不能将 super 赋给另一个对象变量, 它只是一个指示编译器访问超类成员的关键字.
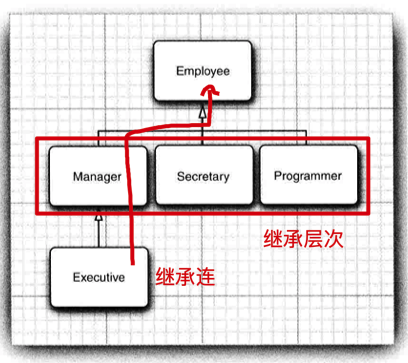
# 继承层次
由一个公共超类派生出来的所有类的集合被称为继承层次(inheritance hierarchy).
在继承层次中从某个特定的类到其祖先的路径被称为该类的继承链 (inheritance chain).
通常,一个祖先类可以拥有多个子孙继承链.
# 强制类型转换
在 Java 中 每个对象变量都属于一个类型 类型描述了这个变量能够引用的对象类型.
可以将一个子类实例的引用赋值给一个超类变量, 但如果想将超类实例的引用赋值给子类变量, 必须要先进行类型转换.
在保存对象引用的变量名前, 加一个圆括号 ( ) 将目标类名括起来, 可以将这个对象实例类型转换成目标类型.
Manager boss = ( Manager ) staff;
只能对继承链上的类, 进行从上到下的类型转换.
如果类型转换失败, 会产生一个 ClassCastException 异常, 为了防止异常的发生, 在类型转换之前, 需要先查看是否能够转换成功.
通过 instanceof 操作符可以验证它左边的对象实例是否是它右边的类 (可以是超类) 的实例,返回 true / false.
if(staff instanceof Manager) {
boss = (Manager) staff;
}
# 阻止继承 final
通过 final 修饰符可以防止类被继承.
public final class Executive extends Manager {
...
}
上面 👆 的 Executive 类就不可以被其他类继承了.
类中特定的方法可以使用 final 修饰符, 阻止这个方法被子类重写覆盖.
public class Employee {
...
public final String getName() {
return name;
}
...
}
# 抽象类 abstract
如果你想设计这样一个类,该类包含一个特别的成员方法,该方法的具体实现由它的子类确定,那么你可以在父类中声明该方法为抽象方法:
- 通过
abstract关键字来声明抽象方法; - 抽象方法只包含一个方法名,而没有方法体;
如果一个类包含抽象方法,那么该类必须是抽象类:
- 通过
abstract关键字来声明抽象类; - 抽象类并不能够被实例化, 要想使用它, 必须要被其他类继承;
- 任何子类必须重写父类的抽象方法,或者声明自身为抽象类;
- 反正, 最后所有的抽象方法都必须有子类实现;
- 抽象类中不一定包含抽象方法,但是有抽象方法的类必定是抽象类;
public abstract class Employee
{
private String name;
private String address;
private int number;
public abstract double computePay();
...
}
public class Salary extends Employee
{
private double salary; // Annual salary
public double computePay()
{
System.out.println("Computing salary pay for " + getName());
return salary/52;
}
...
}
# 受保护访问 protected
父类中声明为 private 的成员即使是子类也获取不到.
有时候希望有些内容允许被子类访问, 那么需要将这些成员成名为 protected.
`public class Parent {
protected String protect = "protect field";
protected void getMessage(){
System.out.println("i am parent");
}
}
Java 中的受保护部分对所有子类及同一个包中的所有其他类都可见.
若子类与基类不在同一包中,那么在子类中,子类实例可以访问其从基类继承而来的 protected 方法,而不能访问基类实例的 protected 方法。
package a;
class X {
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
package b;
public class Y extends X {
public static void main(String args[]) {
X x = new X();
x.clone(); // Compile Error
Y y = new Y();
y.clone(); // Complie OK
}
}
- 在上面 👆 的代码中, X 继承自 Y, 但是他们处于不同的 paackage;
- 在 Y 的
main方法中, 获取不到 X 类型实例的clone方法, 所以x.clone()失败; - 但是 Y 类型继承来的
clone方法可以访问到, 所以y.clone()调用成功;
# Object 类
Object 类是 Java 中所有类的始祖, 在 Java 中每个类都是由它扩展来的.
如果没有明确指出一个类的超类, 那么默认 Object 就是这个类的超类.
Object 类自身有很多方法, 下面 👇 介绍一些:
# equals
Object 类中的 equals 方法默认判断两个实例的地址是否相同.
在扩展出的类中可以重写 equals 方法, 来满足各自的需求.
🌰 例如 String 类中的 equals 方法不但可以判断地址是否相同, 还可以判断两个字符串内容是否相同:
public class Test {
public static void main(String args[]) {
String Str1 = new String("runoob");
String Str2 = Str1;
String Str3 = new String("runoob");
boolean retVal;
retVal = Str1.equals( Str2 ); // true
retVal = Str1.equals( Str3 ); // true
}
}
# hashCode
hashCode 方法返回对象的哈希值, 主要使用在哈希表中.
计算出哈希码的通用约定如下:
- 在 java 程序执行过程中,在一个对象没有被改变的前提下,无论这个对象被调用多少次,hashCode 方法都会返回相同的整数值;
- 如果 2 个对象使用 equals 方法进行比较并且相同的话,那么这 2 个对象的 hashCode 方法的值也必须相等;
- 如果根据 equals 方法,得到两个对象不相等,但这 2 个对象的 hashCode 值允许相同, 但不推荐;
可以根据自身需求重写 hashCode 方法:
class Book {
private String title;
private String author;
public int hashCode() {
int hash = 37;
int code = 0;
// Use title
code = (title == null ? 0 : title.hashCode());
hash = hash * 59 + code;
// Use author
code = (author == null ? 0 : author.hashCode());
hash = hash * 59 + code;
return hash;
}
}
# getClass
getClass 方法是一个 final 方法,不允许子类重写.
函数返回隐式参数对象实例所属类型的 Class 对象.
String s = "Hello World";
s.getClass == String.class // true
# toString
toString 方法返冋描述该对象值的字符串.
Object 对象的默认实现,即输出类的名字@实例的哈希码的 16 进制.
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
一般来讲, 建议所有的 Object 子类都重写 toString 方法.
🌰 例如:
public class Student {
private String id;
private String name;
private String gender;
...
@Override
public String toString() {
return "ID: " + id + " | Name: " + name + " | Gender: " + gender;
}
}
只要对象与一个字符串通过操作符 + 连接起来, Java 编译就会自动地调用 toString 方法 以便获得这个对象的字符串描述.
Point p = new Point (10, 20);
String message = "The current position is " + p;
当将一个对象实例传入 System.out.print() 方法时, 也会调用这个实例的 toString 方法.
# 枚举
在现实生活中,经常会有一个变量只有固定几种取值的情况. 例如季节,它只有春夏秋冬 4 个可能的值, 或者一周七天的名称.
在 Java 中可以通过声明枚举类, 来表现这种取值是由一组有限且固定的常量组成的属性.
# 声明枚举
- 用
enum关键字声明枚举类型. 枚举类型都是 Enum 类的子类; - 在枚举类的第一行, 写下所有的枚举常量;
- 枚举类中的所有的枚举常量都是
public static final的; - 枚举常量推荐全部用大写字母命名, 彼此之间用逗号分隔;
- 非抽象的枚举类不能再派生子类;
// 定义一个星期的枚举类
public enum WeekEnum {
// 在第一行显式地列出7个枚举实例(枚举值),系统会自动添加 public static final 修饰
SUNDAY, MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY;
}
使用时, 不用 new 创建实例, 直接使用定义的枚举类型就可以.
WeekEnum day = WeekEnum.SUNDAY;
System.out.println(day == WeekEnum.SUNDAY); // true
// 因为 day 保存的引用就是 WeekEnum.SUNDAY, 所以可以用 ==
上面 👆 的代码等效于下面的代码:
public class WeekEnum {
public static final int MONDAY =1;
public static final int TUESDAY=2;
public static final int WEDNESDAY=3;
public static final int THURSDAY=4;
public static final int FRIDAY=5;
public static final int SATURDAY=6;
public static final int SUNDAY=7;
}
这样写首先很不简洁, 而且容易出错. 假如把其中几个属性的值写成一样的, 编译器也不会提出任何警告,但是会造成使用时出现 BUG.
# 枚举类的实现原理
在使用关键字 enum 创建枚举类型并编译后,编译器会为我们生成一个相关的类,这个类继承了 Java API 中的 java.lang.Enum 类.
上面 👆 的枚举类型代码, 经过反编译后会变成:
final class WeekEnum extends Enum
{
// 编译器为我们添加的静态的 values() 方法
public static WeekEnum[] values()
{
return (WeekEnum[])$VALUES.clone();
}
// 编译器为我们添加的静态的 valueOf() 方法,注意间接调用了 Enum 类的 valueOf 方法
public static WeekEnum valueOf(String s)
{
return (WeekEnum)Enum.valueOf(com/zejian/enumdemo/WeekEnum, s);
}
// 私有构造函数
private WeekEnum(String s, int i)
{
super(s, i);
}
// 前面定义的 7 种枚举实例
public static final WeekEnum MONDAY;
public static final WeekEnum TUESDAY;
public static final WeekEnum WEDNESDAY;
public static final WeekEnum THURSDAY;
public static final WeekEnum FRIDAY;
public static final WeekEnum SATURDAY;
public static final WeekEnum SUNDAY;
private static final WeekEnum $VALUES[];
static
{
// 实例化枚举实例
MONDAY = new WeekEnum("MONDAY", 0);
TUESDAY = new WeekEnum("TUESDAY", 1);
WEDNESDAY = new WeekEnum("WEDNESDAY", 2);
THURSDAY = new WeekEnum("THURSDAY", 3);
FRIDAY = new WeekEnum("FRIDAY", 4);
SATURDAY = new WeekEnum("SATURDAY", 5);
SUNDAY = new WeekEnum("SUNDAY", 6);
$VALUES = (new WeekEnum[] {
MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY
});
}
}
- 可以看到, 编译器还帮助我们生成了 7 个 WeekEnum 类型的实例对象. 分别对应枚举中定义的 7 个日期常量;
- 也就是说, 在枚举类中定义的枚举常量, 最后会被创建成枚举类型的实例对象;
- 在使用枚举常量时,
WeekEnum.SUNDAY访问的是 WeekEnum 类型的public static final WeekEnum SUNDAY静态常量;
# 自定义枚举类的构造函数
- 我们可以自定义枚举类的构造函数;
- 但是构造函数必须是
private的;
public enum Level {
LOW(30), MEDIUM(15), HIGH(7), URGENT(1);
// Declare an instance variable
private int levelValue;
// Declare a private constructor
private Level(int levelValue) {
this.levelValue = levelValue;
}
public int getLevelValue() {
return levelValue;
}
}
- 上面代码声明了一个实例域
levelValue, 还定义了一个私有构造函数,它接受一个 int 参数; - 在声明枚举常量时, 把常量想要的参数值传入进去, 如
LOW(30); - 在实例化枚举常量时, 自定义的私有构造函数会被调用, 传入的参数值会存储在
levelValue实例属性中; - 里面还定义了一个公共方法
getLevelValue(), 通过它可以获取到枚举常量实例的levelValue属性值;
# 枚举类常用方法
因为枚举类继承自 Enum 类, 所以它也继承来了很多方法, 下面 👇 是一些常用的:

ordinal()方法,该方法获取的是枚举变量在枚举类中声明的顺序, 下标从 0 开始;compareTo(E o)方法则是比较枚举的大小,注意其内部实现是根据每个枚举的 ordinal 值大小进行比较的;name()方法与toString()几乎是等同的,都是输出变量的字符串形式;
上面讲解枚举原理时, 可以看到枚举类被编译时, 编译器给它生成了 values() 和 valueOf(String name) 这两个静态方法.
values()以数组形式返回枚举类型的所有成员;valueOf()通过字符串获取同名的枚举实例;
enum Signal {
GREEN, YELLOW, RED;
}
public static void main(String[] args) {
for(int i = 0; i < Signal.values().length; i++) {
// 打印所有的枚举常量
System.out.println(Signal.values()[i]);
}
}
public class TestEnum {
public enum GENDER {
MALE, FEMALE;
}
public static void main(String[] args) {
System.out.println(GENDER.MALE == GENDER.valueOf("MALE"));
}
}
# 接口
# 什么是接口
在 Java 程序设计中,接口不是类而是对类的一组需求描述,这些类要遵从接口描述的统一格式进行定义。
# 声明接口
- 使用
interface关键字定义接口; - 接口中所有的方法都属于
public, 因此声明方法时不需要再提供关键字public;
public interface Moveable {
void move(double x, double y);
}
# 接口实现类
- 要将类声明为实现了某个接口, 需要使用
implements关键字; - 实现类必须对接口中的所有方法给进行定义;
public class Car implements Moveable {
private double positionX;
private double positionY;
public void move(double x, double y) {
positionX = x;
positionY = y;
}
}
# 常量属性
- 接口中可以包含常量属性;
- 接口中所有的属性都被自动设置为
public static final所以定义时也不需要写这些关键字;
public interface Moveable {
double DISTANCE_LIMIT = 100;
}
# 接口扩展
- 接口也可以通过
extends进行扩展; - 可以从具有较高通用性的接口, 扩展出较高专用性的接口;
public interface Powered extends Moveable {
double milesPerGallon();
}
# 接口类型变量
- 接口并不可以被实例化, 但是可以声明接口类型的变量;
- 接口类型变量必须引用一个接口实现类的实例对象;
- 可以使用
instanceof检查一个实例对象是否属于接口实现类;
Moveable m = new Car();
if(m instanceof Moveable) {
...
}
# 接口 vs 抽象类
为什么不使用抽象类, 而非要使用接口?
前面说过, Java 不支持多继承, 一个类只能扩展自另一个类, 不可以是多个类.
但是一个类可以同时实现多个接口, 接口之间用逗号隔开:
class BlackBear implements OnEarth, NearAttack, FarAttack {}
# 静态方法
- 在 Java SE 8 版本之中, 允许在接口中添加静态方法.
- 这么做可以把接口作为一个单例对象来使用, 而不必非要创建一个实现类, 然后再创建类实例.
- 但是在接口中添加方法也背离了将接口作为抽象规范的初衷.

