# JDBC
# JDBC 入门
# 什么是 JDBC
JDBC 介绍:
- 全称 Java 数据库连接 (Java Database Connectivity);
- 用于在 Java 语言编程中与数据库连接的 API;
- 由一组用 Java 语言编写的“类”和“接口”组成;
- JDBC 包含了数据库操作的规范。定义了相关的类,接口,方法, 但是并没有提供具体实现;
- 各大数据库厂商会提供对 JDBC 的实现;
- 简单说, JDBC 提供了操纵数据库的接口,但是没有具体实现。 通过引入不同的驱动包(
.jar文件),就可以连接到不同的数据库;
JDBC 的 API 通常用于:
- 连接到数据库
- 创建 SQL 或 MySQL 语句
- 在数据库中执行 SQL 或 MySQL 查询
- 查看和修改数据库中的数据记录

# 使用 JDBC 建立数据库连接
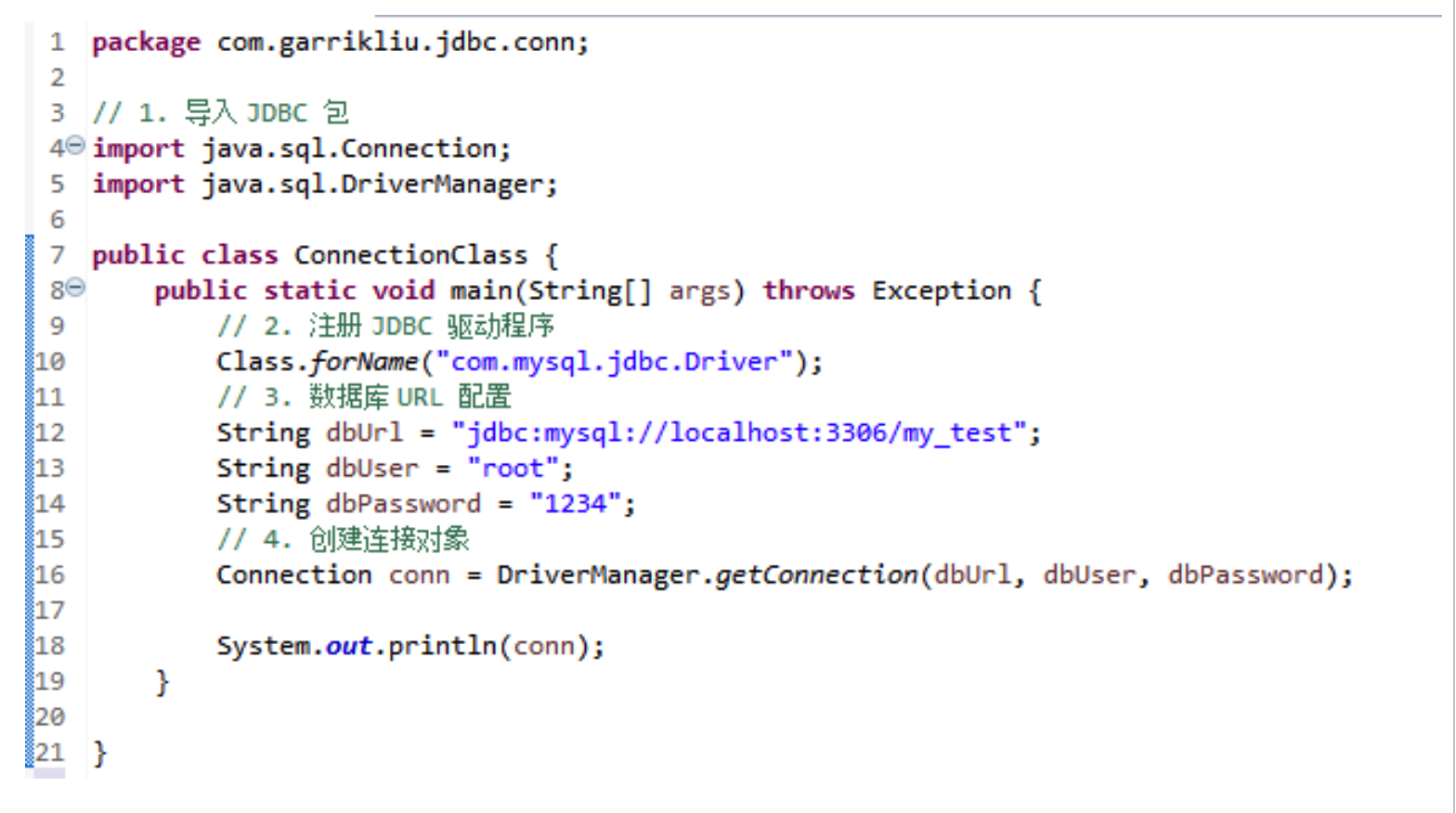
建立 JDBC 连接所涉及以下四个步骤:
- 导入 JDBC 包:使用
import语句在 Java 代码开头位置导入所需的类; - 注册 JDBC 驱动程序:使 JVM 将所需的驱动程序实现加载到内存中,从而可以满足 JDBC 请求。使用
Class.forName()方法,将驱动程序的类文件动态加载到内存中,并将其自动注册; - 数据库 URL 配置:创建一个正确格式化的地址,指向要连接到的数据库;MySQL URL 格式为:
jdbc:mysql://hostname/databaseName; - 创建连接对象:调用 DriverManager 对象的
getConnection()方法来建立实际的数据库连接。
# 使用 JDBC 操作数据库
# 创建数据表
- 连接上数据库;
- 创建你要执行的 SQL 语句;
- 执行 SQL;
- 通过
createStatement()创建要执行的静态 SQL 语句的 Statement 对象; - 通过 Statement 对象的
executeUpdate(sql)方法来执行语句; - 返回结果:
- DQL 操作返回查询结果集;
- DML 返回受影响的行数;
- DDL 返回 0;
- 释放数据资源;
- 通过 Statement 对象
close()释放资源; - 通过 Connction 对象
close()释放资源;
- 通过 Statement 对象
- 通过

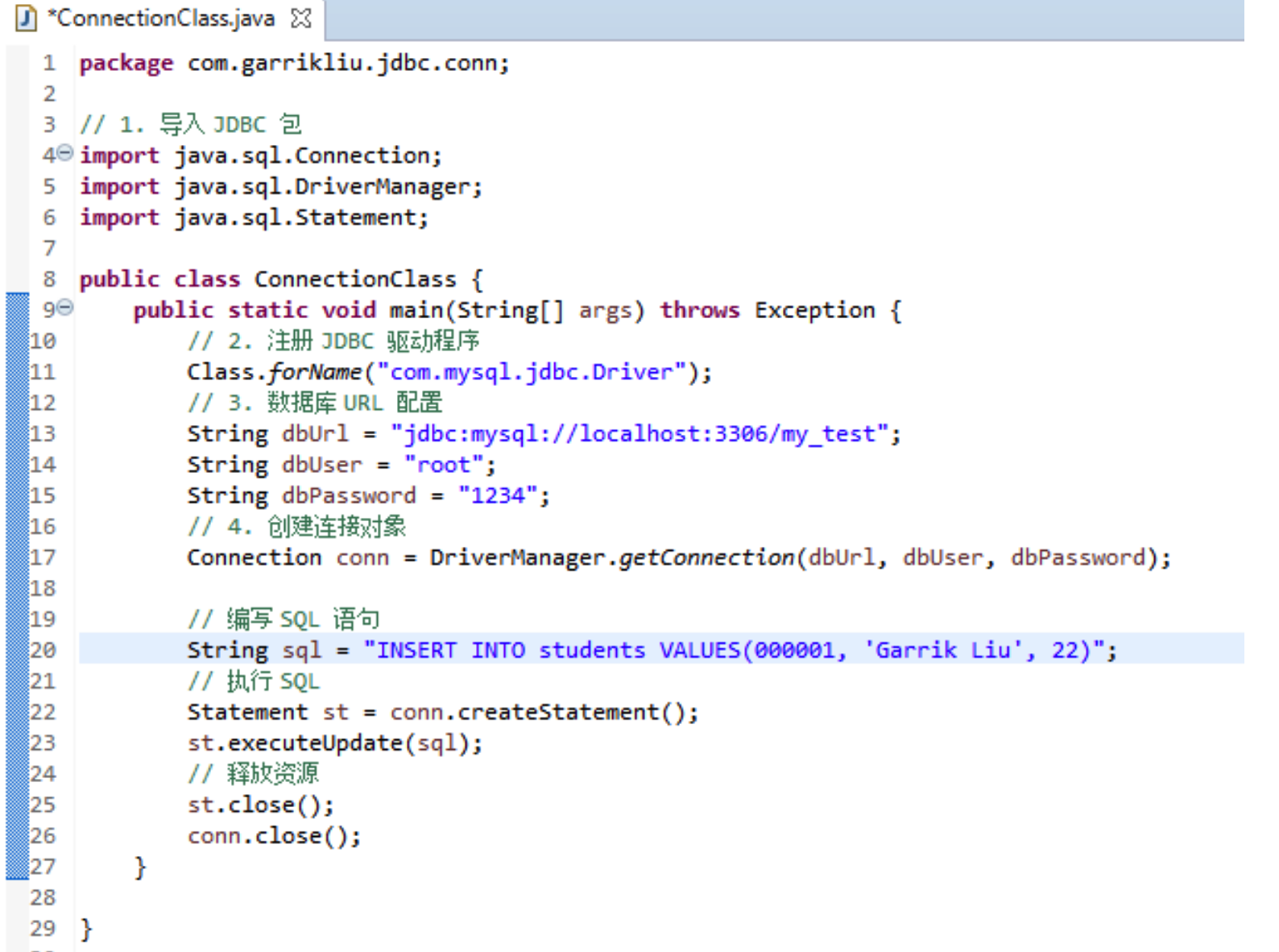
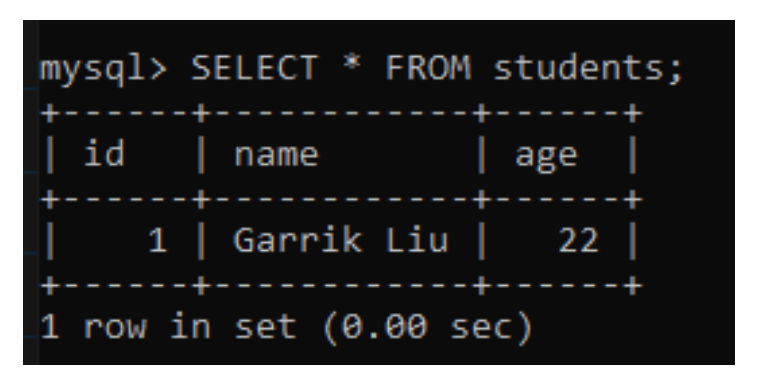
# 执行 DML 操作
- 执行 DML 操作的步骤和上面创建数据表相同;
- 我们拿“插入一条新数据”举例:
# 执行 DQL 操作
- 通过 Statement 对象的
executeQuery(sql)方法来执行语句; executeQuery方法返回一个查询结果集 ResultSet;- 结果集常用方法:
next():如果当前指向的行有下一行数据,则指针指向下一行;getXxx(String columnName):获取当前行中的,指定列的值。- "Xxx" 指的是目标列的数据类型;
- 如果类型是 Varchar / Char / Text,则方法名为
getString; - 如果类型是 Int / Integer,则方法名为
getInt;

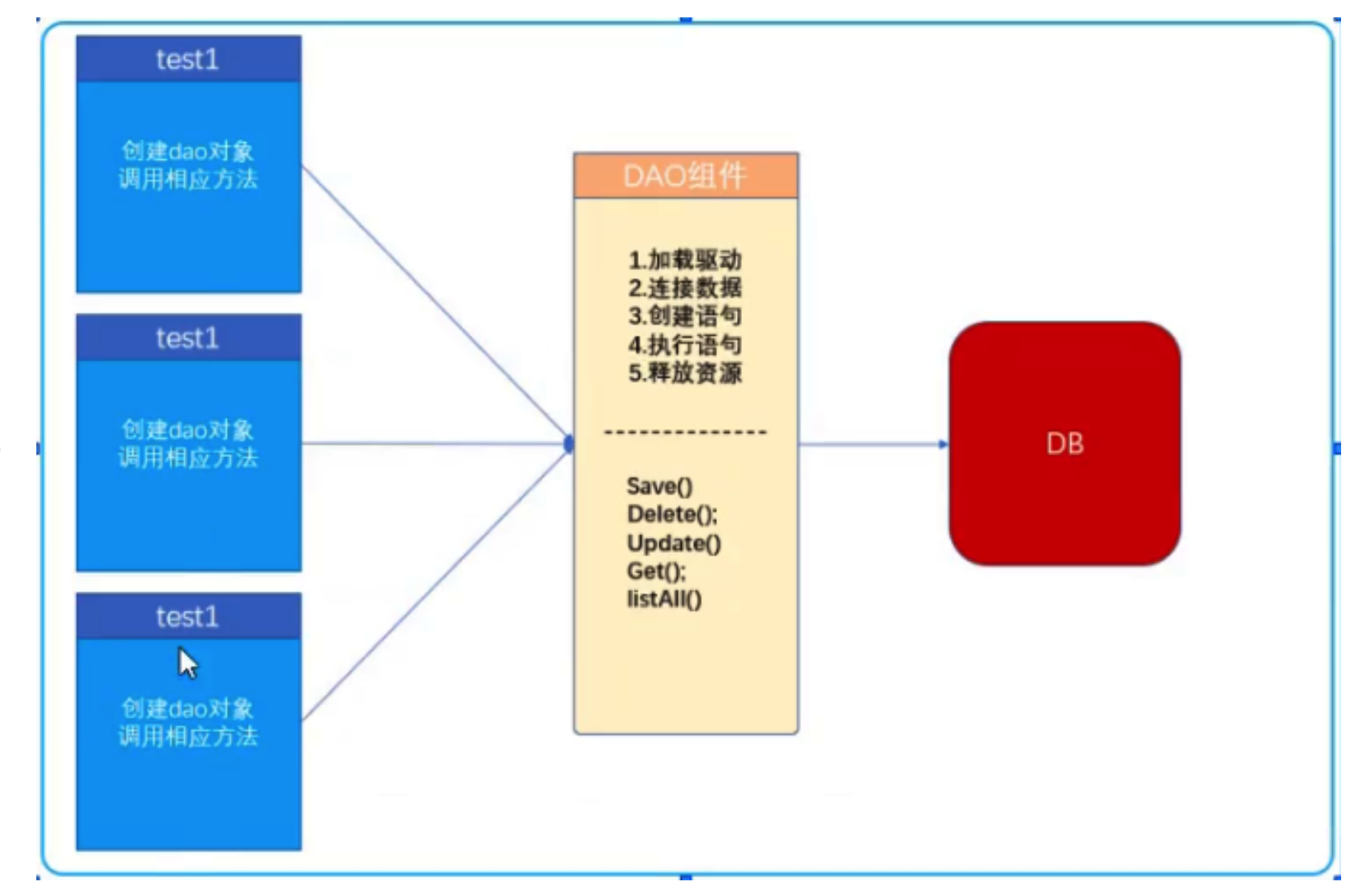
# DAO 思想
# DAO 什么是
- 当用上面的方法去重复地进行“增删改查”操作,重复代码会很多;所以我们需要将这些操作封装起来;
- DAO(Data Access Object)数据存取对象;
- DAO 位于“业务逻辑层”和“持久层”(数据库) 之间,从而实现对持久层数据访问;
# ORM 介绍
- ORM(Object Relational Mapping)对象关系映射;
- 将关系型数据库的数据映射为对象,以对象的形式展现;
- ORM 的目的是为了方便开发人员以面向对象的思想来实现对数据库的操作;

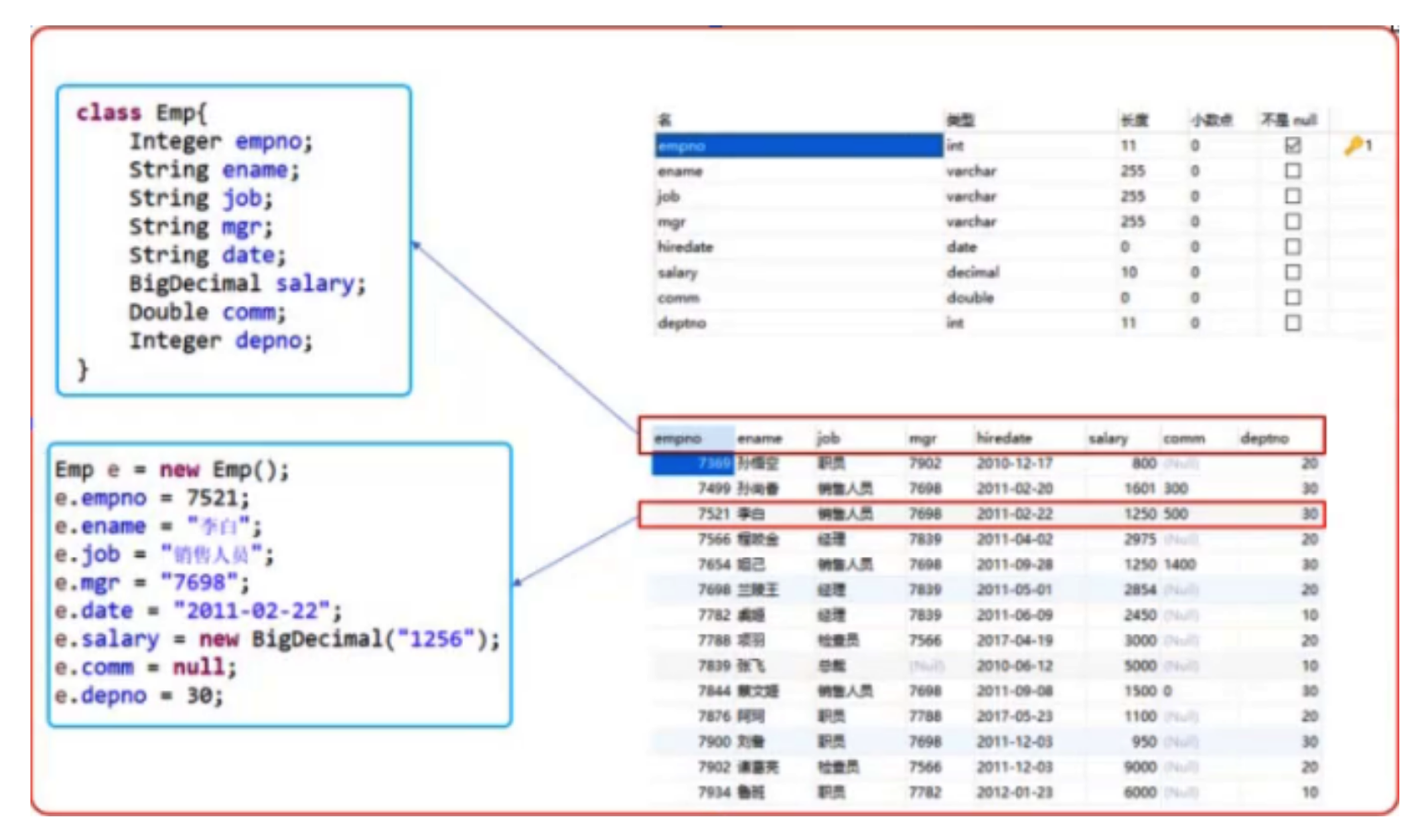
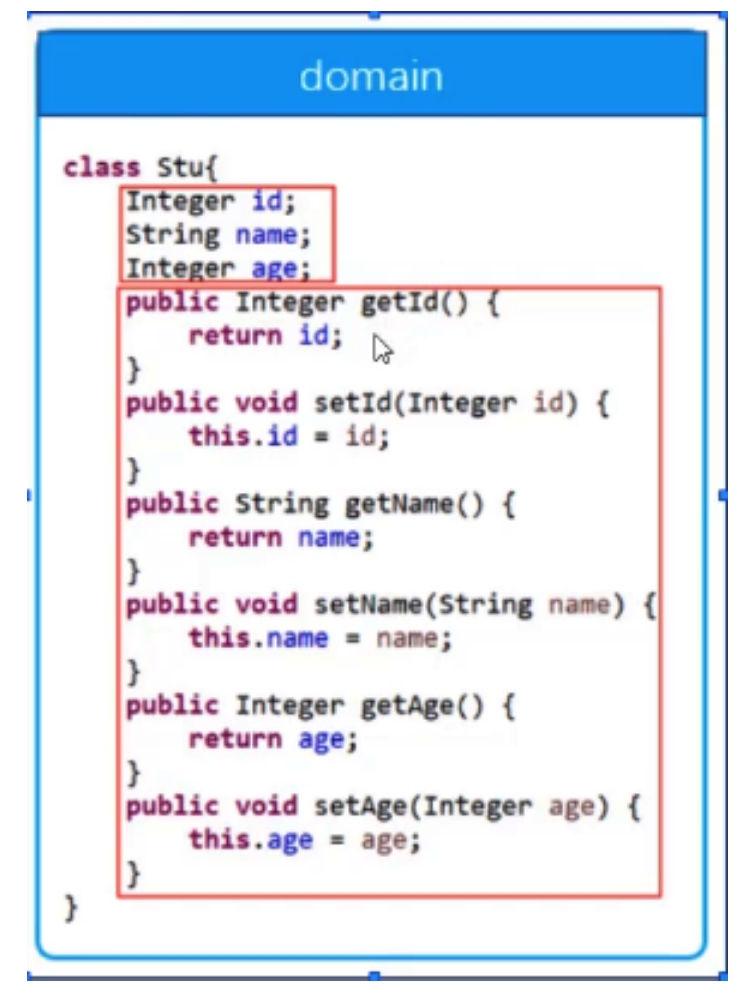
# Domain 介绍
- Domain 就是一个类;
- 符合 JavaBean 规范(一个类中有字段和该字段的 Getter 和 Setter 方法);
- 用于作为用户和数据库交互的中转站;
- 示例:下面就是一个 Domain 类:
- 保存数据:
- 通过创建
StuDomain 对象来进行数据中转; - 将
Stu传入 DAO 对象的save方法来保存到数据库; - 如果不用 Domain 的话,我们要向
save方法传入三个参数,现在一个参数就够了; 
- 通过创建
- 读取数据:

# DAO 编写
# DAO 设计规范
# 编写 DAO 组件
- 定义 DAO 接口;
- 开发中使用“面向接口”编程;
- 接口只给出函数声明,但是没有给出函数的具体实现;
- 编写 DAO 实现类;
- 根据需求来编写具体的实现类;
# 面向接口的好处
- 业务逻辑清晰;
- 增强代码的扩展性,可维护性;
- 接口和实现相分离,适合团队开发;
- 降低耦合度,便于日后迭代;
# Package 包名规范
- 整体规范:
- 域名.模块名称.组件名称
- DAO 包规范:
com.xxx.jdbc.domain存储所有的 Domaincom.xxx.jdbc.dao存储所有的 DAO 接口com.xxx.jdbc.dao.impl存储所有的 DAO 接口实现类com.xxx.jdbc.dao.test存储 DAO 组件的测试类
# Class 类名规范
- domain 类:
- 存储在 domain 包中。用于描述一个对象,是一个 JavaBean,用于表示某一个对象的 CRUB 声明;
- 命名规范:接口 + DomainDao
- dao 实现类:
- 储存在 dao.impl 包中,用于表示 DAO 接口的实现类。
- 命名规范:DomainDao + 实现类
# DAO 开发步骤
- 创建表
- 建立 domain 包 & domain 类
- 建立 dao 包 & dao 接口
- 建立 dao.impl 包 & dao 实现类
- 根据 dao 接口创建 dao 测试类
- 编写实现类当中 dao 的声明的方法体
- 每编写一个 dao 方法,进行功能测试
# DAO 编写 - 1: 结构搭建
先创建好 domain 包,domain 类;dao 包,dao 接口;dao.impl 包,dao 实现类;测试包,测试类;
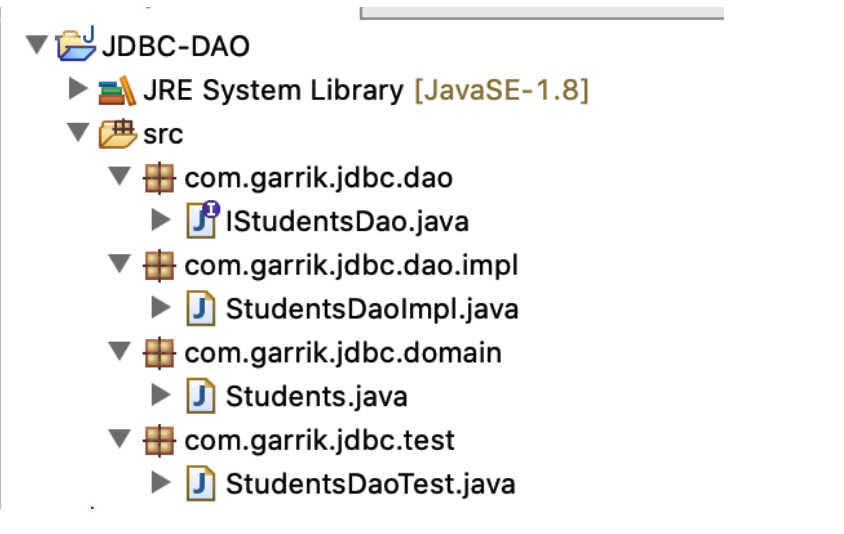
# domain 类:

# dao 接口:

# dao 实现类:

# 测试类:
# DAO 编写 - 2:编写 DAO 实现类
# save 方法编写

编写 save 方法单元测试:
在 StudentDaoTest 类中编写它的单元测试方法;
使用 @Test 修饰符创建单元测试;
之后选中方法,右键 -> Run As -> JUnit Test;

测试成功后显式如下:

# delete 方法编写
只要把 SQL 语句改变就好了

# update 方法编写

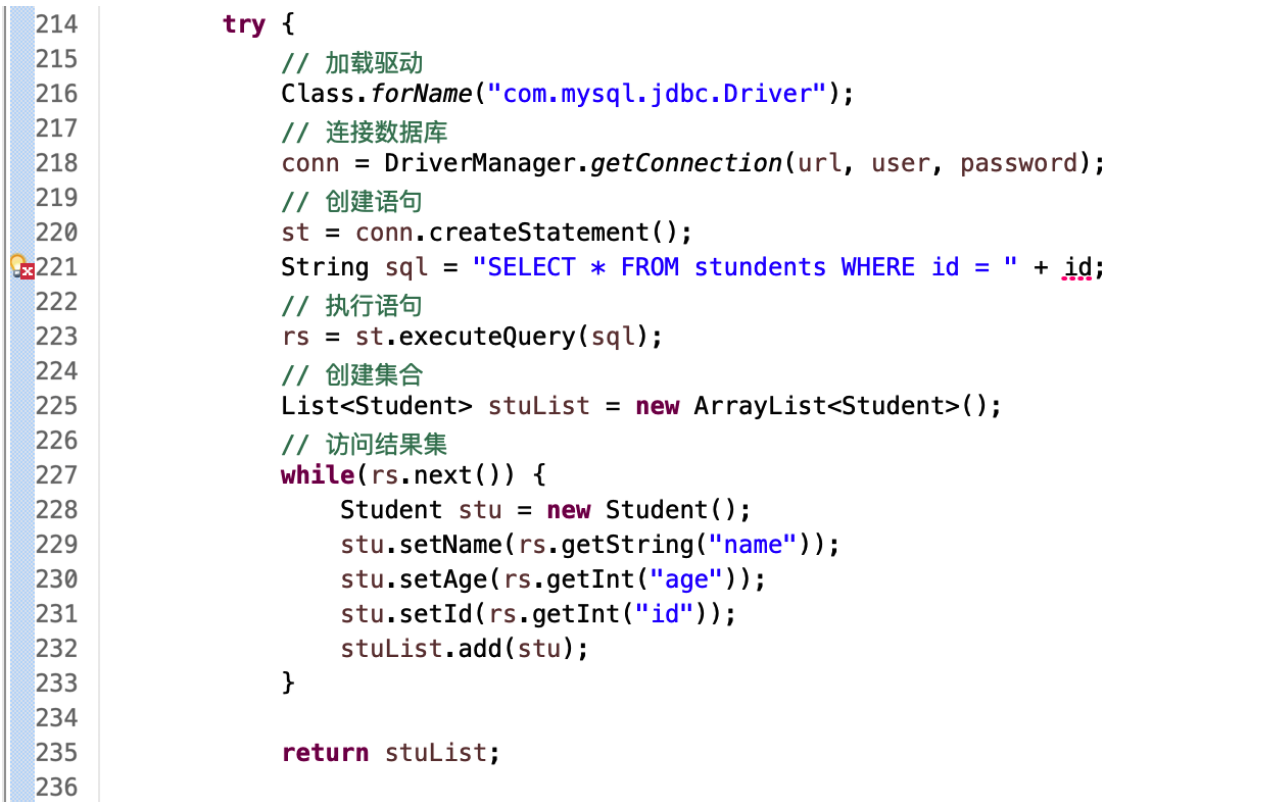
# get 方法编写
- 把
executeUpdate改成executeQuery; - 并将返回结果赋给一个 ResultSet 对象;