# 默认方法
- 可以用
default修饰符来给接口中的方法提供默认实现. - 在现实类中如果没有给方法提供新的实现, 那么就使用默认实现;
public interface MouseListener {
default void mouseClicked(MouseEvent event) {
System.out.println("没有实现点击事件");
}
}
# 接口使用案例
# Comparator 接口
# Cloneable 接口
# 内部类
内部类 inner class 是定义在另外一个类中的类.
# 声明内部类
- 通过在一个类的内部定义另一个来声明内部类;
- 内部类方法可以访问该类定义所在的作用域中的数据,包括私有的数据;
- 内部类所在的类, 被称为 "外部类" outer class;
public class TalkingClock {
private int interval;
private boolean beep;
public TalkingClock(int interval, boolean beep) { ... }
public void start() {
ActionListener listener = new TimePrinter();
Timer t = new Timer(interval, listener);
t.start();
}
// 内部类
public class TimePrinter implements ActionListener {
public void actionPerformed(ActionEvent event) {
System.out.println("At the tone, the time is " + new Date());
if(beep) {
Toolkit.getDefaultToolkit().beep();
}
}
}
}
# 局部内部类
上面 👆 的内部类使用示例中, 只在 start() 方法中使用了 TimePrinter 这个类.
这种情况下, 我们可以把内部类定义在准备使用它的方法中. 这被称为局部内部类.
- 局部类不使用 public 和 private 这些修饰符, 因为除了局部类所在方法, 外部不能够访问到它;
public void start() {
class TimePrinter implements ActionListener {
public void actionPerformed(ActionEvent event) {
System.out.println("At the tone, the time is " + new Date());
if(beep) {
Toolkit.getDefaultToolkit().beep();
}
}
}
ActionListener listener = new TimePrinter();
Timer t = new Timer(interval, listener);
t.start();
}
# 匿名内部类
如果只需要创建一个内部使用的类实例, 没有必要从头命名一个内部类, 然后再创建实例, 可以直接使用匿名内部类 anonymous inner class.
public void start(int interval, boolena beep) {
ActionListener listener = new ActionListener {
public void actionPerformed(ActionEvent event) {
System.out.println("At the tone, the time is " + new Date());
if(beep) {
Toolkit.getDefaultToolkit().beep();
}
}
}
Timer t = new Timer(interval, listener);
t.start();
}
上面 👆 代码的意思是, 创建一个实现了 ActionListener 接口的类的实例对象;
创建匿名内部的类的格式通常如下:

new运算符后面的不是新创建的类名, 而是 SuperType 的名字;- SuperType 既可以是接口, 也可以是类;
- 如果使用接口名称,则匿名类实现接口。如果使用类名,则匿名类继承自其它类;
- 因为构造器的名字必须与类名相同, 匿名类没有名字, 所以不能给它写构造函数;
- 只有
new运算符后面是现有的类名时, 才可能需要传入参数, 参数会传递到现有类的构造函数之中;
🌰 下面 👇 使用匿名类来创建迭代器:
import java.util.ArrayList;
import java.util.Iterator;
public class Main {
private ArrayList<String> titleList = new ArrayList<>();
public void addTitle(String title) {
titleList.add(title);
}
public void removeTitle(String title) {
titleList.remove(title);
}
public Iterator<String> titleIterator() {
// An anonymous class
Iterator<String> iterator = new Iterator<String>() {
int count = 0;
@Override
public boolean hasNext() {
return (count < titleList.size());
}
@Override
public String next() {
return titleList.get(count++);
}
}; // Anonymous inner class ends here
return iterator;
}
}
# 静态内部类
有的时候, 你可能并不需要在内部类中引用外部类对象, 那么你可以把内部类声明为静态的.
静态成员类可以声明为 public,protected,package-level 或 private,以限制其在所在类之外的可访问性;
class A {
// Static member class
public static class B {
// Body for class B goes here
}
}
使用静态类:
- 静态成员类内部可以访问, 其所在的类的静态成员, 包括私有静态成员;
- 静态类所在的外部类也可以作为一个, 在所在包 package 之内的额外的命名空间;
🌰 下面 👇 代码展示了静态类使用示例:
public class Main {
public static void main(String[] args) {
Car.Tire m = new Car.Tire(17);
Car.Tire m2 = new Car.Tire(19);
Car.Keyboard k = new Car.Keyboard(122);
Car.Keyboard k1 = new Car.Keyboard(142);
System.out.println(m);
System.out.println(m2);
System.out.println(k);
System.out.println(k1);
}
}
class Car {
// Static member class - Monitor
public static class Tire {
private int size;
public Tire(int size) {
this.size = size;
}
public String toString() {
return "Monitor - Size:" + this.size + " inch";
}
}
// Static member class - Keyboard
public static class Keyboard {
private int keys;
public Keyboard(int keys) {
this.keys = keys;
}
public String toString() {
return "Keyboard - Keys:" + this.keys;
}
}
}
// Monitor - Size:17 inch
// Monitor - Size:19 inch
// Keyboard - Keys:122
// Keyboard - Keys:142
# lambda 表达式
# 什么是 lambda 表达式
- 在 Java 8 中引入了新特性 Lambda 表达式;
- Lambda 表达式的主要作用就是简化部分匿名内部类的写法;
- 在使用匿名内部类时, 我们创建了一个实现某个接口的没有名字的类的实例对象, 对象可以被传递给它人, 并在某个时间点被调用;
- 但是匿名内部类的写法并不简洁, 对于只有一个抽象方法的接口, 创建这种接口的匿名内部类对象时, 可以用 Lambda 表达式代替;
- 只有一个抽象方法的接口叫做函数式接口;
- 表达式在数学中的意思是, 带有参数变量的表达式;
- 可以把 Lambda 表达式看作一个函数, 而不是一个对象;
Lambda 表达式就是一个可以传递的代码块, 格式如下 👇:
(parameters) -> expression
(parameters) -> {
statements;
}
- 不需要声明参数类型,编译器可以统一识别参数值;
- 只有一个参数时可以省略圆括号;
- 如果主体包含了一个语句,就不需要使用大括号;
- 如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值;
下面 👇 是一些 🌰 例子:
// 1. 不需要参数,返回值为 5
() -> 5
// 2. 接收一个参数 (数字类型), 返回其 2 倍的值
x -> 2 * x
// 3. 接受 2 个参数 (数字), 并返回他们的差值
(x, y) -> {
return x – y;
}
// 4. 接收 2 个 int 型整数, 返回他们的和
(int x, int y) -> x + y
// 5. 接受一个 string 对象, 并在控制台打印
(String s) -> System.out.print(s)
下面 👇 是用 Lambda 表达式替换匿名内部类的例子:
- 假如有一个只有一个方法的函数式接口 Runnable:
public interface Runnable {
public abstract void run();
}
- 使用匿名内部类去实现这个接口的类实例, 代码如下:
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Hello");
System.out.println("Jimmy");
}
}).start();
- 使用 Lambda 表达式, 代码如下:
new Thread(() -> {
System.out.println("Hello");
System.out.println("Jimmy");
}).start();

# 方法引用
有时候, 可能已经有现成的方法实现了你想要在 Lambda 表达式里写的操作. 那么你可以直接引用这个现成的方法.
格式如下, 使用 :: 操作符分割方法名, 和其所属的对象或类;

# 静态方法, 对象的方法
对于引用对象的方法, 或类的静态方法, 上面的表达式与 Lambda 表达式的转换关系如下 👇:
System.out::println
// 等价于
(x) -> {
System.out.println(x);
}
# 类的方法
对于这种情况, Lambda 表达式的第一个参数会变成调用方法的实例对象, 也就是方法的隐式参数:
String::compareToIgnoreCase
// 等价于
(x, y) -> x.compareToIgnoreCase(y);
# 构造函数
引用构造函数时, :: 右边的方法名为 new:
n -> new ArrayList(n)
//等价于
ArrayList::new
可以看出来在使用引用时, 我们连传入方法的参数都可以省略. 这虽然让代码更加简洁, 但对于不熟悉整体代码的人, 可读性却减低了;
# 变量作用域
通常, 你可能希望能够在 lambda 表达式的代码块中访问外围的方法或变量, 例如:
public void repeatMessage(String text, int delay) {
ActionListener listener = event -> {
System.out.println(text);
Toolkit.getDefaultToolkit().beep();
}
new Time(delay, listener).start();
}
上面 👆 代码中, Lambda 表达式代码块中的 text 是 repeatMessage 方法的一个参数变量;
这种既不是 Lambda 表达式参数, 也没有在代码块中定义的变量, 叫做 "自由变量";
Lambda 表达式会把自由变量的值保存起来, 这被称为捕获 captured. 这也顺便实现类闭包 closure.
Lambda 表达式中捕获的变量必须是一个实际上的最终变量 effectively final. 也就是变量初始化之后, 它的值就不会被改变.
下面 👇 的两种写法都是错误 ❌ 的:


之所以有这个限制, 是因为 Lambda 表达式被传递给了别人, 它被调用的时机并不是顺序的, 如果能够更改外部的引用的值, 会造成并发的错误.
Lambda 表达式的代码块与嵌套它的外部方法有相同的作用域, 所以 Lambda 表达式中, 不可以声明一个与它所在方法的局部变量, 同名的参数或局部变量;

Lambda 表达式中的 this 同样也就是它所在的方法的 this.

上面 👆 的 this 指向 Application 实例对象, 而不是 ActionListener 实例;
# 反射
- Java 反射机制是在运行状态中, 能够知道任意一个类所包含的属性和方法;
- 并且能够访问和调用任意一个对象实例的属性和方法;
- 这种动态获取信息和动态调用的能力, 叫做 "反射";
# Class 类
- Java 程序在运行时,Java 运行时系统会对所有的对象进行运行时类型标识;
- 运行时类型信息记录了每个对象实例所属的类;
- 用来保存这些类型信息的类是 Class 类;
- Class 类的实例对象内容是你创建的类的类型信息,比如你创建一个 shapes 类,那么,Java 会生成一个内容是 shapes 的 Class 类的对象;
- Class 实例对象的作用是, 在程序运行时提供, 或用来获得某个对象的类型信息;
- 我们在程序中创建的对象实例, 都会有一个字段保存着它对应 Class 对象的引用;
- Class 类的对象不能像普通类一样,以
new Class()的方式创建,它的对象只能由 JVM 创建,因为这个类没有 你可以访问的 public 构造函数; - 当 Java ��� 拟机装载类时,Class 类型对象实例自动被 JVM 创建;

- 通过类的
class常量属性就可以获取到 Class 实例;
Class employeeClass = Employee.class;
- 通过 Object 类中的
getClass()方法可以获取到对象的 Class 类型实例;
Employee employee = new Employee();
Class employeeClass = employee.getClass();
- 通过 Class 类的
forName(className)静态方法也可以获得对应的类型的 Class 实例; forName方法需要传入, 内容为目标类或接口名称的字符串;- 如果传入的字符串, 匹配不到对应的类或接口, 则抛出异常;
String className = "Employee";
Class employeeClass = Class.forName(className);
- 因为同种类型的实例对象都引用同一个 Class 实例;
- 所以可以通过
==判断 Class 实例的方式, 判断对象类型;
Employee employee = new Employee();
if(employee.getClass() == Employee.class) {
System.out.println("这是一个雇员");
}
- 使用 Class 实例的
newInstance()方法可以动态地创建一个类的实例; - 创建出的实例类型为 Object, 需要向下转型, 才能转换成对应类的实例;
- 但是
newInstance只会调用类的默认的构造函数, 不能向里传递参数; - 如果类没有默认的构造函数会抛出异常;
String className = "Employee";
Class employeeClass = Class.forName(className);
Employee employee = (Employee) employeeClass.newInstance();
- 如果想使用自定义的构造函数, 要使用 Constructor 类型实例的
newInstance()方法; - Constructor 类代表某个类的构造函数;
- 通过 Class 实例的
getDeclaredConstructor()方法获取到想要的构造函数对应的 Constructor 实例; getDeclaredConstructor()方法传入的参数为, 构造函数需要接收的参数的 Class 实例;
String className = "Employee";
Class employeeClass = Class.forName(className);
Constructor ec = employeeClass.getDeclaredConstructor(String.class, int.class);
Employee garrik = (Employee) ec.newInstance("Garrik", 22);
# 利用反射分析类的能力
java.lang.relfect 包内用三个类 Field, Method, Constructor, 分别对应描述类的属性, 方法, 和构造器;
java.lang.relfect 包内的 Modifier 类对应修饰符;
下面 👇 是和它们相关常用方法:



下面 👇 的代码, 可以打印出一个类的全部信息. 用户输入一个类名, 然后程序输出这个类的所有的方法和构造器的签名, 以及全部的属性名;
点击展开:
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
import java.lang.reflect.Modifier;
import java.util.Scanner;
public class ReflectionTest
{
public static void main(String[] args)
{
// read class name from command line args or user input
String name;
if (args.length > 0) name = args[0];
else
{
Scanner in = new Scanner(System.in);
System.out.println("Enter class name (e.g. java.util.Date): ");
name = in.next();
}
try
{
// print class name and superclass name (if != Object)
Class cl = Class.forName(name);
Class supercl = cl.getSuperclass();
//获取cl的访问权限修饰符(public,private等)
String modifiers = Modifier.toString(cl.getModifiers());
if (modifiers.length() > 0) System.out.print(modifiers + " ");
System.out.print("class " + name);
if (supercl != null && supercl != Object.class) System.out.print(" extends "
+ supercl.getName());
System.out.print("\n{\n");
//打印构造方法
printConstructors(cl);
System.out.println();
//打印成员方法
printMethods(cl);
System.out.println();
//打印域(成员变量)
printFields(cl);
System.out.println("}");
}
catch (ClassNotFoundException e)
{
e.printStackTrace();
}
System.exit(0);
}
/**
* Prints all constructors of a class
* @param cl a class
*/
public static void printConstructors(Class cl)
{
Constructor[] constructors = cl.getDeclaredConstructors();
for (Constructor c : constructors)
{
String name = c.getName();
System.out.print(" ");
String modifiers = Modifier.toString(c.getModifiers());
if (modifiers.length() > 0) System.out.print(modifiers + " ");
System.out.print(name + "(");
// print parameter types
Class[] paramTypes = c.getParameterTypes();
for (int j = 0; j < paramTypes.length; j++)
{
if (j > 0) System.out.print(", ");
System.out.print(paramTypes[j].getName());
}
System.out.println(");");
}
}
/**
* Prints all methods of a class
* @param cl a class
*/
public static void printMethods(Class cl)
{
Method[] methods = cl.getDeclaredMethods();
for (Method m : methods)
{
Class retType = m.getReturnType();
String name = m.getName();
System.out.print(" ");
// print modifiers, return type and method name
String modifiers = Modifier.toString(m.getModifiers());
if (modifiers.length() > 0) System.out.print(modifiers + " ");
System.out.print(retType.getName() + " " + name + "(");
// print parameter types
Class[] paramTypes = m.getParameterTypes();
for (int j = 0; j < paramTypes.length; j++)
{
if (j > 0) System.out.print(", ");
System.out.print(paramTypes[j].getName());
}
System.out.println(");");
}
}
/**
* Prints all fields of a class
* @param cl a class
*/
public static void printFields(Class cl)
{
Field[] fields = cl.getDeclaredFields();
for (Field f : fields)
{
Class type = f.getType();
String name = f.getName();
System.out.print(" ");
String modifiers = Modifier.toString(f.getModifiers());
if (modifiers.length() > 0) System.out.print(modifiers + " ");
System.out.println(type.getName() + " " + name + ";");
}
}
}
# 在运行时使用反射操纵对象
- 通过
Field类的get(obj)方法可以获取实例对象的指定属性的值; get(obj)方法传入的参数为想要访问的对象实例;- 如果想要获取的属性是 private, 那么会抛出 IllegalAccessException 异常;
Employee garrik = new Employee("Garrik");
Class employeeClass = garrik.getClass();
Field employeeName = employeeClass.getDeclaredField("name");
// 把 garrik 实例传入 get 方法
String garrikName = employeeName.get(garrik);
- 通过 Field 类的
set(obj, value)方法可以设置对应实例对象的属性值;
Employee garrik = new Employee("Garrik");
Class employeeClass = garrik.getClass();
Field employeeName = employeeClass.getDeclaredField("name");
employeeName.set(garrik, "Xiang");
- 如果属性是私有的, 受限于 Java 的访问控制,
set和get都会抛出异常; - 如果一个 Java 程序没有受到安全控制器的控制, 可以使用
setAccessible(true)方法来解除限制;
Employee garrik = new Employee("Garrik");
Class employeeClass = garrik.getClass();
Field employeeName = employeeClass.getDeclaredField("name");
employeeName.setAccessible(true);
String garrikName = employeeName.get(garrik);

- 通过 Method 类的
invoke(obj, ...args)方法可以调用包装在当前 Method 对象中的方法;- 第一个参数是调用这个方法的实例对象, 也就是隐式参数;
- 第二个参数就是传入方法的显式参数;
- 如果调用的是一个静态方法, 第一个参数为
null; - Method 实例对象通过 Class 实例的
getMethod(name, ...parameterTypes)获取;- 第一个参数是方法的名字;
- 因为重载的原因, 可能有多个方法公用一个名字, 想要准确的获得目标方法, 可以在之后提供目标方法的参数类型;
- 也可以通过 Class 实例的
getDeclareMethods方法获得包含所有方法的数组, 然后在里面进行查找;
Employee garrik = new Employee();
Method m = Employee.class.getMethod("raiseSalary", double.class);
m.invoke(garrik, 100);

# 代理 Proxy
# 什么是代理
- 在设计模式中, 代理模式是给某一个对象提供一个代理对象,并由代理对象来控制对真实对象的访问;
- 创建代理对象类叫做 "代理类", 被代理的对象所属的类叫 "委托类";
- 通过代理, 可以实现客户与委托类之间的解耦, 在不修改委托类代码的情况下, 通过代理类可以进行功能的扩展;
- 🌰 例如: 为委托类预处理数据、事后数据处理、性能检测, 打印日志, 等;
- 因为客户不接触委托类对象, 所以也顺便隐藏了委托类的实现;

按照代理类的字节码文件的创建来分类, 可以分成:
- 静态代理: 所谓静态也就是在程序运行前就已经存在代理类的字节码文件, 代理类和委托类的关系在运行前就确定了;
- 动态代理: 动态代理的源码是在程序运行期间由 JVM 根据反射等机制动态的生成,所以在运行前并不存在代理类的字节码文件;
# 静态代理
- 代理类和委托类都实现了相同的接口;
- 委托类实现接口中的方法, 提供真正的业务逻辑;
- 代理类中通过一个委托类型的属性, 来保存对委托对象的引用;
- 代理类中对接口方法的实现里, 通过委托对象来调用对应的方法. 在方法调用的前后, 可以插入扩展出的操作;
🌰 示例:
下面 👇Vendor 是委托类, BusinessAgent 是代理类, 他们都实现了 Sell 接口;
/**
* 委托类和代理类都实现了Sell接口
*/
public interface Sell {
void sell();
void ad();
}
/**
* 生产厂家
*/
public class Vendor implements Sell {
public void sell() {
System.out.println("In sell method");
}
public void ad() {
System,out.println("ad method");
}
}
/**
* 代理类
*/
public class BusinessAgent implements Sell {
private Sell vendor; // 对委托对象的引用
public BusinessAgent(Sell vendor){
this.vendor = vendor;
}
public void sell() {
vendor.sell();
}
public void ad() {
vendor.ad();
}
}
因为在代码运行之前, 就写好了代理类, 所以成为之 "静态代理";
# 动态代理
代理类在程序运行时被创建的代理方式, 被称之为 "动态代理".
静态代理的缺点:
- 如果代理类实现的接口中有很多的方法, 而你只想扩展其中一个方法在委托类中的实现, 但你却需要在代理类中给接口的每个方法都提供代理实现, 这很麻烦;
- 假如接口新增/删减了方法, 代理类和委托类也要同时修改, 不易维护;
在动态代理中, 这些问题都不存在了.
动态代理主要涉及到 JDK 提供的 java.lang.reflect.InvocationHandler 接口, 和 java.lang.reflect.Proxy 类.
首先委托类需要实现至少一个接口;
接口并不能够实例化创建对象;
通过 Proxy 类中的
newProxyInstance静态方法, 可以创建一个实现了指定接口的代理类的新实例;- 方法签名是
static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h) - 第一个参数: 类加载器 class loader, 可以通过委托类 Class 对象的
getClassLoader()获取; - 第二个参数: 需要实现的接口的 Class 对象组成的数组;
- 第三个参数: 调用处理器, 代理对象通过它来实现对委托对象的调用;
- 方法签名是
可以看出, 在动态代中, 代理对象和委托对象之间隔着一个 InvocationHandler 对象;
由
newProxyInstance方法生成的代理类实现了传入的接口内所有的方法;不同于静态代理中, 代理对象内部直接保存着对委托对象的引用, 呈现出一种一对一的关系;
动态代理中的代理类适用于所有实现了相同接口的类实例;
但客户对代理对象的调用, 最终要传递到一个具体的委托对象上;
InvocationHandler 对象就作为代理对象和委托对象之间的中介, 来进行搭桥;

- invocationHandler 对象被称作 "调用处理器";
- 调用处理器是实现了 InvocationHandler 接口的类的对象;
- 接口中只有一个方法
Object invoke(Object proxy, Method method, Object[] args); - 当客户调用代理对象方法时, 内部的调用处理器的
invoke方法就会被调用, 它会去调用委托对象对应的方法; - 代理对象向其传入被调用方法的 Method 对象, 和调用参数;
🌰 示例:
下面 👇 给出一个动态代理的示例.
编写一个调用逻辑处理器 LogHandler 类,提供日志增强功能,并实现 InvocationHandler 接口;在 LogHandler 中维护一个目标对象,这个对象是被代理的对象;
public class LogHandler implements InvocationHandler {
Object target; // 被代理的对象,实际的方法执行者
public LogHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
before();
Object result = method.invoke(target, args); // 调用 target 的 method 方法
after();
return result; // 返回方法的执行结果
}
// 调用invoke方法之前执行
private void before() {
System.out.println(String.format("log start time [%s] ", new Date()));
}
// 调用invoke方法之后执行
private void after() {
System.out.println(String.format("log end time [%s] ", new Date()));
}
}
通过 Proxy 类的 newProxyInstance 方法生成代理对象, 之后客户通过代理对象来访问委托对象;
public class Client {
public static void main(String[] args) throws IllegalAccessException, InstantiationException {
// 1. 创建被代理的对象,UserService接口的实现类
UserServiceImpl userServiceImpl = new UserServiceImpl();
// 2. 获取对应的 ClassLoader
ClassLoader classLoader = userServiceImpl.getClass().getClassLoader();
// 3. 获取所有接口的 Class 数组,这里的 UserServiceImpl 只实现了一个接口 UserService,
Class[] interfaces = userServiceImpl.getClass().getInterfaces();
// 4. 创建一个将传给代理类的调用请求处理器,处理所有的代理对象上的方法调用
InvocationHandler logHandler = new LogHandler(userServiceImpl);
// 5. 创建代理对象
UserService proxy = (UserService) Proxy.newProxyInstance(classLoader, interfaces, logHandler);
// 6. 客户调用代理的方法
proxy.select();
proxy.update();
}
}
# 异常
程序在运行时无可避免的会发生错误, 我们应该妥善的处理这些异常, 至少应该能做到以下几点:
- 向用户通告错误;
- 保存所有的工作结果;
- 允许用户以妥善的方式退出程序, 或者退回到一种安全状态;
Java 使用一种称为 "异常处理" Exception Handing 的错误捕获机制去处理运行时发生的异常;
# 处理错误
异常处理的任务就是将程序的控制权从错误发生的地方, 转移到能够处理这种错误的处理器.
一般来说, 程序中的错误大致可以分为:
- 用户输入错误:
- 本应该输入数字, 但是输入了单词;
- 设备错误:
- 打印机关机了;
- 打印机没纸了;
- 网断了;
- 物理限制:
- 磁盘满了, 储存空间用完了;
- 代码错误:
- 想要访问的数组下标不对;
- 在散列表中查找不存的记录;
- 错误的调用了方法;
在 Java 中, 如果遇到了异常, 可以抛出 throw 一个封装了错误信息的实例对象, 同时将程序的控制权交给对应的异常处理器.
# 异常分类
在 Java 中, 异常对象都是派生于 Throwable 类的一个实例;
Java 的异常层次结构如下 👇:
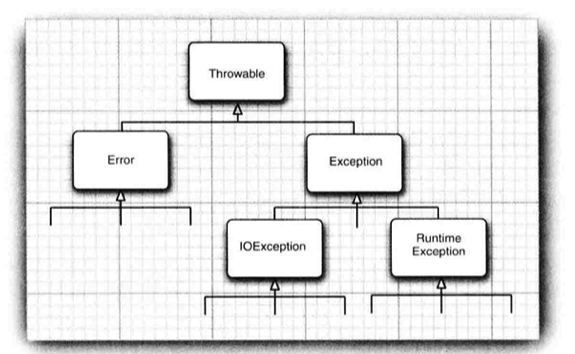
- Error 类:
- 描述了 Java 运行时系统的内部错误, 我们编写的应用程序不应该抛出这种类型的错误;
- 如果出现了这种错误, 应该尽可能地使程序安全退出, 除此之外, 也没什么办法了;
- Exception 类:
- 对于我们编写程序来说, 需要关注 Exception 类的异常;
- 它又派生出两个分支 RuntimeException, IOException;
- RuntimeException 类:
- 有程序错误导致的异常属于 RuntimeException;
- 也就是开发者写的代码有问题;
- 🌰 例如:
- 错误的类型转换;
- 数组访问越界;
- 访问
null指针;
- IOException 类:
- 程序本身没问题, 由于 I/O 错误导致的问题属于 IOException;
- 🌰 例如:
- 试图在文件尾部后面读取数据;
- 试图打开一个不存在的文件;
- 试图根据字符串查找 Class 实例对象, 但是这个类并不存在;
- 所有派生于 Error 类或 RuntimeException 类的异常称为 "非受查异常" unchecked;
- 所有的 IOException 类异常称为 "受查异常" checked;
- 编译器会检查你是否为所有的受查异常都提供了异常处理器;
- 因为受查异常的发生, 并不取决于你的代码正确与否, 而是取决于外部环境;
- 🌰 例如, 如果一件文件根本不存在, 你就打不开它, 即使你的读取文件代码正确;
- 如果断网了, 即使你访问网络资源的代码正确, 你也访问不到任何东西;
# 声明异常
方法应该在其首部声明所有可能抛出的异常;
🌰 例如:
下面 👇 这个方法可能根据给定的 String 参数产生一个 FileinputStream 实例对象, 也可能抛出一个 FileNotFoundException 异常对象;
public FileInputStream (String name) throws FileNotFoundException
在编写代码时, 不必将所有可能抛出的异常都进行声明;
代码在遇到如下 4 种情况时应该抛出异常:
- 调用一个抛出受查异常的方法;
- 程序运行过程中发生错误,并且利用
throw语句抛出一个受查异常; - 程序出现错误, 抛出非受查异常;
- Java 虚拟机和运行时库出现的内部错误;
对于前两种错误, 必须在编写方法时声明异常. 因为任何一个抛出异常的方法, 都会让当前执行的线程结束, 我们必须要用异常处理器, 对其进行捕获并处理.
但 Java 的内部错误任何代码都有可能抛出, 我们对其无能为力;
非受查异常的发生说明代码写的有问题, 我们应该修改程序, 而不是把它交给异常处理器;
# 抛出异常
在代码运行时, 如果出现了不正常的情况, 我们可以用 throw 关键字抛出一个异常.
具体步骤如下:
- 先找到一个合适的异常类;
- 然后创建异常实例;
- 用
throw抛出;
🌰 例如:
String readDate(Scanner in) throws EOFEception {
...
while(...) {
if(!in.hasNext()) { // EOF encountered
if(n < len) {
throw new EOFEception(); // 抛出异常实例
}
...
}
}
...
}
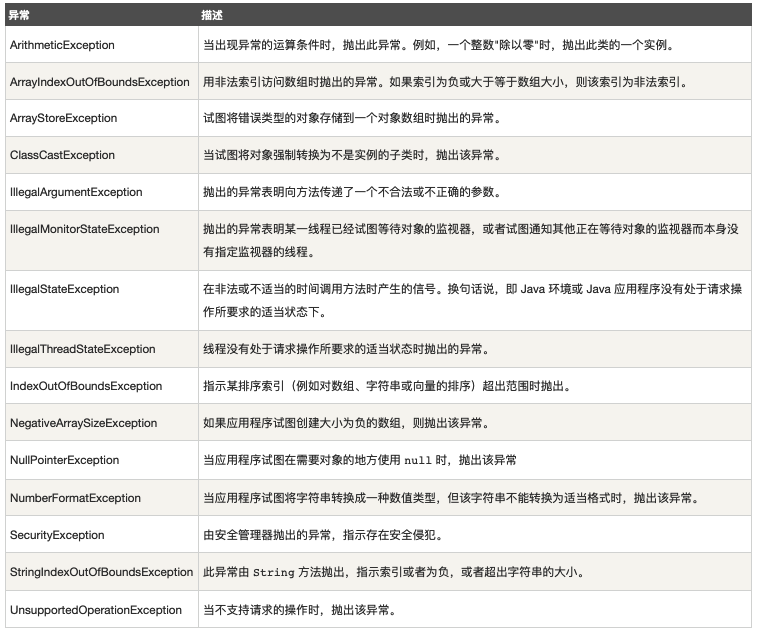
下面 👇 罗列出了一些常用的 Java 自带的异常类:
非受查异常:
受查异常:

# 自定义异常类
如果任何标准的异常类都不能满足你的需求, 你可以自己创建异常类.
自定义异常类是派生自 Exception 类, 或其子类的类;
🌰 示例:
// 文件名 InsufficientFundsException.java
import java.io.*;
//自定义异常类,继承Exception类
public class InsufficientFundsException extends Exception
{
//此处的 amount 用来储存当出现异常(取出钱多于余额时)所缺乏的钱
private double amount;
public InsufficientFundsException(double amount)
{
this.amount = amount;
}
public double getAmount()
{
return amount;
}
}
下面 👇 是对这个异常的使用:
public void withdraw(double amount) throws InsufficientFundsException
{
if(amount <= balance)
{
balance -= amount;
}
else
{
double needs = amount - balance;
throw new InsufficientFundsException(needs);
}
}
自定义异常类里可以定义一个接收字符串参数的构造函数, 字符串会作为异常的描述信息;
超类 Throwable 的 toString 方法可以打印这个信息, 这在调试时非常有用;
🌰 例如:
class FileFormatException extends IOException {
public FileFormatException() {}
public FileFormatException(String errMsg) {
super(errMsg);
}
}
下面 👇 是 Throwable 类的常用方法:

# 捕获异常
- 如果异常发生时没有地方对其进行捕获, 程序就会终止, 并在控制台打印异常信息;
- 想要捕获一个异常, 需要使用
try/catch语句块;

- 在
catch子句中需要声明异常类型; - 如果
try代码块中抛出一个类型匹配的异常对象,catch就会捕获这个异常, 并且执行它下面代码块中的代码; - 如果
try代码块抛出的异常与catch子句中的异常类型不匹配, 则直接退出程序, 并在控制台打印异常信息;

- 在上面 👆 的
read方法中, 可能会抛出 IOExpection 异常, 但是如何处理异常应该是方法调用者的事情, 我们不应该管, 更好的做法是只用throws声明read方法可能会抛出异常, 把异常传递给调用者;

- 对于我们知道如何处理的异常, 应该使用
try/catch进行捕获, 并处理; - 对于不知道如何处理的异常, 应该把异常抛出传递给上一级;
- ⚠️ 注意, Java 不允许在子类方法的
throws说明符中出现超过超类方法所声明的异常范围;- 如果在子类中, 编写一个覆盖超类的方法, 但是方法又可能抛出超出父类方法声明的异常范围时, 我们就必须在方法中使用
try/catch对异常进行捕获并处理;
- 如果在子类中, 编写一个覆盖超类的方法, 但是方法又可能抛出超出父类方法声明的异常范围时, 我们就必须在方法中使用
# 捕获多个异常
- 在一个
try语句块后面可以写多个catch去捕获多个异常;

- 同一个
catch子句中也可以捕获多个异常类型; - 使用
|操作符来匹配多个异常类型;

- 捕获多个异常时, 异常变量隐含为
final变量, 不可以更改异常变量的值;
# 再次抛出异常
- 在
catch代码块中, 可以再抛出一个异常;

# finally
- 当代码遇到异常, 就会终止程序, 所以剩余的代码也就不会被执行;
- 如果程序在异常出现之前获取了一些资源, 并且资源需要在程序结束前被回收. 如果出现异常, 程序中途停止, 资源就不会被回收.
finally代码块中的代码, 无论try中是否出现异常, 它都会执行;
InputStream in = new FileInputStream();
try {
...
} catch (IOException e) {
...
} finally {
in.close();
}
- 上面代码中, 无论
try语句块内是否发生异常,finally代码块中的in.close()都会执行; - ⚠️ 注意, 假如
try代码块中包含return语句. 而方法返回之前,finally代码块会被执行, 如果finally里面也有return语句, 那么这个返回值就会覆盖try里面的返回值;

finally代码块中也是有可能发生异常, 可以通过如下 👇 的写法来同时捕获try和finally里面的异常;

# 带资源的 try 语句
上面 👆 同时捕获 try 和 finally 里面的异常会带来一个问题.
如果 try 和 finally 代码块里同时出现异常, 那么 finally 里面的异常会被抛出, try 里面的异常会丢失.
但是一般情况下, 我们可能更加关心 try 里面的异常;
通过带资源的 try 语句可以解决这种问题.
- 带资源的
try语句格式如下 👇:

try后面的括号里可以写多行声明, 每个声明的变量类型必须都是 AutoCloseable 的子类;- 每条声明用分号
;隔开; - AutoCloseable 接口声明了一个
close()方法;void close() throws Exception;
- 假设资源属于一个实现了 AutoCloseable 接口的类, 那么就可以写在括号里面了;
try代码块退出时, 会自动调用括号中声明的资源实例的close方法去关闭资源;- 这样就不需要在
finally代码块中去关闭资源了;

- 如果
try和finally里面都出现了异常, 那么会抛出try里面的异常,finally的异常会被抑制;
# 分析堆栈轨迹
- 堆栈轨迹 stack trace 是一个方法调用过程的列表, 它包含了程序执行过程中方法调用的特定位置;
🌰 例如, 下面是 👇 是递归斐波那契函数的堆栈情况:


下面 👇 是和异常相关的接口/类里面的常用方法:



# 泛型
# 什么是泛型
- 『 泛型 』就是通用的类型;
- 为了解决 "在一开始不确定该是什么类型,在使用的时候才能确定是什么类型" 的问题;
下面 👇 的例子中体现了为什么要使用泛型:
// 声明了集合,里面可以存任何类型的元素
// 希望有办法来约束集合当中只能存某一种类型
List list = new ArrayList();
list.add(1);
list.add("abc")
// 不确定创建时传入什么类型的值
// 不用泛型的话,就要写很多个属性
class Point {
private String x1;
private String y1;
private Integer x2;
private Integer y2;
private Double x3;
private Double y3;
}
- 想定义一个泛型类, 在类名的后面加上
<T>. - T 代表不确定的类型, 被称为『 类型变量 』;
- 类型变量在类中指定方法的返回类型, 或者属性和局部变量的类型;
- 因为 T 只是代表不确定的类型,这里也可以写成别的字母,A,B,C 也可以;
- 在创建对象的时候,要指明类型变量的具体类型;
- 🌰
Point<String> p = new Point<String>(); - 如果没有指明,它就默认是 Object 类型;
- 🌰
- 从 Java 7 开始, 前面对象声明里已经写了具体类型, 后面调用构造函数时, 就可以省略了, 只写
<>;- 🌰
Point<String> p = new Point<>();
- 🌰
class Point<T> {
T x;
T y;
}
Point<String> p = new Point<String>();
p.x = "123";
p.y = "456";
// 可以省略构造函数中的 String
Point<String> p = new Point<>();
p.x = "123";
p.y = "456";
下面 👇 用泛型声明了一个集合, 集合内中能存放 String 类型实例对象;
// 指定集合内只能是字符串类型
ArrayList<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
list.add(1); // 这一条代码,就会报错,因为它不是字符串类型
上面 👆 定义的都是泛型类, 下面来介绍如何定义一个带有类型参数的『 泛型方法 』.
泛型类:在类上面定义的泛型,在创建对象的时候,指定泛型的类型;
泛型方法:在方法上定义的泛型,在调用时,通过传入参数指定具体类型;
泛型方法既可以定义在普通类中, 也可以定义在泛型类中;
泛型方法的类型变量
<T>放在修饰符后面, 返回类型前面;当调用一个泛型方法时, 在方法名前的尖括号中放入具体的类型;
在绝大多数情况下, 可以省去类型参数, 编译器可以根据传入的参数猜出具体类型;
class ArrayAlg {
public static <T> T getMiddle(T... a) {
return a[a.length / 2];
}
}
String middle = ArrayaAlg.<String>getMiddle("John", "Tony", "HAHAHA");
// 可以省略 <String>
String middle = ArrayaAlg.getMiddle("John", "Tony", "HAHAHA");
- Java 允许同时定义多个类型变量:
public class Pair<T, U> {
private T first;
private U second;
public Pair(T first, U second) {
this.first = first;
this.second = second;
}
}
Pair<Integer, Double> p = new Pair<>(1221, 12.21);
下面 👇 来整体的看一些 🌰 例子:
public class GenericTest {
//这个类是个泛型类
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
// 虽然在方法中使用了泛型,但是这并不是一个泛型方法。
// 这只是类中一个普通的成员方法,只不过他的返回值是在声明泛型类时定义的类型参数
public T getKey(){
return key;
}
}
// 这才是一个真正的泛型方法。
// 在 public 与返回值之间的 <T> 必不可少,这表明这是一个泛型方法
public <T> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
//当然这个例子举的不太合适,只是为了说明泛型方法的特性。
T test = container.getKey();
return test;
}
//这也不是一个泛型方法,这就是一个普通的方法,指定了参数必须是 Generic<Number> 类型
public void showKeyValue1(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
}
# 泛型的上限 & 下限
- 泛型的上限,用来限定对象的类型必须是指定类型的子类, 或指定类型;
- 泛型的下限,用来限定对象的类型必须是指定类型的父类, 或指定类型;
// 指定上限,传入的必须是 Number 的子类或指定类型;
void test1(List<T extends Number> list) {}
// 指定下限,传入的必须是 Number 的父类或指定类型;
void test2(List<T super Number> list) {}
extends和super关键字后面的限定类型, 也可以是接口;
public static <T extends Comparable> T min(T[] a) { ... }
- 通过
&可以指定多个限定类型; - 但因为 Java 中一个类至多只能继承一个类, 所以
&合并的都是接口; - 如果同时出现限定类和限定接口, 将限定类放在第一位;
T extends Integer & Comparable & Serializable
# 类型擦除
泛型是 1.5 版本以后才加入的, 为了让泛型代码能够很好的和之前的代码兼容. ✏️ 泛型信息只存在于代码编译阶段, 在进入 JVM 之前, 和泛型相关的信息会被擦除掉, 这被称作『 类型擦除 』
也就是说擦除完的泛型类/方法, 和普通的类/方法没有什么区别.
在类型擦除的时候:
- ✏️ 之前类型参数如果没限定类型,则泛型类型会被替换成 Object 类型. 🌰 例如:
<T> - ✏️ 如果指定限定类型, 则泛型类型就被替换成限定类型。🌰 例如:
<T extends String>
🌰 例子:
下面 👇 的 Pair<T> 在经过类型擦除之后, 内部的 T 都被替换成了 Object:


Tip:
这里理解成『 类型替换 』更直观一点.
当程序调用泛型方法时, 如果泛型类型作为方法的返回类型, 但是泛型类型已经被擦除了, 编译器此时就会插入强制的类型转换.
Employee a = new Employee('A');
Employee b = new Employee('B');
Pair<Employee> buddies = new Pair<>(a, b);
// 擦除类型后, getFirst 返回 Object 类型对象
// 编译器在这里强制转换成 Employee 类型
Employee buddy = buddies.getFirst();
# 类型擦除带来的约束 & 局限性
下面 👇 讨论一下使用泛型时的一些限制.
✏️ 不能用基本类型作为类型参数:
int,double这些基本类型不能作为泛型的类型参数;- 🌰
Pair<Double>不能写成Pair<double>; - 原因是 Double 类型会被擦除成 Object 类型, 而 Object 类型对象不能储存 double 类型的值;
✏️ instanceof 不能用于泛型类:
因为类型擦除的存在, 所以不能用 instanceof 去验证一个实例是否属于一个泛型类;
a instanceof Pair<String> // Error
a instanceof Pair<T> // Error
✏️ 不能创建参数化类型的数组:
不能创建参数化类型的数组。例如,下面的代码不能编译:
List<Integer>[] arrayOfLists = new List<Integer>[2]; // compile-time error
原因是, 在声明数组时, 我指定了 List 的类型参数是 Integer. 但是类型擦除让 Integer 被替换成 Object 了.
List<Integer>[] 数组就变成了 List<Object>[] 类型的数组.
这个时候, 如果我执行 arrayOfLists[0] = new List<Boolean>() 也是能够通过数组的类型检查的.
但是这种操作是存在错误的, 所以出于这个原因, 就不允许创建参数化类型的数组.
✏️ 不能实例化类型变量:
不能创建一个类型参数的实例。例如,下面的代码导致编译时错误:
public static <E> void append(List<E> list) {
E elem = new E(); // compile-time error
list.add(elem);
}
作为解决方法,可以通过反射来创建类型参数的对象:
public static <E> void append(List<E> list, Class<E> cls) throws Exception {
E elem = cls.newInstance(); // OK
list.add(elem);
}
List<String> ls = new ArrayList<>();
append(ls, String.class);
✏️ 不能构造泛型数组:
和上面不能用类型参数实例化一个实例一样, 也不能实例化数组.
下面的代码是不能执行的:
T[] array = new T[10]; // Error
✏️ 泛型类的静态上下文中的类型变量无效:
不能再静态域或方法中引用类型变量

原因很简单, 因为静态域和方法被所有类型的实例共享. 那么到底采用哪个实例类型变量的值呢? 所以不能用.
✏️ 不能抛出或捕获泛型类的实例:
不能再 catch 的子句中使用类型变量.

# 通配符类型
无界通配符:
- 当方法需要接受一个泛型类对象实例,但是却不知道对象的具体类型;
- 可以使用通配符
?来定义参数;
// 使用通配符,表明还不确定 List 内泛型的类型
void test(List<?> list) {}
List<Integer> list = new ArrayList<>();
test(list);
下面 👇 这种方式是不对 ❌ 的:
- 即使 Integer 是 Number 的子类, 下面的写法也会报错;
- 需要使用
?通配符才可以;
void test(List<Number> list) {}
List<Integer> list = new ArrayList<>();
test(list);
上界通配符:
可以使用上界的通配符来放宽对变量的限制.
🌰 例如,假设你想要写上面 👆 的 test 方法同时可以接收 List <Integer> 、 List<Double> 和 List<Number> 你可以通过使用上界的通配符来实现这一点。
void test(List<? extends Number> list) {}
下界通配符:
? 后面接 super 关键字就可以指定泛型实例的类型变量, 必须是某个类型的父类或其自身.
public static void addNumbers(List<? super Integer> list) {
for (int i = 1; i <= 10; i++) {
list.add(i);
}
}
# 集合
集合可以看作是一种容器,用来存储对象信息。
数组与集合的区别:
- 数组长度不可变化, 而且无法保存具有映射关系的数据;
- 集合类用于保存数量不确定的数据,以及保存具有映射关系的数据;
- 数组元素既可以是基本类型的值,也可以是对象. (基本类型会被装箱)
- 集合只能保存对象;
- 数组只能储存同一种类型的元素;
- 集合可以储存不同类型的元素;
Java 的集合类库将接口与实现分离.
Java 集合框架为不同类型的集合定义了大量接口. 其中集合类的基本接口是:
- Collection 接口: 存储一组对象实例;
- Map 接口 存储键/值对映射;
- 根据这两个基本接口, 有扩展出了很多不同类型的集合接口;
- 根据这些接口, 又扩展出很多抽象类;
- 再之下是各种集合具体的实现类;
- 所有的集合类都是由 Collection 接口, 和 Map 接口派生出来的;

下表 👇 简要描述了每个集合类的用途:

下图 👇 展示了不同集合的特性:
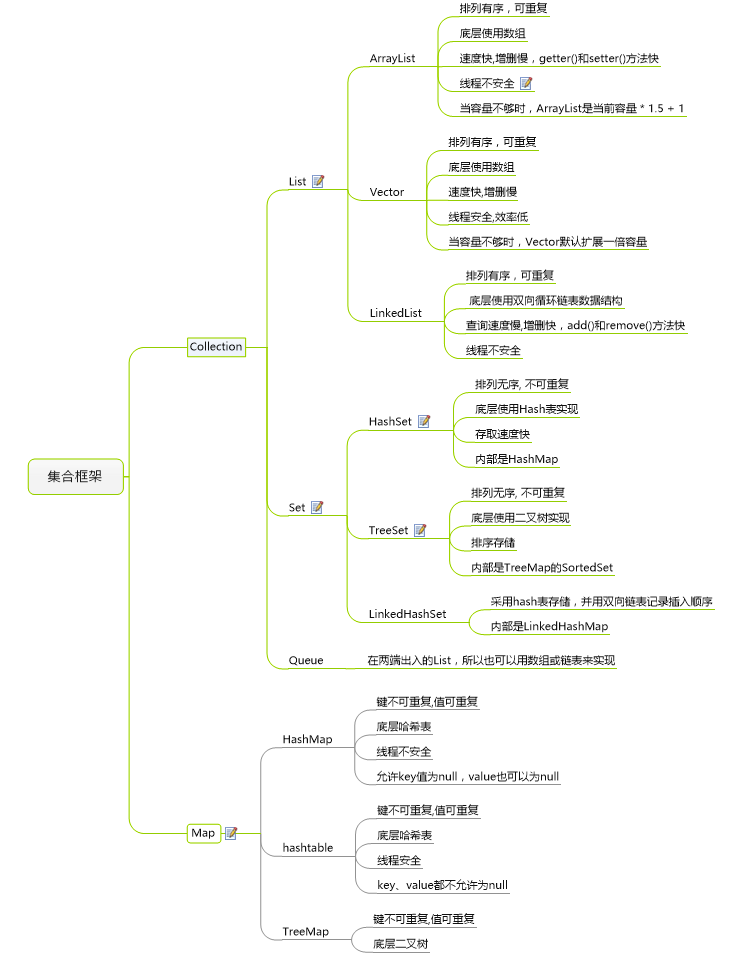
# Collection 接口
Collection 接口中定义了如下方法:

# Iterable & Iterator
- Collection 接口扩展了 Iterable 接口.
- Iterable 接口只有一个方法
iterator, 它返回一个在一组实例对象上进行迭代的迭代器. - 迭代器实现了 Iterator 接口.
Iterator 接口中定义的方法如下:

- 迭代器可以用来发访问集合中的每个元素;
- 调用
next方法返回迭代的下一个元素, 如果到达了集合的末尾, 会抛出一个异常; - 因此, 需要在每次调用
next方法前, 调用hasNext方法, 去判断是否后面仍有元素可用于迭代; - 如果
hasNext返回true, 就可以调用next;
// 创建集合
Collection c = new ArrayList();
c.add(new Person("小红"));
c.add(new Person("小明"));
c.add(new Person("小张"));
// 创建集合的迭代器
Iterator it = c.iterator();
// 通过 hasNext 方法判断,迭代器中是否还有元素
while(it.hasNext()) {
Object item = it.next();
}
Java 编译器为实现了 Iterable 接口的集合提供 for-each 语法糖, 可以使用更简洁的写法去进行遍历.
List<String> ls = new ArrayList<>();
ls.add("abc");
ls.add("def");
ls.add("ghi");
for (String s: ls) {
System.out.println(s);
}
# List 接口
- List 是元素有序并且可以重复的集合,被称为序列;
- 可以根据元素的整数索引(在列表中的位置)访问元素,或针对指定位置精确添加/删除元素;
- 下面具体实现类有:
- ArrayList;
- LinkedList;
- Vector (已过时);


# ListIterator
List 接口中定义了方法, 用以获取特殊的迭代器 ListIterator, 称为『 列表迭代器 』
除了允许 Iterator 接口提供的正常操作外,该迭代器还允许在遍历时, 向集合中插入/替换元素,以及双向访问。
List 接口还提供了一个方法, 来获取从列表中指定位置开始的列表迭代器。

ListIterator 接口中的方法 👇:

# ArrayList
- 集合中元素排列有序, 可以重复;
- 底层使用数组实现;
- 增加/删除元素, 速度慢;
- 使用
get和set进行随机访问, 速度快; - 当容量不够时, 可以自动扩容;
- ArrayList 线程是不同步的:
- 如果多个线程同时访问一个 ArrayList 实例,而其中至少一个线程从结构上修改了列表,那么它必须保持外部同步;
- 结构上的修改, 是指任何添加/删除一个或多个元素的操作,或者显式调整底层数组的大小. 仅仅设置元素的值不是结构上的修改;
- 因此使用迭代器遍历集合过程中,不可用其他方式修改集合结构,否则会引发异常;
- 只能用迭代器自身的
remove或add方法从结构上对列表进行修改;
// ArrayList 用法示例
ArrayList<String> arrayList = new ArrayList<String>();
arrayList.add("Evankaka");
arrayList.add("sihai");
arrayList.add("德德");
arrayList.add("Evankaka");
arrayList.add("小红");
// 将索引位置为 2 的对象修改
arrayList.set(2, "sihai2");
// 将对象添加到索引位置为 3 的位置
arrayList.add(3, "好好学java");
// 结果: Evankaka sihai sihai2 好好学java Evankaka 小红
// 遍历方法 1
Iterator<String> it = arrayList.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
// 遍历方法 2
for(Object o : arrayList){
System.out.println(o);
}
// 遍历方法 3
for(int i = 0; i < arrayList.size(); i++){
System.out.println(arrayList.get(i));
}
// 删除元素
arrayList.remove("Evankaka");
arrayList.remove(0);
it = arrayList.iterator();
while (it.hasNext()) {
String s = it.next();
if(s.equals("好好学java")){
it.remove();
}
}
# LinkedList
🔗 LinkedList 类 API 文档 🔗 Deque 接口 API 文档
- 集合元素排列有序, 可重复;
- 使用『 双向循环链表 』实现;
- 查询速度慢;
- 增加/删除元素, 速度快;
- 和 ArrayList 一样, 线程是不同步的;
- 除了实现 List 接口外,LinkedList 类还实现了 Deque 接口, 以使得 LinkedList 能够用作堆栈、队列或双端队列;
LinkedList 基本操作:
LinkedList<String> lList = new LinkedList<String>();
// 添加元素
lList.add("1");
lList.add("2");
lList.add("3");
lList.add("4");
lList.remove(); // 获取并移除此列表的第一个元素
lList.remove(2); // 获取并移除此列表中指定位置的元素;
lList.clear(); // 清空列表
// 将 LinkedList 转换成 ArrayList
ArrayList<String> arrayList = new ArrayList<>(linkedList);
// 将 ArrayList 转换成 LinkedList
LinkedList<String> linkedList = new LinkedList<>(arrayList);
LinkedList 实现队列效果:
class Queue {
private LinkedList list = new LinkedList();
public void put(Object v) {
list.addFirst(v);
}
public Object get() {
return list.removeLast();
}
}
LinkedList 实现堆栈效果:
class StackL {
private LinkedList list = new LinkedList();
public void push(Object v) {
list.addFirst(v);
}
public Object pop() {
return list.removeFirst();
}
}
# Vector
- Vector 和 ArrayList 相似, 都是基于数组实现的, 有序的, 可以动态扩容的集合类;
- 但是 Vector 方法调用是线程同步的;
- 可以允许多个线程同时安全地访问一个 Vector 实例;
- 但是同步操作需要耗费大量时间, 在性能上会有损耗;
- 在大多数情况下, 并不需要使用 Vector, ArrayList 就可以了;
⚠️ 更具体的这里先略过.......
# Set 接口
- Set 是元素不重复,排列无顺序的集合;
- 主要有如下实现类:
- HashSet;
- LinkedHashSet;
- TreeSet;

# HashSet
- 底层使用 Hash 表实现;
- 添加/删除/访问元素的速度快;
- 在将对象添加进 HashSet 集合中前, 会调用对象实例的
hashCode方法来计算出哈希值;- 如果想添加自定义的对象, 就要在定义类时重写
hashCode方法; - 同样的对象实例, 调用
hashCode方法的结果相同;
- 如果想添加自定义的对象, 就要在定义类时重写

- 根据算出的哈希值, 再计算出要在集合中储存位置的下标, 如果下标位置为空, 就直接储存;
- 如果已经被占, 就将要储存的元素, 与已有元素进行
equals比较, 如果相同, 就不存了. 如果不同, 就存到下标位置对应的链表中;
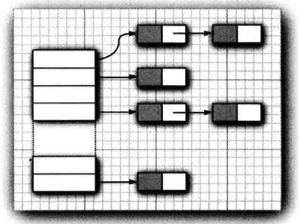
📚 利用 HashSet 来存取自定义对象实例:
public class Person {
// 属性
private String name;
private int age;
// 构造方法
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
// 要让哈希表存储不重复的元素,就必须重写hasCode和equals方法
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
// 利用 HashSet 来存取自定义对象 Person
Set<Person> set = new HashSet<Person>();
set.add(new Person("张三", 12));
set.add(new Person("李四", 13));
set.add(new Person("王五", 22));
set.add(new Person("张三", 12)); // 已经有一个张三了, 这个就不存了
# TreeSet
- TreeSet 是一个有序集合;
- 可以以任意顺序将元素存入进去. 但是对集合遍历时, 每个元素会按照排序后的顺序呈现;
- 使用红黑树实现;
- 因为存入 TreeSet 集合的元素是有顺序的, 所以元素间必须能够比较;
- 存入的对象必须实现了 Comparable 接口;
- 或者在创建 TreeSet 实例时, 向构造器中传入实现了 Comparator 接口并重写了
compare方法的实现类实例; - 如果都没有, 则 TreeSet 抛出异常;
📚 下面用两种方式储存自定义对象到 TreeSet:
public class Person implements Comparable<Person>{
// 属性
private String name;
private int age;
// 构造方法
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
...
// 比较规则是先按照 年龄排序,年龄相等的情况按照年龄排序
@Override
public int compareTo(Person o) {
int result = this.age - o.age;
if (result == 0){
return this.name.compareTo(o.name);
}
return result;
}
}
// 利用 TreeSet 来存储自定义类 Person 对象
TreeSet<Person> treeSet = new TreeSet<Person>();
treeSet.add(new Person("张山1", 20));
treeSet.add(new Person("张山2", 16));
treeSet.add(new Person("张山3", 13));
treeSet.add(new Person("张山4", 17));
treeSet.add(new Person("张山5", 20));
// 利用 TreeSet 来存储自定义类 Person 对象
// 创建 TreeSet 对象的时候传入 Comparator 比较器,使用匿名内部类的方式.
TreeSet<Person> treeSet = new TreeSet<Person>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
if (o1 == o2){
return 0;
}
int result = o1.getAge() - o2.getAge();
if (result == 0){
return o1.getName().compareTo(o2.getName());
}
return result;
}
});
treeSet.add(new Person("张山1", 20));
treeSet.add(new Person("张山2", 16));
treeSet.add(new Person("张山3", 13));
treeSet.add(new Person("张山4", 17));
treeSet.add(new Person("张山5", 20));
# LinkedHashSet
- 采用哈希表储存, 用双向链表来记录插入顺序;
- 集合中的元素可以有序地迭代;
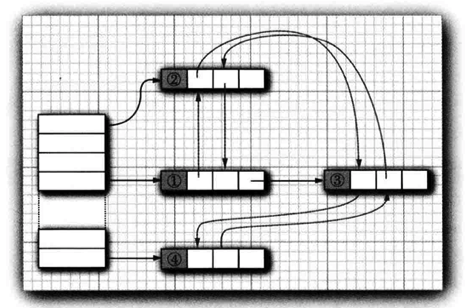
LinkedHashSet<Person> set = new LinkedHashSet<Person>();
set.add(new Person("张三", 12));
set.add(new Person("李四", 13));
set.add(new Person("王五", 22));
set.add(new Person("张三", 12));
// 遍历
for (Person p : set){
System.out.println(p);
}
// 结果:
// Person [name=张三, age=12]
// Person [name=李四, age=13]
// Person [name=王五, age=22]
# Queue 接口
- 队列集合以 FIFO(先进先出)的方式存储各个元素;
- Deque 接口支持在两端插入/删除元素, 称作双端队列;
- ArrayDeque 类和 LinkedList 类实现了 Deque 接口;
- Queue 接口中的每种操作都存在两种形式, 操作失败时:
- 一种抛出异常;
- 另一种返回一个特殊值(null 或 false)

# ArrayDeque
- 用数组来实现的队列;
- 在用作堆栈时, 与 LinkedList 相比, 它随机访问性能更好;
- Stack 类继承自 Vector 类, 因为线程同步的原因, ArrayDeque 访问速度也更快;
# PriorityQueue
- 也称为『 优先级队列 』;
- 实现逻辑是『 堆 』也称『 完全二叉树 』, 具体实现是数组;
- 可以按照任意顺序插入元素, 但是总是按照排序的顺序进行检索;
- 无论何时, 调用
remove总会先删除优先级最高的元素; - 与 TreeSet 一样, PriorityQueue 既可以保存实现了 Comparable 接口的类对象, 也可以在构造器中直接传入实现了 Comparator 接口并重写了 compare 方法的实现类实例;
- 使用优先级队列的典型示例是『 任务调度 』, 每一个任务有一个优先级, 任务以随机顺序添加到队列中, 每当启动一个新的任务时, 都将优先级最高的任务从队列中删除.
# Map 接口
- Map 集合用来存放键值对映射;
- 通过『 键 』可以快速找到对应的『 值 』;

# HashMap
- 排列无序, 键不可重复;
- 基于哈希表实现;
- 储存自定义对象, 要保证键的唯一性,需要覆盖自定义类的
hashCode方法,和equals方法;
HashMap users = new HashMap();
users.put("11", "张浩太"); // 将学生信息键值对存储到Map中
users.put("22", "刘思诚");
users.put("33", "王强文");
users.put("44", "李国量");
users.put("55", "王路路");
// 通过 keySet 获得所有键组成的 Set 集合
Iterator it = users.keySet().iterator();
while (it.hasNext()) {
// 遍历 Map
Object key = it.next();
Object val = users.get(key);
}
// 通过 values 获取所有值组成的集合
Collection<String> vs = users.values();
Iterator it = vs.iterator();
while (it.hasNext()) {
String value = it.next();
}
# TreeMap
- 基于红黑树实现;
- TreeMap 可以对集合中元素的键进行排序;
- 和 TreeSet 一样原理,需要让存储在键位置的对象实现 Comparable 接口,重写
compareTo方法; - 或者在创建 TreeMap 实例时, 向构造器中传入实现了 Comparator 接口并重写了
compare方法的实现类实例;
Map<String, Integer> map = new TreeMap<>();
map.put("orange", 1);
map.put("apple", 2);
map.put("pear", 3);
// apple, orange, pear
public class Main {
public static void main(String[] args) {
Map<Person, Integer> map = new TreeMap<>(new Comparator<Person>() {
public int compare(Person p1, Person p2) {
return p1.name.compareTo(p2.name);
}
});
map.put(new Person("Tom"), 1);
map.put(new Person("Bob"), 2);
map.put(new Person("Lily"), 3);
for (Person key : map.keySet()) {
System.out.println(key);
}
// {Person: Bob}, {Person: Lily}, {Person: Tom}
}
}
class Person {
public String name;
Person(String name) {
this.name = name;
}
public String toString() {
return "{Person: " + name + "}";
}
}
# 并发
- 进程: 一整个任务称为一个进程;
- 🌰 浏览器就是一个进程,视频播放器是一个进程, 音乐播放器和 Word 都是进程;
- 线程: 进程内部还需要同时执行多个子任务, 这些子任务被称作线程;
- 一个进程可以包含一个或多个线程,但至少会有一个线程;
- 🌰 Word 可以让我们一边打字,一边进行拼写检查;
- 🌰 浏览器同时打开多个页面, 同时下载多个图片;

想在一个程序中执行多任务, 既可以由『 多进程实现 』,也可以由『 单进程内的多线程实现 』,还可以『 混合多进程+多线程 』

具体采用哪种方式,要考虑到进程和线程的特点:
- 创建进程比创建线程开销大;
- 进程独享一套自己的数据, 线程之间共享数据;
- 共享数据使得线程之间通信比进程更高效;
- 多进程稳定性比多线程高:
- 在多进程的情况下,一个进程崩溃不会影响其他进程;
- 在多线程的情况下,一个线程崩溃会直接导致整个进程崩溃;
# 多线程基础
- Java 语言内置了多线程支持;
- 一个 Java 程序实际上是一个 JVM 进程;
- JVM 进程用一个主线程来执行
main()方法,在main()方法内部,我们又可以启动多个线程; - 和单线程相比,多线程经常需要读写共享数据,并且需要同步. 这使得多线程编程的复杂度高,调试更困难;
- Java 的网络、数据库、Web 开发等, 都依赖 Java 多线程编程;
# 创建新线程
创建一个新线程非常容易,我们需要实例化一个 Thread 实例,然后调用它的 start() 方法;
Thread t = new Thread();
t.start(); // 启动新线程
但是这个线程启动后实际上什么也不做就立刻结束了。我们希望新线程能执行指定的代码,有以下几种方法:
📚 方法一: 从 Thread 派生一个自定义类,然后覆写 run() 方法:
public class Main {
public static void main(String[] args) {
Thread t = new MyThread();
t.start(); // 启动新线程
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println("start new thread!");
}
}
📚 方法二: 创建 Thread 实例时,传入一个 Runnable 实例:
public class Main {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start(); // 启动新线程
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("start new thread!");
}
}
用 Lambda 语法进一步简写为:
public class Main {
public static void main(String[] args) {
Thread t = new Thread(() -> {
System.out.println("start new thread!");
});
t.start(); // 启动新线程
}
}
在多个线程同时执行时, 执行顺序由操作系统调度,程序本身无法确定线程的调度顺序.
为了让线程按想要的顺序执行, 可以在线程中调用 Thread.sleep(),强迫当前线程暂停一段时间:
sleep()传入的参数是毫秒;
public class Main {
public static void main(String[] args) {
System.out.println("main start...");
Thread t = new Thread(() -> {
System.out.println("thread run...");
try {
Thread.sleep(10);
} catch (InterruptedException e) {}
System.out.println("thread end.");
});
t.start();
try {
Thread.sleep(20);
} catch (InterruptedException e) {}
System.out.println("main end...");
}
}
// 结果:
// main start...
// thread run...
// thread end.
// main end...
可以对线程设定优先级,设定优先级的方法是 Thread.setPriority(int n) 参数取值范围 1~10, 1 最低, 10 最大, 默认值 5.
- 优先级高的线程被操作系统调度的优先级较高;
- 操作系统对高优先级线程可能调度更频繁;
- 但不能通过设置优先级来确保高优先级的线程一定会先执行;
public class Main {
public static void main(String[] args) {
Thread t = new MyThread();
t.setPriority(10);
t.start();
}
}
# 线程的状态
在 Java 程序中,一个线程对象只能调用一次 start() 方法启动新线程,并在新线程中执行 run() 方法。一旦 run() 方法执行完毕,线程就结束了。因此,Java 线程的状态有以下几种:
- New:新创建的线程,尚未执行;
- Runnable:运行中的线程,正在执行 run()方法的 Java 代码;
- Blocked:运行中的线程,因为某些操作被阻塞而挂起;
- Waiting:运行中的线程,因为某些操作在等待中;
- Timed Waiting:运行中的线程,因为执行
sleep()方法正在计时等待; - Terminated:线程已终止,因为
run()方法执行完毕。
一个线程还可以通过 join() 方法等待另一个线程运行结束后在运行:
public class Main {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
System.out.println("hello");
});
System.out.println("start");
t.start();
t.join();
System.out.println("end");
}
}
// 结果:
// start
// hello
// end
- 在
main中让t调用join方法; - 主线程会等待
t变量所表示的线程结束后在运行;
# 中断线程
线程终止的原因有:
- 线程正常终止:
run()方法执行到return语句返回; - 线程意外终止:
run()方法因为未捕获的异常导致线程终止; - 对线程的 Thread 实例调用
stop()方法强制终止;stop是通过立即抛出 ThreadDeath 异常,来达到停止线程的目的, 可能会造成线程安全问题;- 不建议使用
stop强制终止线程;
- 对线程实例调用
interrupt方法可以给线程发送一个停止信号, 目标线程会反复检查自身是否为interrupted状态, 如果是就结束运行;
public class Main {
public static void main(String[] args) throws InterruptedException {
Thread t = new MyThread();
t.start();
Thread.sleep(1); // 暂停1毫秒
t.interrupt(); // 中断t线程
t.join(); // 等待t线程结束
System.out.println("end");
}
}
class MyThread extends Thread {
public void run() {
int n = 0;
while (! isInterrupted()) {
n ++;
System.out.println(n + " hello!");
}
}
}
- 上面 👆 代码中, 在
main线程中调用t.interrupt()方法中断t线程; interrupt()方法仅仅向t线程发出了“中断请求”;t线程的while循环会检测isInterrupted()来判断自己是否处于interrupted状态. 并据此来做出一些操作;
public class Main {
public static void main(String[] args) throws InterruptedException {
Thread t = new MyThread();
t.start();
Thread.sleep(1000);
t.interrupt(); // 中断t线程
t.join(); // 等待t线程结束
System.out.println("end");
}
}
class MyThread extends Thread {
public void run() {
Thread hello = new HelloThread();
hello.start(); // 启动hello线程
try {
hello.join(); // 等待hello线程结束
} catch (InterruptedException e) {
System.out.println("interrupted!");
}
hello.interrupt();
}
}
class HelloThread extends Thread {
public void run() {
int n = 0;
while (!isInterrupted()) {
n++;
System.out.println(n + " hello!");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
break;
}
}
}
}
- 如果线程处于等待状态,例如,
t.join()会让main线程进入等待状态; - 此时,如果对
main线程调用interrupt(),join()方法会立刻抛出 InterruptedException; - 因此,目标线程只要捕获到
join()方法抛出的 InterruptedException,就说明有其他线程对其调用了interrupt()方法,通常情况下该线程应该立刻结束运行; - 在上面 👆 的例子中:
- main 线程通过调用
t.interrupt()从而通知t线程中断,而此时 t 线程正位于hello.join()的等待中,此方法会立刻结束等待并抛出 InterruptedException; - 由于我们在
t线程中捕获了 InterruptedException,因此,就可以准备结束该线程; - 在
t线程结束前,对hello线程也进行了interrupt()调用通知其中断。如果去掉这一行代码,可以发现hello线程仍然会继续运行,且 JVM 不会退出;
- main 线程通过调用
另一个常用的中断线程的方法是设置『 标志位 』:
- 通常会用一个
running标志位来标识线程是否应该继续运行; - 在外部线程中,通过把线程实例的
running属性置为false,就可以让线程结束;
public class Main {
public static void main(String[] args) throws InterruptedException {
HelloThread t = new HelloThread();
t.start();
Thread.sleep(1);
t.running = false; // 标志位置为false
}
}
class HelloThread extends Thread {
public volatile boolean running = true;
public void run() {
int n = 0;
while (running) {
n ++;
System.out.println(n + " hello!");
}
System.out.println("end!");
}
}
- 👆 上面的
running属性, 声明时使用volatile关键字标记; - volatile 关键字用于声明线程间共享变量;
- 在一个线程中修改了变量值, 再其他线程中能同步读取到最新的值;

- 在 Java 虚拟机中,变量的值保存在主内存中,但是,当线程访问变量时,它会先获取一个副本,并保存在自己的工作内存中;
- 如果线程修改了变量的值,虚拟机会在某个时刻把修改后的值回写到主内存,但是这个时间是不确定的;
- 这会导致如果一个线程更新了某个变量,另一个线程读取的值可能还是旧的. 这就造成了多线程之间共享的变量不一致;
volatile关键字的目的是告诉虚拟机:- 每次访问变量时,总是获取主内存的最新值;
- 每次修改变量后,立刻回写到主内存;
- 但这会造成性能的损耗;
# 守护线程
Java 程序入口就是由 JVM 启动
main线程,main线程又可以启动其他线程。当所有线程都运行结束时,JVM 退出,进程结束;如果有一个线程没有退出,JVM 进程就不会退出。所以,必须保证所有线程都能及时结束;
假如, 有一个线程在执行无限循环任务, 如果这个线程不结束,JVM 进程就无法结束. 那么由谁负责结束这个线程?
执行这种任务的线程可以使用『 守护线程 』;
守护线程(Daemon Thread)是指为其他线程服务的线程;
在 JVM 中,所有非守护线程都执行完毕后,无论有没有守护线程,虚拟机都会自动退出;
因此,JVM 退出时,不必关心守护线程是否已结束;
创建守护线程的方法和普通线程一样, 只是在调用
start()方法前,调用setDaemon(true)把该线程标记为守护线程;
Thread t = new MyThread();
t.setDaemon(true);
t.start();
# 实现 Runnable 接口
上面 👆 我们通过创建继承了 Thread 的对象实例, 来创建一个新线程;
我们还可以通过让一个类实现 Runnable 接口, 来让这个类的实例能够创建一个新线程, 并且执行其内部的代码;
Runnable 接口内部只有一个 run 方法, 它没有返回值, 使用 Runnable 的实现类实例创建一个线程时,在线程中会执行类实例的 run 方法。
因为 Java 只能单继承,因此如果是采用继承 Thread 的方法,那么在以后进行代码重构的时候就无法继承别的类了。
有经验的程序员往往都会选择实现 Runnable 接口来进行多线程编程.
其次,如果一个类继承 Thread,则不适合资源共享。但是如果实现了 Runable 接口的话,则很容易的实现资源共享。
🌰 下面来看一下 Thread 和 Runnable 它们使用上的区别:
public class TestThread extends Thread {
private int count = 5;
private String name;
public testThread(String name) {
this.name = name;
}
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(name + "运行 count= " + count--);
try {
sleep((int) Math.random() * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class main {
public static void main(String[] args) {
TestThread mTh1 = new TestThread("A");
TestThread mTh2 = new TestThread("B");
mTh1.start();
mTh2.start();
}
}
上面 👆 创建了两个 TestThread 类实例, 它们内部的属性属于各自的实例;
改成用 Runnable 接口实现类来写, 就可以很轻松做到资源共享:
public class TestRunnable implements Runnable {
private int count = 15;
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + "运行 count= " + count--);
try {
Thread.sleep((int) Math.random() * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class main {
public static void main(String[] args) {
TestRunnable mTh = new TestRunnable();
new Thread(mTh).start();
new Thread(mTh).start();
new Thread(mTh).start();
}
}
# 线程同步
当多个线程同时运行时,线程的调度由操作系统决定,程序本身无法决定。因此,任何一个线程都有可能在任何指令处被操作系统暂停,然后在某个时间段后继续执行。
这样的话, 如果多个线程同时读写共享变量,会出现数据不一致的问题.
因为对变量进行读取和写入时,结果要正确,必须保证是原子操作。原子操作是指不能被中断的一个, 或一系列操作。
- 🌰 例如,对于语句:
n = n + 1; - 看上去是一行语句,实际上对应了 3 条指令:
- ILOAD 读取;
- IADD 相加;
- ISTORE 储存;
假设 n 的值是 100,如果两个线程同时执行 n = n + 1,得到的结果很可能不是 102,而是 101,原因在于:
- 如果线程 1 在执行 ILOAD 后被操作系统中断;
- 此刻如果线程 2 被调度执行,它执行 ILOAD 后获取的值仍然是 100;
- 最终结果被两个线程的 ISTORE 写入后变成了 101,而不是期待的 102;
# 加锁 & 解锁
多线程模型下,要保证逻辑正确,对共享变量进行读写时,必须保证一组指令以『 原子方式 』执行:即某一个线程执行时,其他线程必须等待;
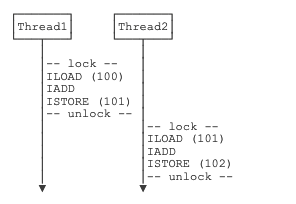
- 通过 加锁 和 解锁 的操作,就能保证一组指令在线程中执行时, 不能被打断;
- 加锁和解锁之间的代码块我们称之为 临界区, 任何时候临界区最多只有一个线程能执行;
- Java 程序使用
synchronized关键字对一个对象进行加锁;- 首先, 找出修改共享变量的线程中的代码块;
- 选择一个共享实例作为锁;
- 然后用
synchronized(lock) { ... }包裹这部分代码;
🌰 下面展示了如何在程序中使用 synchronized 定义一个临界区:
public class Main {
public static void main(String[] args) throws Exception {
var add = new AddThread();
var dec = new DecThread();
add.start();
dec.start();
add.join();
dec.join();
System.out.println(Counter.count);
}
}
class Counter {
public static final Object lock = new Object();
public static int count = 0;
}
class AddThread extends Thread {
public void run() {
for (int i=0; i<10000; i++) {
// 定义临界区
synchronized(Counter.lock) {
Counter.count += 1;
}
}
}
}
class DecThread extends Thread {
public void run() {
for (int i=0; i<10000; i++) {
// 定义临界区
synchronized(Counter.lock) {
Counter.count -= 1;
}
}
}
}
// 结果: 0
- 例子中, 用
Counter.lock实例作为锁; - 两个线程在执行各自的
synchronized(Counter.lock) { ... }代码块时,必须先获得锁,才能进入代码块。在synchronized语句块结束会自动释放锁; - 这样一来,对
Counter.count变量进行读写就不可能同时进行。上述代码无论运行多少次,最终结果都是 0;
在使用 synchronized 的时候,不必担心抛出异常。因为无论是否有异常,都会在 synchronized 结束处正确释放锁;
public void add(int m) {
synchronized (obj) {
if (m < 0) {
throw new RuntimeException();
}
this.value += m;
} // 无论有无异常,都会在此释放锁
}
JVM 规范定义了几种原子操作, 它们是不需要 synchronized 的操作:
- 基本类型(
long和double除外)赋值,例如:int n = m;long和double是 64 位数据,JVM 没有明确规定 64 位赋值操作是不是一个原子操作;
- 引用类型赋值,例如:
List<String> list = anotherList;
🌰 例如, 下面的代码就不需要 synchronized:
public void set(int m) {
synchronized(lock) {
this.value = m;
}
}
// 可以写成
public void set(String s) {
this.value = s;
}
让线程自己选择锁对象往往会使得代码逻辑混乱,也不利于封装。更好的方法是把 synchronized 逻辑封装起来。
🌰 例如,我们编写一个计数器如下:
public class Counter {
private int count = 0;
public void add(int n) {
synchronized(this) {
count += n;
}
}
public void dec(int n) {
synchronized(this) {
count -= n;
}
}
public int get() {
return count;
}
}
- 线程调用
add()、dec()方法时,它不必关心同步逻辑,因为synchronized代码块在add()、dec()方法内部; 并且,我们注意到,synchronized锁住的对象是this,即当前实例,这又使得创建多个 Counter 实例的时候,它们之间互不影响,可以并发执行;
var c1 = Counter();
var c2 = Counter();
// 对c1进行操作的线程:
new Thread(() -> {
c1.add();
}).start();
new Thread(() -> {
c1.dec();
}).start();
// 对c2进行操作的线程:
new Thread(() -> {
c2.add();
}).start();
new Thread(() -> {
c2.dec();
}).start();
✏️ 线程安全: 如果一个类被设计为允许多线程正确访问,我们就说这个类就是线程安全的(thread-safe)
有一些类, 它们的所有成员变量都是 final,多线程同时访问时只能读不能写,这些不变类也是线程安全的.
还有一些类, 它们只提供 static 静态方法,没有成员变量的类,也是线程安全的;
非线程安全的类实例, 如果在各个线程中只读取, 而不写入, 那么这个实例也是可以安全地在线程间共享的;
# 同步方法
我们再观察 Counter 的代码:
public class Counter {
...
public void add(int n) {
synchronized(this) {
count += n;
}
}
...
}
add 方法中锁住的是调用 add 方法的 Counter 实例.
这时, 实际上可以用 synchronized 修饰这个方法. 用 synchronized 修饰的方法就是同步方法,它表示整个方法都必须用 this 实例加锁:
public synchronized void add(int n) {
count += n;
}
对于 static 方法,是没有 this 实例的,但任何一个类都有一个由 JVM 自动创建的 Class 实例. 所以对 static 方法添加 synchronized,锁住的是该类的 Class 实例:
public synchronized static void test(int n) {
...
}
等价于:
public class Counter {
public static void test(int n) {
synchronized(Counter.class) {
...
}
}
}
# 可重入锁 & 死锁
✏️ 可重入锁: JVM 允许同一个线程重复获取同一个锁,这种能被同一个线程反复获取的锁,就叫做『 可重入锁 』
- 上面 👆 用
synchronized声明的线程锁就是可重入锁;
🌰 下面的代码中, 在一个同步方法中, 调用了另一个同步方法;
- 当在一个线程中调用 Counter 实例的
add方法, 其内部的dec方法也可以执行. 因为是在同一个线程中;
public class Counter {
private int count = 0;
public synchronized void add(int n) {
if (n < 0) {
dec(-n); // 调用另一个同步方法
} else {
count += n;
}
}
public synchronized void dec(int n) {
count += n;
}
}
✏️ 死锁: 当两个线程各自持有不同的锁,然后各自试图获取对方手里的锁, 造成了双方无限等待下去,这就是『 死锁 』:
- 死锁发生后,没有任何机制能解除死锁,只能强制结束 JVM 进程;
- 在编写多线程应用时,要特别注意防止死锁。因为死锁一旦形成,就只能强制结束进程;
public void add(int m) {
synchronized(lockA) { // 获得lockA的锁
this.value += m;
synchronized(lockB) { // 获得lockB的锁
this.another += m;
} // 释放lockB的锁
} // 释放lockA的锁
}
public void dec(int m) {
synchronized(lockB) { // 获得lockB的锁
this.another -= m;
synchronized(lockA) { // 获得lockA的锁
this.value -= m;
} // 释放lockA的锁
} // 释放lockB的锁
}
- 对于上述代码,线程 1 和线程 2 如果分别执行
add()和dec()方法时:- 线程 1:进入
add(),获得lockA; - 线程 2:进入
dec(),获得lockB;
- 线程 1:进入
- 之后:
- 线程 1:准备获得
lockB,失败,等待中; - 线程 2:准备获得
lockA,失败,等待中;
- 线程 1:准备获得
- 这就造成了死锁;
想要避免死锁, 线程获取锁的顺序要一致. 上面 👆 的例子可以改写成:
public void add(int m) {
synchronized(lockA) { // 获得lockA的锁
this.value += m;
synchronized(lockB) { // 获得lockB的锁
this.another += m;
} // 释放lockB的锁
} // 释放lockA的锁
}
public void dec(int m) {
synchronized(lockA) { // 获得lockA的锁
this.value -= m;
synchronized(lockB) { // 获得lockB的锁
this.another -= m;
} // 释放lockB的锁
} // 释放lockA的锁
}
# wait & notify
在上面 👆, 我们用 synchronized 解决了多线程竞争的问题, 也就是多个线程同时访问一个实例对象, 谁先谁后的问题.
但是 synchronized 并没有解决 多线程协调 的问题。
🌰 例如, 下面是一个任务队列, 里面用 addTask 方法添加任务, getTask 方法获取任务:
class TaskQueue {
Queue<String> queue = new LinkedList<>();
public synchronized void addTask(String s) {
this.queue.add(s);
}
public synchronized String getTask() {
while (queue.isEmpty()) {
// 任务队列为空, 等待任务
}
return queue.remove();
}
}
- 上面 👆 代码设想的功能是:
getTask()内部先判断队列是否为空,如果为空,就循环等待;- 直到另一个线程调用
addTask()往队列中放入了一个任务,while循环退出,返回列表中的添加的任务;
- 但实际上
while()循环永远不会退出。因为线程在执行while()循环时,已经在getTask()入口获取了this锁; - 其他线程根本无法调用
addTask(),因为addTask()执行条件也是获取this锁。
想要实现的 多线程协调运行 的原则就是:
- 当条件不满足时,线程进入等待状态;
- 当条件满足时,线程被唤醒,继续执行任务;
public synchronized String getTask() {
while (queue.isEmpty()) {
// 释放this锁:
this.wait();
// 重新获取this锁
}
return queue.remove();
}
wait()方法必须在当前获取的锁对象上调用;- 上面 👆 代码中获取的是
this锁,因此调用this.wait();
- 上面 👆 代码中获取的是
- 调用
wait()方法后,线程进入等待状态,wait()方法不会返回,直到将来某个时刻,线程从等待状态被其他线程唤醒后,wait()方法才会返回,然后继续执行下一条语句; wait()方法调用时,会释放synchronized块获得的锁,wait()方法返回后,线程又会重新试图获得锁;
在调用 wait() 方法的锁对象上调用 notify() 方法让等待的线程被重新唤醒;
public synchronized void addTask(String s) {
this.queue.add(s);
this.notify(); // 唤醒在this锁等待的线程
}
- 在往队列中添加了任务后,线程立刻对
this锁对象调用notify()方法,这个方法会唤醒一个正在this锁等待的线程;
可能有多个线程都在等待, 这时 notify() 只会唤醒其中一个, 具体哪个依赖操作系统,有一定的随机性;
使用 notifyAll() 将唤醒所有当前正在等待的线程;
public synchronized void addTask(String s) {
this.queue.add(s);
this.notifyAll();
}
# 使用 ReentrantLock
从 Java 5 开始,引入了一个高级的处理并发的 java.util.concurrent 包,它提供了大量更高级的并发功能,能大大简化多线程程序的编写.
java.util.concurrent.locks 包提供的 ReentrantLock 用于替代 synchronized 加锁
🌰 先看一个 synchronized 版本:
public class Counter {
private int count;
public void add(int n) {
synchronized(this) {
count += n;
}
}
}
可以使用 ReentrantLock 替换成:
public class Counter {
private final Lock lock = new ReentrantLock();
private int count;
public void add(int n) {
lock.lock();
try {
count += n;
} finally {
lock.unlock();
}
}
}
- 因为
synchronized是 Java 语言层面提供的语法,所以我们不需要考虑异常; - 而
ReentrantLock是 Java 代码实现的锁,我们就必须先获取锁,然后在finally中正确释放锁; - 和
synchronized一样,ReentrantLock是可重入锁, 一个线程可以多次获取同一个锁;
和 synchronized 不同的是,ReentrantLock 可以尝试获取锁:
if (lock.tryLock(1, TimeUnit.SECONDS)) {
try {
...
} finally {
lock.unlock();
}
}
- 上述代码在尝试获取锁的时候,最多等待 1 秒。如果 1 秒后仍未获取到锁,
tryLock()返回false - 使用
ReentrantLock比直接使用synchronized更安全,线程在tryLock()失败的时候不会导致死锁;
synchronized 可以配合 wait 和 notify 实现线程在条件不满足时等待,条件满足时唤醒.
ReentrantLock 中使用 Condition 对象来实现 wait 和 notify 的功能。
class TaskQueue {
private final Lock lock = new ReentrantLock();
private final Condition condition = lock.newCondition();
private Queue<String> queue = new LinkedList<>();
public void addTask(String s) {
lock.lock();
try {
queue.add(s);
condition.signalAll();
} finally {
lock.unlock();
}
}
public String getTask() {
lock.lock();
try {
while (queue.isEmpty()) {
condition.await();
}
return queue.remove();
} finally {
lock.unlock();
}
}
}
- Condition 对象实例从
Lock实例的newCondition()返回,这样才能获得一个绑定了Lock实例的Condition实例; - Condition 提供的
await()、signal()、signalAll()原理和synchronized锁对象的wait()、notify()、notifyAll()是一致的,并且其行为也是一样的; - 和
tryLock()类似,await()可以在等待指定时间后,如果还没有被其他线程唤醒,可以自己醒来;- 🌰
condition.await(1, TimeUnit.SECOND)
- 🌰
# 使用 Concurrent 集合
👆 前面已经通过 ReentrantLock 和 Condition 实现了一个线程安全的任务队列 TaskQueue.
在实际开发中, 我们并不需要自己去实现. Java 标准库的 java.util.concurrent 包提供的线程安全的集合ArrayBlockingQueue。
除此之外, 针对 List、Map、Set、Deque 等,java.util.concurrent 包也提供了对应的并发集合类:
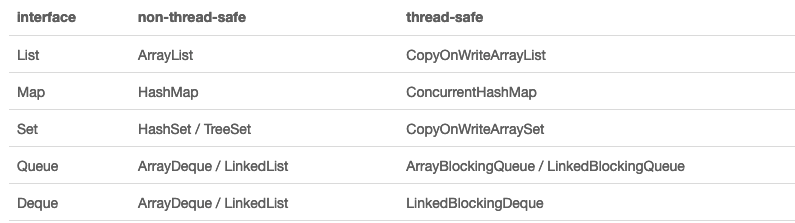
所有的同步和加锁的逻辑都在集合内部实现, 所以这些并发集合与使用非线程安全的集合类完全相同.
Map<String, String> map = new ConcurrentHashMap<>();
// 在不同的线程读写:
map.put("A", "1");
map.put("B", "2");
map.get("A", "1");
# 线程池
创建线程需要花费操作系统资源(线程资源,栈空间等),频繁 创建和销毁大量线程需要消耗大量时间。
可以设想, 我们创建一组线程, 当有任务需要线程时, 就分配给它一个, 等他用完再还回来, 而不是销毁. 这样要比每次有任务就创建一个新线程, 然后用完就销毁, 要高效的多.
这种能接收大量小任务并进行分发处理的就是『 线程池 』
- 线程池内部维护了若干个线程,没有任务的时候,这些线程都处于等待状态;
- 如果有新任务,就分配一个空闲线程执行;
- 如果所有线程都处于忙碌状态,新任务要么放入队列等待,要么增加一个新线程进行处理;
Java 标准库提供了 ExecutorService 接口表示线程池. Java 标准库提供的几个常用实现类有:
- FixedThreadPool:线程数固定的线程池;
- CachedThreadPool:线程数根据任务动态调整的线程池;
- SingleThreadExecutor:仅单线程执行的线程池。
创建这些线程池的方法都被封装到 Executors 这个类中.
🌰 例子, 下面创建了一个有 4 个线程的 FixedThreadPool 线程池:
import java.util.concurrent.*;
public class Main {
public static void main(String[] args) {
// 创建一个固定大小的线程池:
ExecutorService es = Executors.newFixedThreadPool(4);
for (int i = 0; i < 6; i++) {
es.submit(new Task("" + i));
}
// 关闭线程池:
es.shutdown();
}
}
class Task implements Runnable {
private final String name;
public Task(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("start task " + name);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
System.out.println("end task " + name);
}
}
/*
结果:
start task 1
start task 3
start task 0
start task 2
end task 1
end task 3
end task 2
end task 0
start task 4
start task 5
end task 4
end task 5
*/
- 一次性放入 6 个任务,由于线程池只有固定的 4 个线程,因此,前 4 个任务会同时执行,等到有线程空闲后,才会执行后面的两个任务;
- 线程池在程序结束的时候要关闭:
shutdown()方法关闭线程池的时候,它会等待正在执行的任务先完成,然后再关闭;shutdownNow()会立刻停止正在执行的任务;awaitTermination()则会等待指定的时间让线程池关闭;
# 使用 Future
在执行多个任务的时候,使用 Java 标准库提供的线程池是非常方便的。我们提交的任务只需要实现 Runnable 接口,就可以让线程池去执行.
但 Runnable 接口有个问题,它的方法没有返回值。如果任务需要一个返回结果,那么只能保存到变量,还要提供额外的方法读取,非常不便。
所以,Java 标准库还提供了一个 Callable 接口,和 Runnable 接口比,它多了一个返回值.
并且 Callable 接口是一个泛型接口,可以返回指定类型的结果。
class Task implements Callable<String> {
public String call() throws Exception {
return longTimeCalculation();
}
}
现在的问题是,如何获得异步执行的结果?
ExecutorService.submit() 返回了一个 Future 类型对象,它代表一个未来能获取结果的对象.
ExecutorService executor = Executors.newFixedThreadPool(4);
// 定义任务:
Callable<String> task = new Task();
// 提交任务并获得Future:
Future<String> future = executor.submit(task);
// 从Future获取异步执行返回的结果:
String result = future.get(); // 可能阻塞
在某个时刻调用 Future 对象的 get() 方法,就可以获得异步执行的结果:
- 在调用
get()时,如果异步任务已经完成,我们就直接获得结果; - 如果异步任务还没有完成,那么
get()会阻塞,直到任务完成后才返回结果;
一个实现了 Future<V> 接口的类表示一个未来可能会返回的结果,它定义的方法有:
get():获取结果(可能会等待)get(long timeout, TimeUnit unit):获取结果,但只等待指定的时间;cancel(boolean mayInterruptIfRunning):取消当前任务;isDone():判断任务是否已完成;
# 使用 CompletableFuture
前面说, 使用 Future 类型实例的 get 方法获取异步结果, 可能会造成阻塞.
从 Java 8 开始引入了 CompletableFuture,它针对 Future 做了改进,可以传入回调对象,当异步任务完成或者发生异常时,自动调用回调方法.
public class Main {
public static void main(String[] args) throws Exception {
// 创建异步执行任务:
CompletableFuture<Double> cf = CompletableFuture.supplyAsync(() -> {
return fetchPrice();
});
// 如果执行成功:
cf.thenAccept((result) -> {
System.out.println("price: " + result);
});
// 如果执行异常:
cf.exceptionally((e) -> {
e.printStackTrace();
return null;
});
// 主线程不要立刻结束,否则 CompletableFuture 默认使用的线程池会立刻关闭:
Thread.sleep(200);
}
static Double fetchPrice() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
if (Math.random() < 0.3) {
throw new RuntimeException("fetch price failed!");
}
return 5 + Math.random() * 20;
}
}
CompletableFuture 更强大的功能是,多个 CompletableFuture 可以串行执行.
🌰 例如,定义两个 CompletableFuture:
- 第一个 CompletableFuture 根据证券名称查询证券代码;
- 第二个 CompletableFuture 根据证券代码查询证券价格;
public class Main {
public static void main(String[] args) throws Exception {
// 第一个任务:
CompletableFuture<String> cfQuery = CompletableFuture.supplyAsync(() -> {
return queryCode("中国石油");
});
// cfQuery成功后继续执行下一个任务:
CompletableFuture<Double> cfFetch = cfQuery.thenApplyAsync((code) -> {
return fetchPrice(code);
});
// cfFetch成功后打印结果:
cfFetch.thenAccept((result) -> {
System.out.println("price: " + result);
});
// 主线程不要立刻结束,否则CompletableFuture默认使用的线程池会立刻关闭:
Thread.sleep(2000);
}
static String queryCode(String name) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
return "601857";
}
static Double fetchPrice(String code) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
return 5 + Math.random() * 20;
}
}
除了串行执行外,多个 CompletableFuture 还可以并行执行。
🌰 例如,同时从新浪和网易查询证券代码,只要任意一个返回结果,就进行下一步查询价格,查询价格也同时从新浪和网易查询,只要任意一个返回结果:
public static void main(String[] args) throws Exception {
// 两个CompletableFuture执行异步查询:
CompletableFuture<String> cfQueryFromSina = CompletableFuture.supplyAsync(() -> {
return queryCode("中国石油", "https://finance.sina.com.cn/code/");
});
CompletableFuture<String> cfQueryFrom163 = CompletableFuture.supplyAsync(() -> {
return queryCode("中国石油", "https://money.163.com/code/");
});
// 用anyOf合并为一个新的CompletableFuture:
CompletableFuture<Object> cfQuery = CompletableFuture.anyOf(cfQueryFromSina, cfQueryFrom163);
// 两个CompletableFuture执行异步查询:
CompletableFuture<Double> cfFetchFromSina = cfQuery.thenApplyAsync((code) -> {
return fetchPrice((String) code, "https://finance.sina.com.cn/price/");
});
CompletableFuture<Double> cfFetchFrom163 = cfQuery.thenApplyAsync((code) -> {
return fetchPrice((String) code, "https://money.163.com/price/");
});
// 用anyOf合并为一个新的CompletableFuture:
CompletableFuture<Object> cfFetch = CompletableFuture.anyOf(cfFetchFromSina, cfFetchFrom163);
// 最终结果:
cfFetch.thenAccept((result) -> {
System.out.println("price: " + result);
});
// 主线程不要立刻结束,否则CompletableFuture默认使用的线程池会立刻关闭:
Thread.sleep(200);
}
static String queryCode(String name, String url) {
System.out.println("query code from " + url + "...");
try {
Thread.sleep((long) (Math.random() * 100));
} catch (InterruptedException e) {
}
return "601857";
}
static Double fetchPrice(String code, String url) {
System.out.println("query price from " + url + "...");
try {
Thread.sleep((long) (Math.random() * 100));
} catch (InterruptedException e) {
}
return 5 + Math.random() * 20;
}
}
anyOf()可以实现“任意个 CompletableFuture 只要一个成功”;allOf()可以实现“所有 CompletableFuture 都必须成功”
# 使用 ThreadLocal
Java 中的 ThreadLocal 类允许我们创建只能被同一个线程读写的 线程局部变量。
因此,如果一段代码含有一个 ThreadLocal 变量的引用,即使两个线程同时执行这段代码,它们也无法访问到对方的 ThreadLocal 变量。
private ThreadLocal myThreadLocal = new ThreadLocal();
只需要实例化 ThreadLocal 对象一次,并且也不需要知道它是被哪个线程实例化。虽然所有的线程都能访问到这个 ThreadLocal 实例,但是每个线程却只能访问到自己通过调用 ThreadLocal 的 set() 方法设置的值。
通过 get() 方法可以获取存入的值.
String threadLocalValue = (String) myThreadLocal.get();
可以创建一个指定泛型类型的 ThreadLocal 对象,这样我们就不需要每次对使用 get() 方法返回的值作强制类型转换了。
private ThreadLocal<String> myThreadLocal = new ThreadLocal<>();
我们可以通过创建一个 ThreadLocal 的子类并且重写 initialValue() 方法,来为一个 ThreadLocal 对象指定一个初始值。
private ThreadLocal<String> myThreadLocal = new ThreadLocal<>() {
@Override
protected String initialValue() {
return "This is the initial value";
}
};
🌰 下面是一个完整的例子:
public class ThreadLocalExample {
public static class MyRunnable implements Runnable {
private ThreadLocal threadLocal = new ThreadLocal();
@Override
public void run() {
threadLocal.set((int) (Math.random() * 100D));
try {
Thread.sleep(2000);
} catch (InterruptedException e) {}
System.out.println(threadLocal.get());
}
}
public static void main(String[] args) {
MyRunnable sharedRunnableInstance = new MyRunnable();
Thread thread1 = new Thread(sharedRunnableInstance);
Thread thread2 = new Thread(sharedRunnableInstance);
thread1.start();
thread2.start();
}
}