# getAll 方法编写
创建一个数组来存放查询到的多个结果;
# DAO 编写 - 3:代码重构
# 抽出配置变量
将数据库 URL,用户名,密码,驱动地址抽出;
声明为“私有成员变量”;

在方法中通过
this去获取成员变量:
# 将配置变量抽出到工具类
- 由于上面的这些配置变量可能在别的 DAO 实现类中也会被使用;
- 所以可以再抽出来放到一个“工具类”中:
- 再创建一个 util 包,并创建 JDBCUtil 类:

- 把配置变量设置为
public static; - 这样可以直接通过“工具类名”来访问变量;

- 再创建一个 util 包,并创建 JDBCUtil 类:
- 在 DAO 实现类中,可以直接通过 JDBCUtil 类来获取配置变量了:

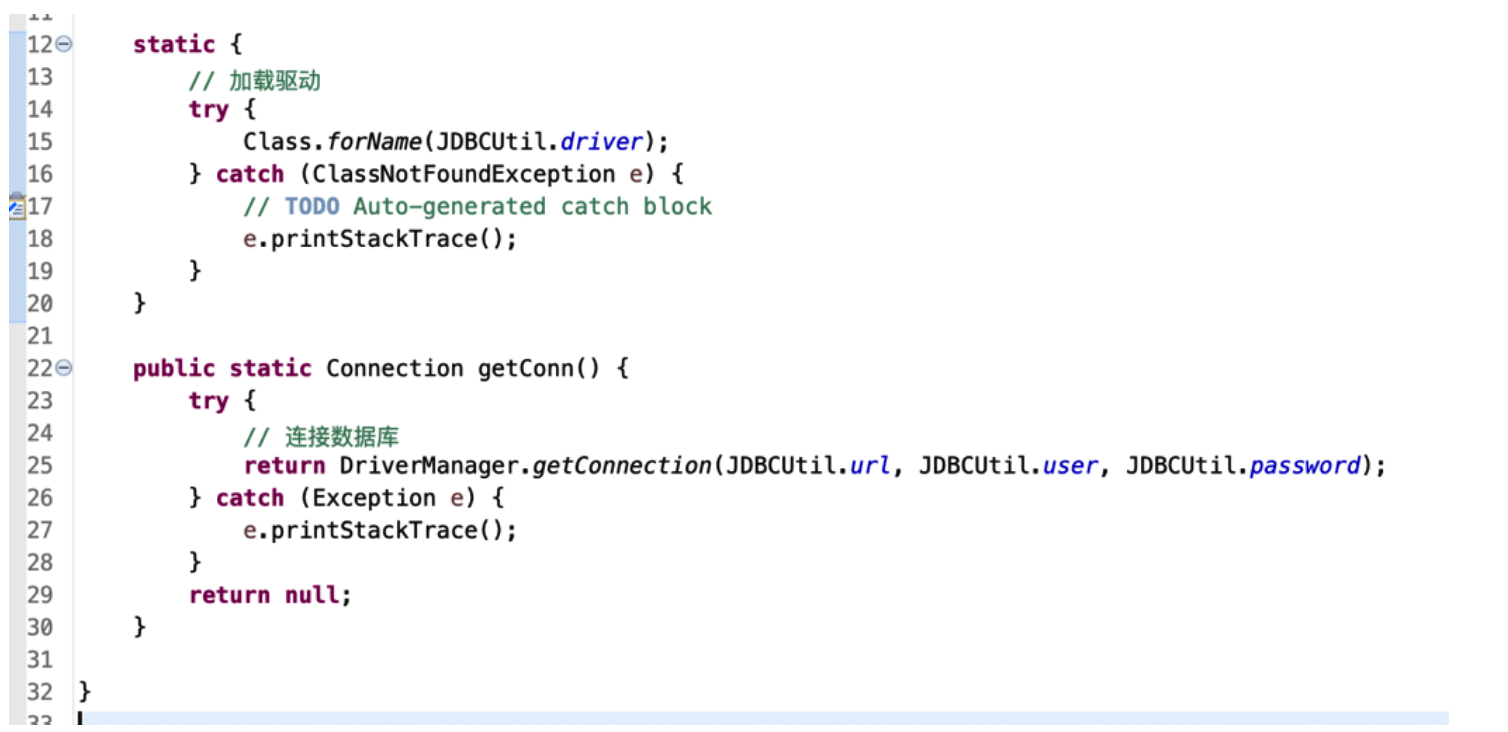
# 把 Connection 对象创建抽出到“JDBCUtil 工具类”
把创建 Connection 对象的过程,封装到 JDBCUtil 里:

在实现类中的方法里,可以直接通过 JDBCUtil 来获取连接:

由于驱动加载只需要加载一次;
可以把驱动加载放到静态代码块中;
# 把释放资源操作抽出到 JDBCUtil

# 预编译
# Statement 接口
- Statement 接口用于 Java 程序与数据库之间的数据传输;
- Statement 接口有三个实现类:
- Statement:用于对数据库进行通用访问,使用的是静态 SQL;
- PreparedStatement:用于预编译模板 SQL 语句,在运行时接受 SQL 输入参数;
- CallableStatement:先不讲;
# 预编译语句
- PreparedStatement 对象用于预编译模板 SQL 语句;
- 使用 ?作为参数标记;
- 使用 Connection 对象的
prepareStatement(sql)方法将模板语句进行预编译; - 使用
setInt(index, value)或setString(index, value)方法将值绑定到参数中;- 每个参数标记的下标是其顺序位置;
- index 从 1 开始算起;
- 同样也是用
executeQuery()或executeUpdate()方法来执行语句;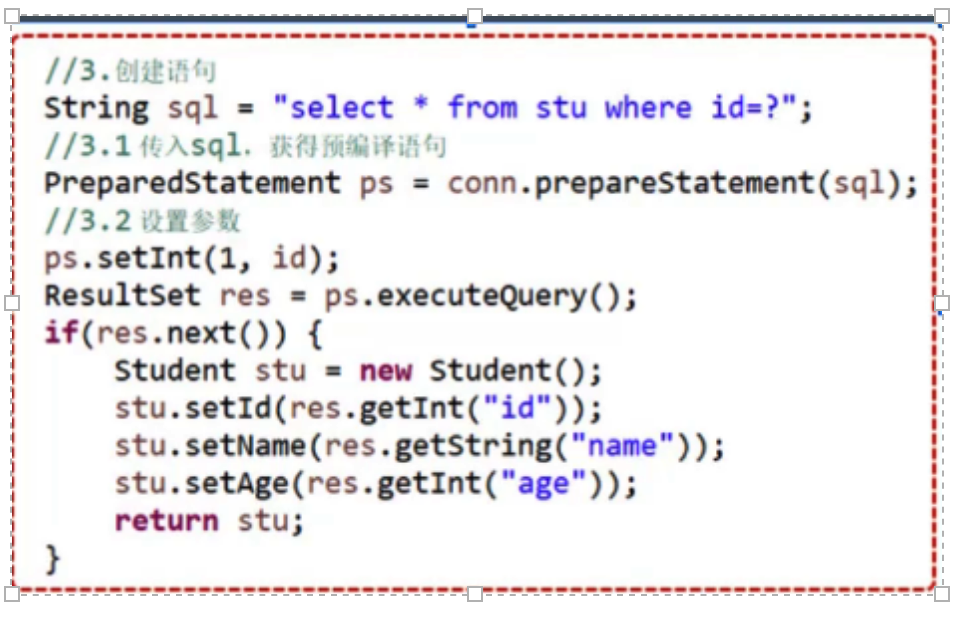
# 防止 SQL 注入
- 通过把 SQL 命令插入到 Web 表单中提交,或 URL 查询字段等方法,来达到欺骗服务器执行 SQL 命令的目的,就叫做“SQL 注入”
- 🌰 例如:
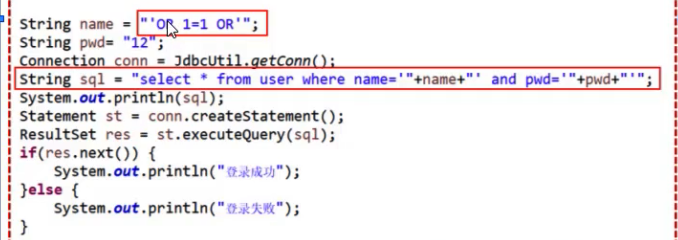
- 上面程序执行完,sql 变量等于
select * from user where name = '' OR 1=1 OR '' and pwd='12'
- 🌰 例如:
- PrepareStatement 能够防止注入;
- 它会在特殊符号前加
\进行转义;
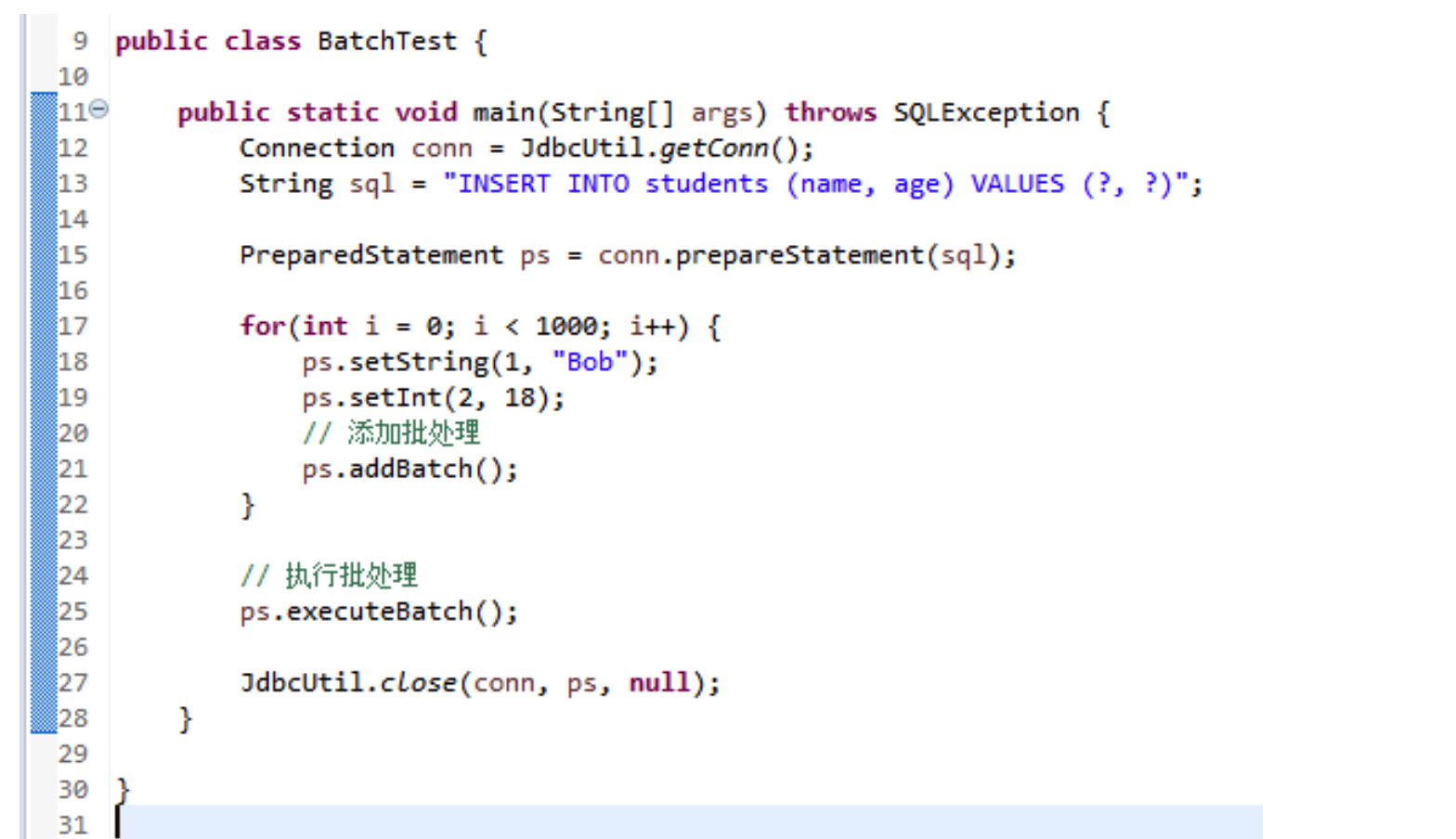
# 批处理
- 批处理是什么?
- 一次性执行多条 SQL 语句,允许多条语句一次性提交给数据库批量处理;
- 批处理方法:
addBatch(String):添加需要批处理的 SQL 语句;executeBatch():执行批处理;
- 支持情况:
- 默认 MySQL 是不支持批处理的;
- 需要在数据库 URL 后添加一个
rewriteBatchedStatements参数;
- 示例:批量添加 1000 条数据:
# 事务处理
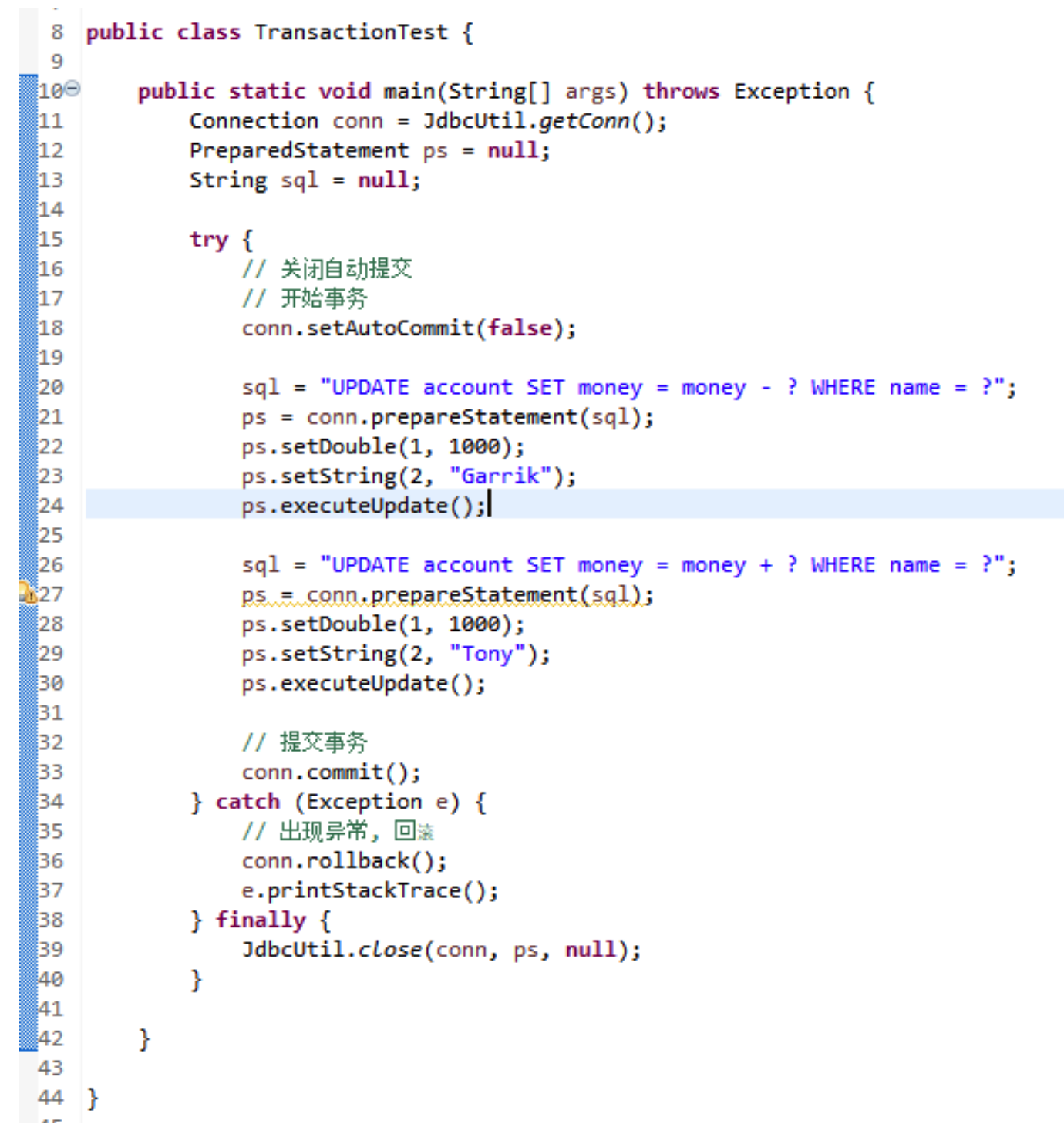
- 默认状态下,事务是自动提交的;
- 需要设置为手动提交;
- 处理事务过程:
- 关闭自动提交:
conn.setAutoCommit(false); - 提交事务:
conn.commit(); - 出现异常,进行回滚:
conn.rollback();- 把所有的事务操作用
try/catch包裹起来; - 在
catch中监听异常,调用rollback()方法; - 在
finally中断开连接,释放资源;
- 把所有的事务操作用
- 关闭自动提交:
# 二进制数据
- 图片,音频,视频在 MySQL 中用 BLOB(二进制流)类型储存;
- 但是真实开发中,一般不会存储二进制文件;
- 通常把文件存储的路径保存在数据库,通过路径去获取文件;
- BLOB 类型:
- TINYBLOB:255 字节
- BLOB:65535 字节
- MEDIUMBLOB:16M
- LONGBLOG:4G
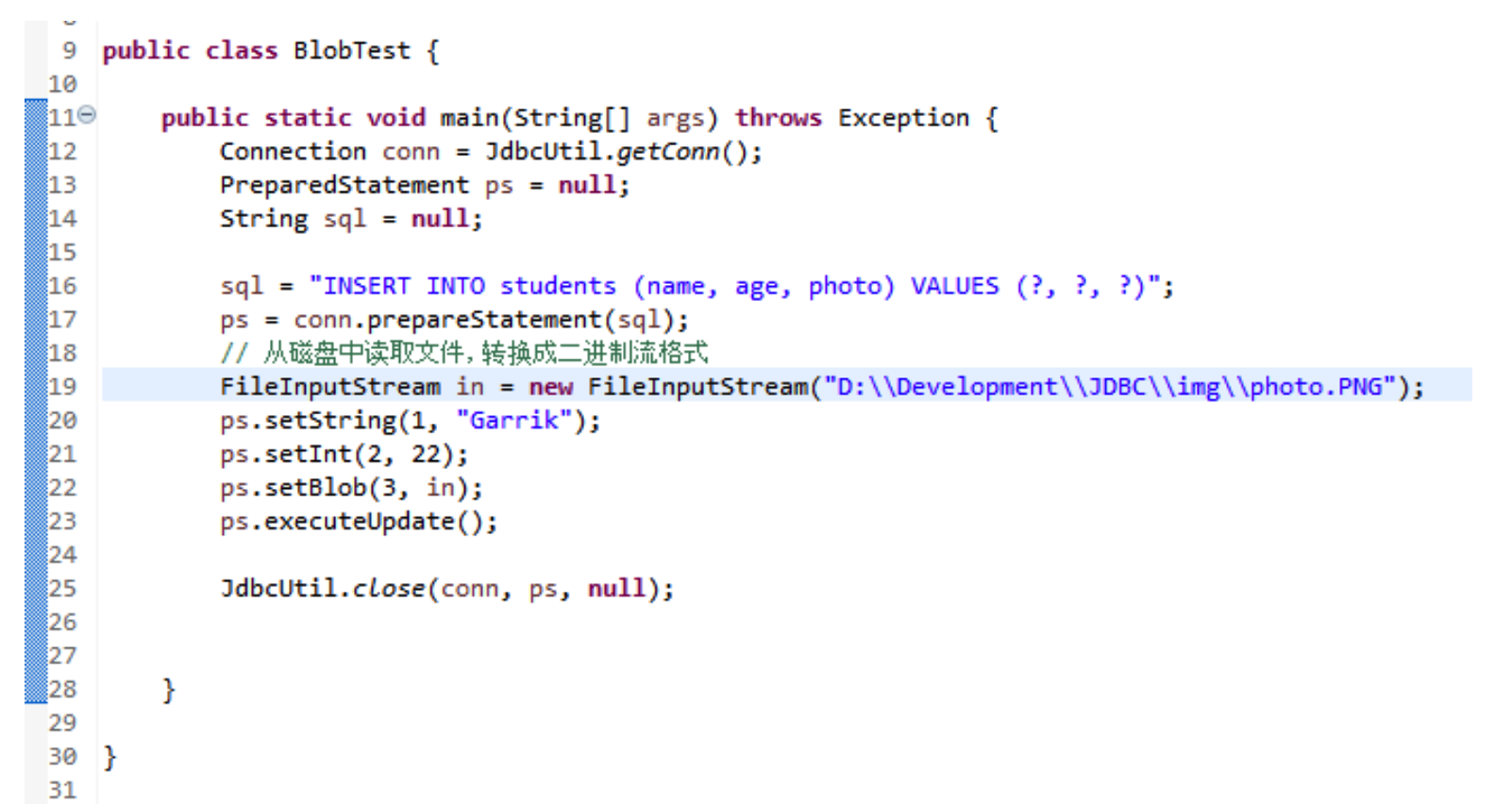
# 存储图片到数据库
- 先在表中创建出一个存放图片的字段:

- 通过 FileInputStream 类来读取磁盘内文件:
# 读取图片从数据库
- 通过
ResultSet对象的getBlob方法获取二进制数据,返回值为Blob对象; - 通过
Blob对象的getBinaryStream()方法来获取图片的二进制流,返回值为 InputStream 对象; - 通过
Files.copy把二进制流,复制到磁盘中;

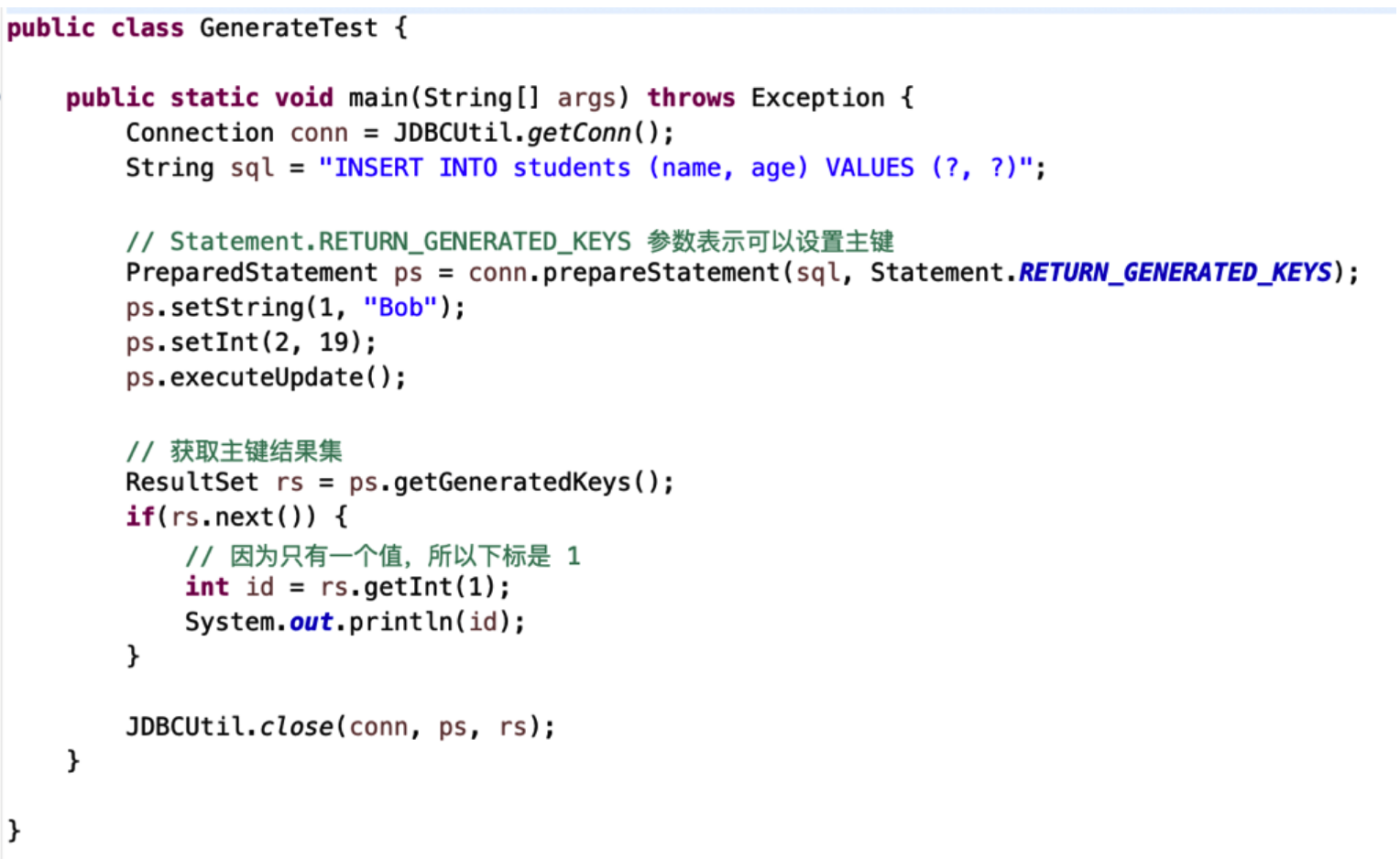
# 获取自动生成的主键
- 在设计表时,有时会设置自动生成的主键;
- 在插入数据时,有时我们想要知道生成的主键是什么;
- 需求场景示例:
- 用户注册时,第一步只需要填写用户名,密码;
- 注册成功后,需要跳转到个人信息完善页面,这时需要用到主键的值;
- 获取方法:
- 创建语句时,传入参数
Statement.RETURN_GENERATED_KEYS表示可以获取主键; - 通过语句对象的
getGeneratedKeys()方法获得主键;
- 创建语句时,传入参数
# 连接池
# 连接池介绍
- 没有连接池:
- 每一次执行 CRUD 操作使用数据库的时候,都要创建一个数据库连接对象;
- 每一次向数据库建立连接的时候,都要讲 Connection 加载到内存中;
- 当操作执行完,还要断开连接,这会很消耗资源和时间;
- 数据库资源没有很好地得到重复利用;
- 当几百几千人同时访问数据库时,资源消耗会让服务器崩溃;
- 连接池是什么:
- 池:保存对象的容器;
- 连接池:保存数据库连接对象的容器;
- 作用:
- 初始化时创建一定数量的对象,需要时直接从池中取出一个空闲对象;
- 用完后并不直接释放掉,而是再放到对象池中,以方便一下次对象请求可以直接复用;
- 池技术优势是,可以消除对象创建所带来的延迟,从而提高系统的性能;
- 数据库连接池:
- 基本思想就是为数据库连接建立一个“缓冲池”;
- 预先在缓冲池中放一定数量的连接;
- 当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕再放回去;
- 可以通过设置连接池最大连接数来防止系统无尽地与数据库连接;
- 可以通过连接池的管理机制监控数据库连接的数量,使用情况;
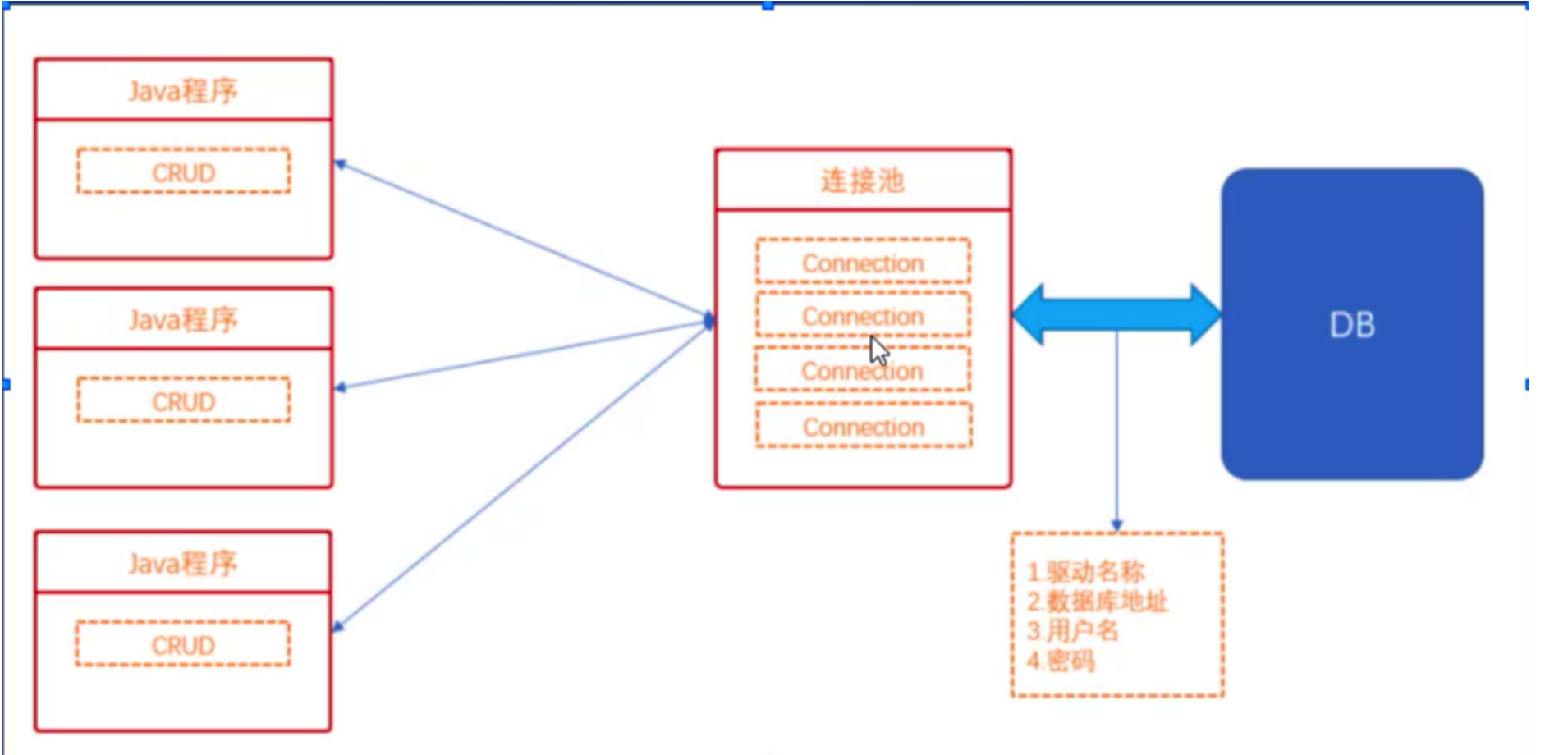
- 连接池中的属性:
- 连接数据库的 4 要素:驱动名称,数据库地址,用户名,密码;
- 初始化连接数:初始化时,连接池当中创建多少个 Connection 对象;
- 最大连接数:连接池当中最多存储多少个 Connection 对象;
- 最小连接数:连接池当中最少存储多少个 Connection 对象;
- 最大空闲空间:一个被获取的连接对象,在指定时间内没有任何操作,就会被自动释放;
- 最大等待时间:在指定时间内,尝试获取连接,如果超出时间,则提示获取失败;
# 使用数据池
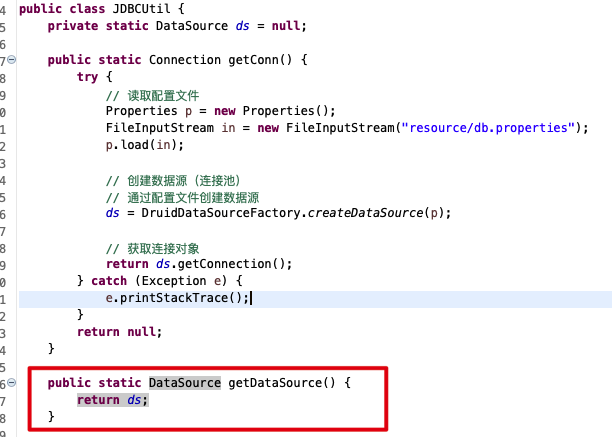
- 连接池使用
javax.sql.DataSource接口来表示连接池; - DataSource 和 JDBC 一样,Java 只提供一个接口,具体实现由第三方提供;
- 常见连接池:
- DBCP:Spring 推荐, Tomcat 的数据源使用;
- Druid:阿里巴巴实现的连接池,号称是世界上最好的(公司就用这个);
- DataSource 数据源和连接池 Connection Pool 是同一个东西,只是叫法不同;
- 学习连接池主要是学习如何创建 DataSource 对象,再从中获取 Connection 对象;
- 获得 Connection 对象后,其他操作都和以前一样;
- 不同的第三方连接池,只是在创建 DataSource 这步上不同;
# 使用 DBCP
- 导入 jar 包:
- commons-dbcp.ja;
- commons-pool.jar;
- 别忘了 build path;
- 在项目中使用连接池来获取连接:

- 配置文件
- 配置文件是以 .properties 为扩展名的文件;
- 在上面代码中,我们把连接地址,用户名,密码都写在了代码中;
- 不便于后期的维护;
- 配置文件的书写:
- 创建文件后缀 properties;
- 不需要加引号和空格:

- 在 Java 中使用配置文件:
- 将项目目录中创建 Resource Folder;
- 把配置文件放进去;
- 然后如下图使用:

- 改写 DBCP:
- 直接向
BasicDataSourceFactory.createDataSource()方法传入配置对象,自动创建你数据源; - 需要注意,配置文件的 Key 如下,不能瞎写,具体可以参考属性配置文档;

- 直接向
# 使用 Druid
- DruidDataSource 是兼容 DBCP 的,从 DBCP 迁移到 DruidDataSource,只需修改数据源的实现类就可以;

# 代码重构
# 存在的问题
- 在 DAO 中执行的保存,更新,删除,这些 DML 操作有太多重复代码;
- 重构代码原则:
- 同一个类中:
- 发现多个方法有相同的代码;
- 则把他们抽象成一个方法;
- 不同的地方通过参数传递进去;
- 不同类中:
- 不同类当中共同的代码抽象到一个新类中;
- 不同的类共享新类的内容;
- 同一个类中:
# 抽取 DML 方法
- 根据现有情况,可以将保存,更新,删除等 DML 操作抽象成一个方法;
- 传入两个参数:
- SQL 语句 / 语句模板;
- 可变参数,设置语句的参数值;
- 返回值:int 类型,受影响的行数;

- 修改 save,delete,update 方法:

# 抽象出 CRUB 模板类
- 在上一步我们抽出了通用的 DML 执行方法;
- 可以想到,这个方法也会在别的 DAO 实现类中使用;
- 那么我们可以再把这个方法抽象到一个 CRUB 模板类;
- 注意方法类型是
static;

# 抽取 DQL 方法
- 同理,DQL 查询方法也可以抽取到 CRUB 模板类中:

- 之后改写
get,getAll方法: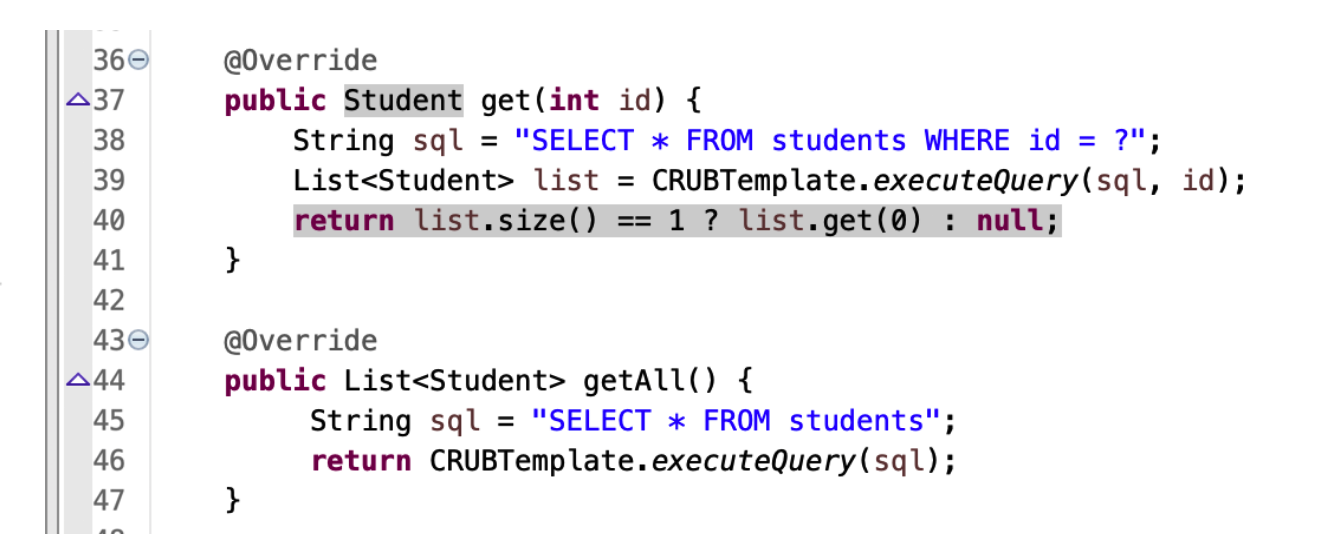
- 存在问题:
- 上面
executeQuery方法中, 类型写死了; - 原因是不知道会去处理什么类型的对象;
- 上面
# 结果集处理器
- 解决方法:
- 定义一个处理结果集接口;

- 在具体的 DAO 中实现接口;

- 创建 “接口实现对象”并传给查询处理方法:

- 在查询方法中调用处理结果集方法:
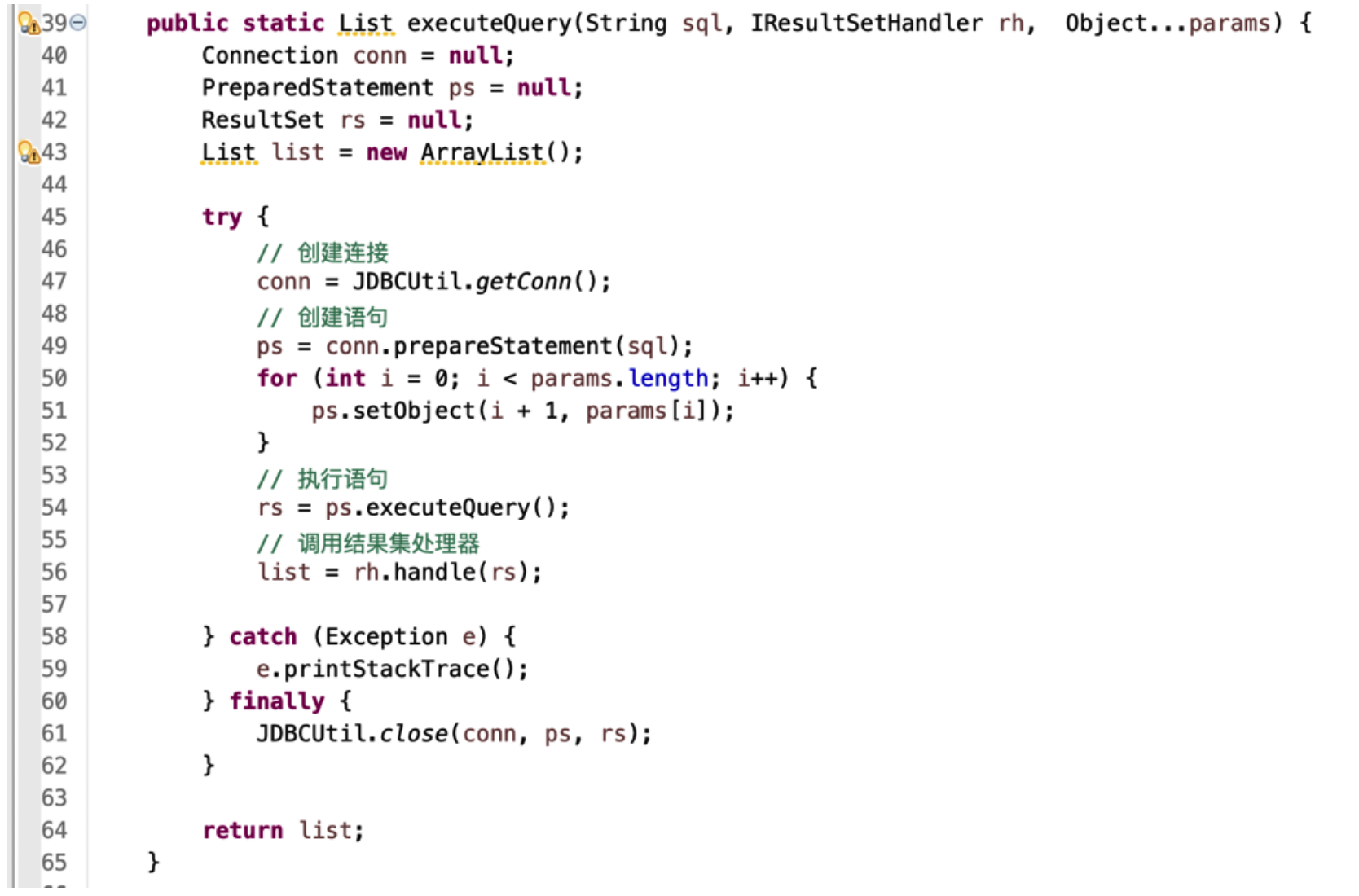
- 定义一个处理结果集接口;
# 使用泛型
- 上面结果集处理器,返回 List 类型对象;
- 但是我们希望可以自己设定要返回的类型;
- 我们还可以用“泛型”来改写上面代码;
- 声明接口时定义返回类型为 T:

- 在实现类中去决定具体返回类型:

- 查询方法返回类型也定为 T,具体类型根据参数来决定:
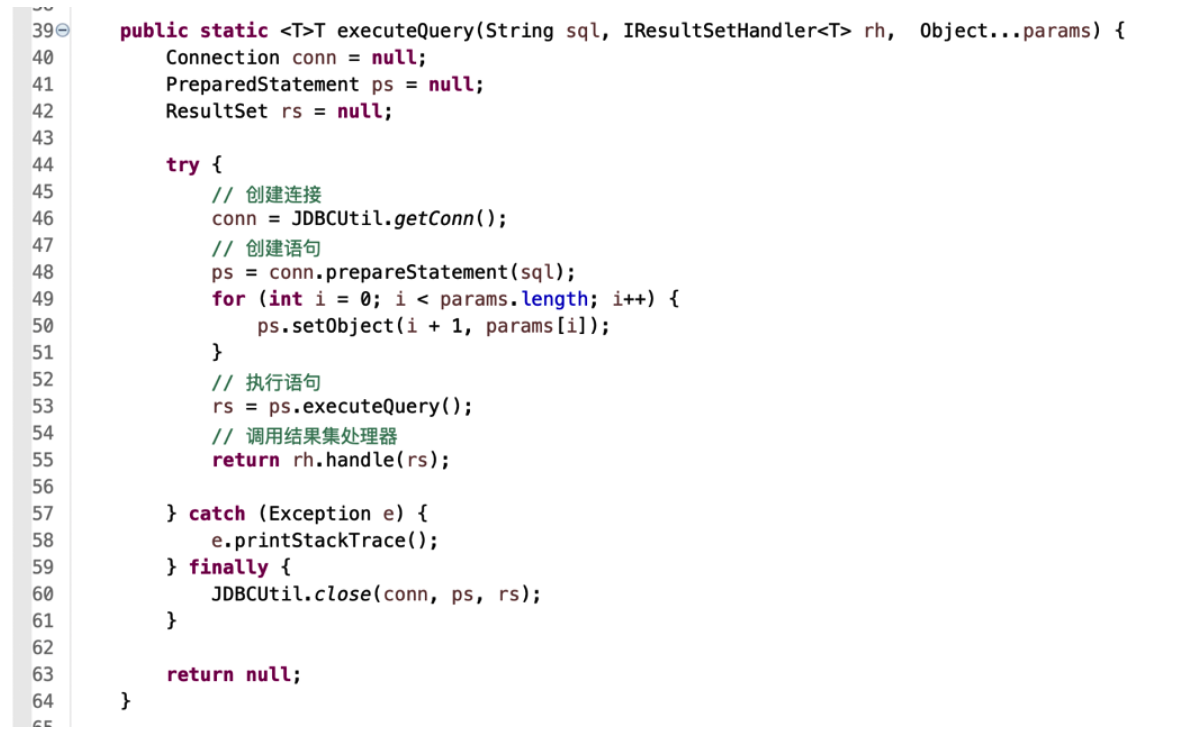
- 在创建结果集处理器时指定类型:

# 内省
# Class 类型介绍
- Class 类是一个关于类的类型;
- 通过 Class 类我们可以获得关于一个类的相关信息;
- 通过一个类的
.class属性可以获得它对应的 Class 对象; - Class 对象执行
newInstance()方法,可以通过字节码创建对应的对象;

# 什么是内省
- 内省用来查看和操作,符合 JavaBean 规范(属性有 getter 和 setter)的类的属性;
- 通过 Introspector 类来进行内省操作;
Introspector.getBeanInfo(A.class, B.class)- 获取指定类的信息;
- 第一个参数指定要获取信息的类,此方法还会获取其父类的信息;
- 第二个参数指定到哪个父类为止,不再继续往上获取;
- 🌰 假如,A 类,继承 B 类。上面 👆 这种调用方法,就只会获取 A 类自己定义的信息,不会管 B 类;
- 返回值为 BeanInfo 对象;
- BeanInfo 类型执行
getPropertyDescriptors方法,返回指定类的所有属性信息,返回类型是PropertyDescriptor数组; - 获取属性名:
pd.getName() - 获取 get 方法:
pd.getReadMethod() - 获取 set 方法:
pd.getWriteMethod() - 动态调用方法:
方法名.invode(对象名称, 值)

# 用内省重构代码

- 之前的结果集处理器仍旧是可以继续重构的;
- 该类专门将结果集中的数据封装成一个 Student 对象;
- 如果我们有多个 domain,就需要多个结果集处理器;
- 但其实,这些结果集处理器做的都是同一件事:
- 把结果集中的每一个数据封装成对象;
- 设置对象的属性;
- 通过内省就可以抽象出一个通用的结果集处理器;
规定:
- 数据表中的列名必须和类的属性名一致;
- 规定数据表中的数据类型必须和类的属性的数据类型匹配;
编写:

# 封装成 jar 包
下面看一下如何把刚刚写的通用结果集处理器,打包成一个 jar 包。
exports -> JAR file

选择要导出的文件 -> 然后选择要导出的位置 -> Finish

# DBUtils
# 什么是 DBUtils
- DBUtils 是 Apache 编写的数据库操作工具;
- 封装了对 JDBC 的操作,简化了 JDBC 操作;
# 常用方法
QueryRunnder(DataSorce ds):创建连接;update(String sql, Object...obj):执行更新;query(String sql, ResultSetHandler<T> rsh, Object...params):执行查询;query(sql, new BeanHandler<Student>(Student.class), params):把查询到结果封装成一个指定对象;query(sql, new BeanListHandler<Student>(Student.class)):把查询结果封装成一个指定对象集合;qr.query(sql, new ScalarHandler()):查询单个值,返回一个 Long 类型qr.query(sql, new MapListHandler()):把查询结果封装成一个 Map 集合query(sql, new ColumnListHandler("列名")):查询指定的列
# 使用 DBUtils 改写代码
引入 jar 包,并且编译一下(Build Path)。

我们先改 save 方法。同理其他的 DML 操作也可以用下面的改法。
在 StudentDaoImpl 中,传入数据源到 QueryRunner,创建连接。
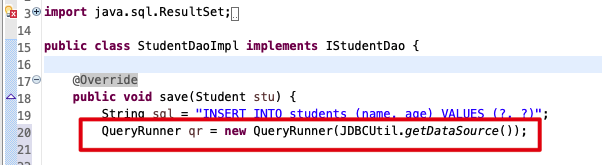
通过 updata 方法来进行操作:

下面来改 DQL 操作。
通过 query 方法来进行查询:
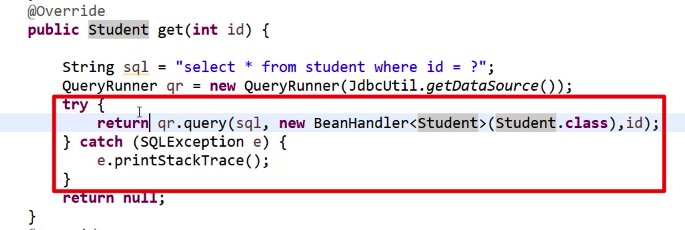
如果查询结果是多个的话,要注意 query 方法的参数:
